The best open source software of 2020
InfoWorld picks the year’s best open source software for software development, cloud computing, data analytics, and machine learning



























InfoWorld’s 2020 Bossie Award winners
Like a benevolent Borg, open source sweeps across the software universe year after year, bringing innovation to everything it touches. And year after year, InfoWorld’s Best of Open Source Awards, aka the Bossies, mark the progress. Among the 25 winners of our 2020 Bossies, you’ll find the usual rich array of leading-edge projects—tools for building better web applications, more accurate machine learning models, crisper data visualizations, more flexible workflows, faster and more scalable databases and analytics, and much more. Read on to discover the best that modern open source has to offer.
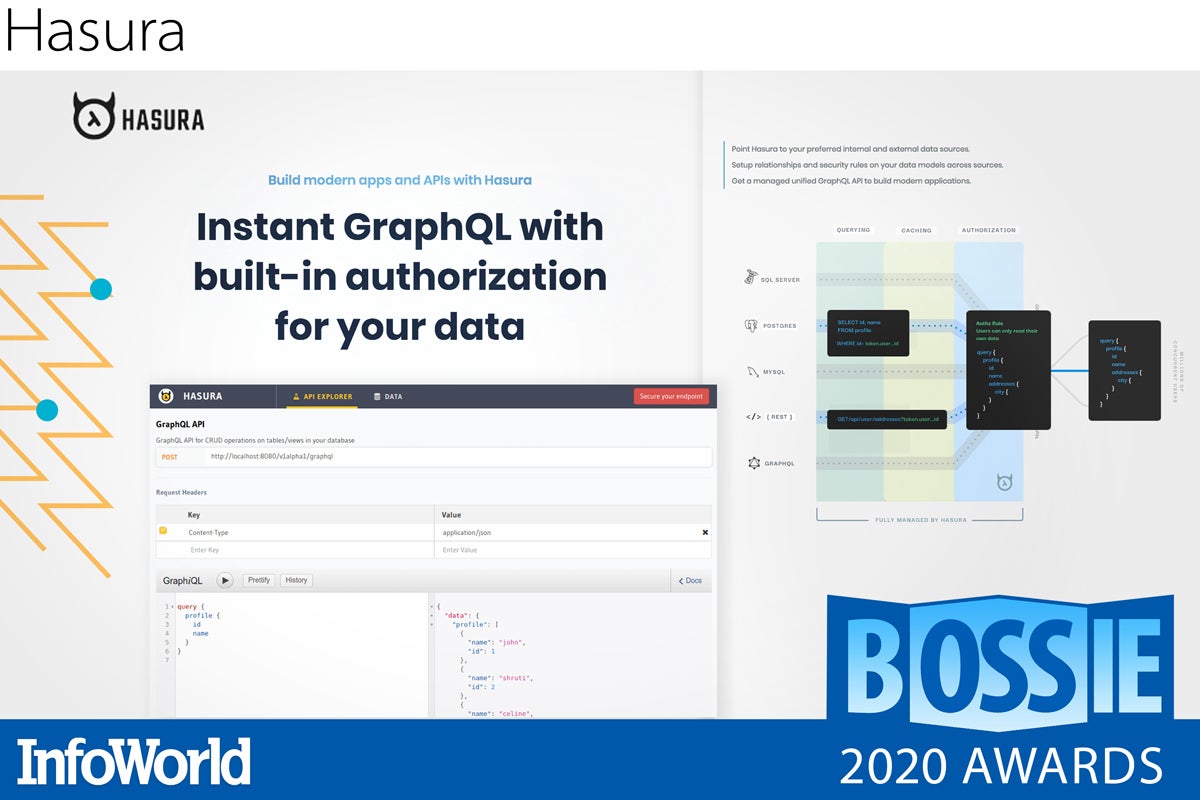
Hasura
Modern applications are written with GraphQL. Everyone has heard the story about not sending 1,000 REST calls and instead optimizing with GraphQL, but Hasura extends that story with actual security, subscriptions, and live queries. It provides useful graphical tools for constructing, running, and configuring your GraphQL queries.
Moreover Hasura was built with PostgreSQL and PostgreSQL-compatible databases in mind (and also now supports MySQL). If the JavaScript/REST API era belonged to MongoDB and NoSQL, the GraphQL era belongs to PostgreSQL and distributed SQL. Hasura is one of the best open source GraphQL stacks to emerge from these modern application trends.
— Andrew C. Oliver

Prisma
There are many ORMs for TypeScript applications, but Prisma is among the most developer-friendly with features like autocompletion for SQL queries. Well, technically, the developers don’t consider Prisma an ORM. It is designed with API development in mind including gRPC and GraphQL.
Prisma works out of the box with PostgreSQL, MySQL, and SQLite databases. There is a Visual Studio Code extension and really everything you’d expect from a modern database API and mapping solution. Developers who want to think in terms of objects and queries, and have type safety and all of the fixings, may want to consider Prisma.
— Andrew C. Oliver
Jekyll
A long time ago, the web was filled with HTML pages stored in separate files. Then someone invented dynamic web pages and everyone became obsessed with adding flexibility and customizability to every URL. Fixed, unchanging HTML was out. Instead we poured all of the information into sophisticated, database-backed applications that would craft individual packets of data for each user—even if the information didn’t change.
Then some smart programmers realized that redoing all of this work is silly. Jekyll is one of the best new static site generators that take our information and package it up as a collection of individual web pages that can be pushed out to content delivery networks. No databases. No faux customization. Jekyll just takes your text, fits it into a template, and it’s done. You get all of the flexibility that comes with good templating mixed with the speed of storing static files on the edges.
— Peter Wayner

Gatsby
Anyone who fell in love with the idea of progressive web applications and embraced the sophisticated multi-panel approach of React was still stuck with plenty of work to create anything. Gatsby is a framework that sits on top of React and taps a world of plug-ins for embedding big things like Shopify stores, small things like JSON data feeds, and more than 2,000 other modules for tasks in between.
One of the Gatsby project’s main goals is to deliver fast web pages, and it pursues that goal by leveraging good caching, static page generation, and edge-based CDN data sources. The project likes to claim that this careful attention will produce static web pages that are “2.5x faster than other static frameworks.” By any measure, Gatsby is both elegant and fast.
— Peter Wayner

Drupal
The Drupal philosophy is not new. Dries Buytaert released the first version as open source in 2001 to help developers spin up websites filled with data-rich nodes composed of multiple fields. It’s a rich framework made richer for embracing tabular data. Now it seems like it’s all new again because the code has been spruced up, refactored, and rewritten. Drupal 9 dropped in June and it is a thoroughly modern PHP web application built upon PHP tools like Composer, Symphony, and Twig.
The project is riding an acceleration wave carrying all PHP tools like WordPress and Joomla. The language is getting faster as PHP developers embrace some of the Just-In-Time compiler techniques behind the success of Java and Node.js. The module ecology is also an impressive collection of mini open source projects that make it relatively easy to add features large and small to the core. It’s not just one open source project, but a constellation of evolving code.
— Peter Wayner

Vulkan
Vulkan is a new generation graphics and compute API that provides highly efficient, cross-platform access to modern GPUs used in a wide variety of devices from PCs and consoles to mobile phones and embedded platforms. The Vulkan API supports game, mobile, and workstation development. It is the successor to the OpenGL standard.
Compared to OpenGL, which is essentially a graphics API, Vulkan is more of a GPU API. There are Vulkan drivers from AMD, Arm, Broadcom, Imagination, Intel, Nvidia, Qualcomm, and VeriSilicon, and Vulkan SDKs for Windows, Linux, macOS/iOS, and Android. Most prominent game engines now include Vulkan support as well.
— Martin Heller

Redis
A powerful blend of speed, resilience, scalability, and flexibility, Redis is a NoSQL in-memory data structure store that can function as a database, cache, and message broker. Redis has built-in replication, Lua scripting, LRU eviction, transactions, and different levels of on-disk persistence. It provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster. Redis typically provides database latency under one millisecond.
The core Redis data model is key-value, but many kinds of values are supported: Strings, Lists, Sets, Sorted Sets, Hashes, Streams, HyperLogLogs, and Bitmaps. Redis also supports geospatial indexes with radius queries and streams. Redis 6 added several major features, most importantly threaded I/O, which accounts for a 2x improvement in speed. The addition of access control lists (ACLs) gives Redis 6 the concept of users, and allows developers to write more secure code.
— Martin Heller
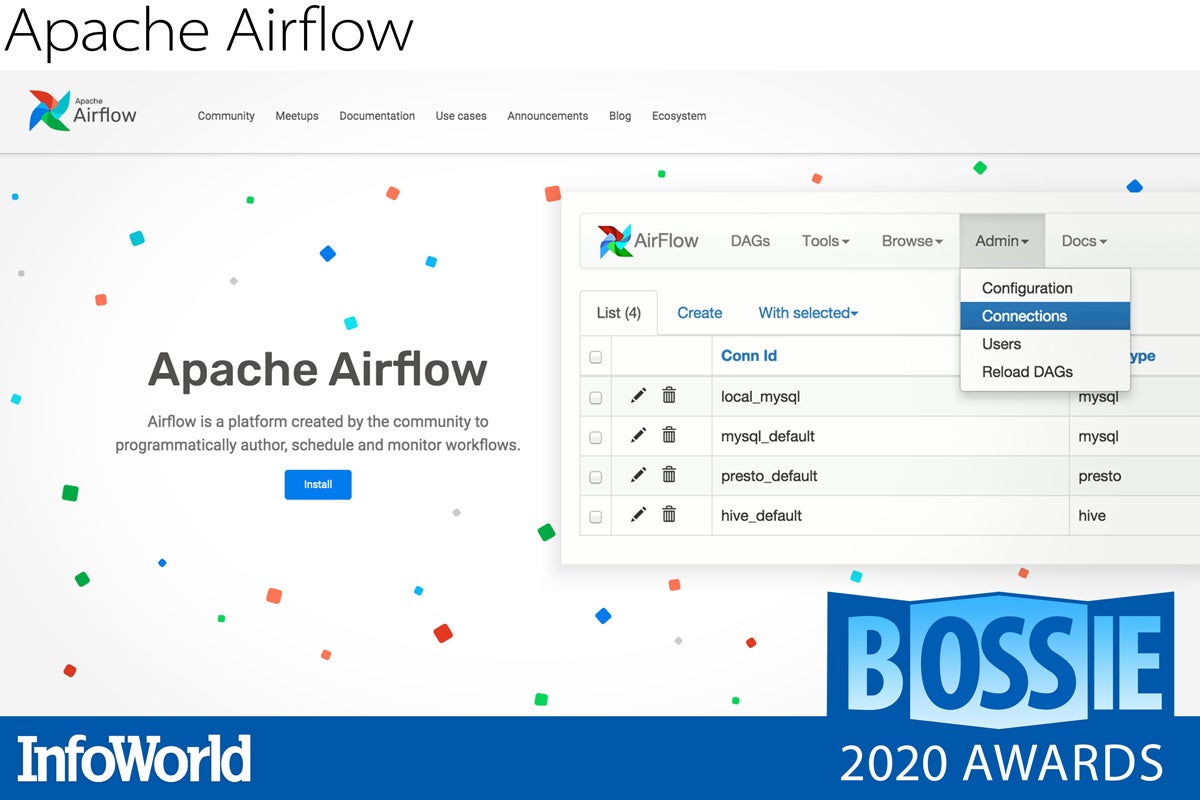
Apache Airflow
To paraphrase Forrest Gump, stuff happens, but sometimes stuff has to happen in a certain order and trigger other stuff to happen afterwards. In other words, you need a workflow. If you are a Python developer, and Python-driven workflows is what you need, then Apache Airflow, originally created by Airbnb, might just be your huckleberry.
Airflow allows you to construct workflows as Directed Acyclic Graphs (DAGs). It even allows you to construct dynamic workflows. Unlike other tools that require you to translate your workflows into XML or other metadata languages, Airflow follows the principle of “configuration as code,” allowing you to write it all in Python scripts.
— Andrew C. Oliver
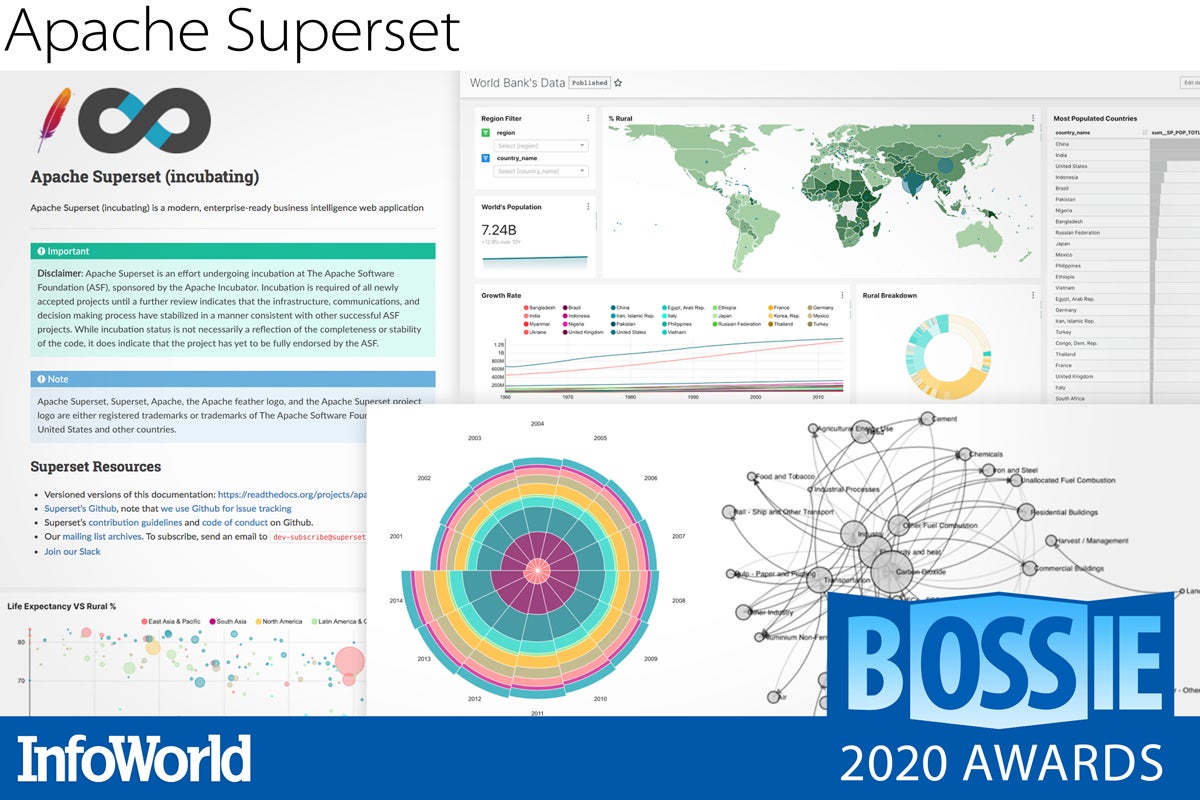
Apache Superset
Have you ever priced Tableau and felt your heart skip a beat? I mean, you just want a dashboard yet somehow this costs more than some databases. More to the point, have you ever wanted a visualization that Tableau just couldn’t do or do very well? Enter Apache Superset, yet another contribution by Airbnb.
Combining a SQL IDE, a data explorer, a drag-and-drop dashboard editor, and plug-ins for building custom visualizations, Superset is a visualization toolkit that can make dashboards from many relational and non-relational databases, and it can connect to Apache Drill and Apache Druid. Best of all, Superset is cloud-native, Dockerized, scale-out, and all of that modern jazz.
— Andrew C. Oliver

JanusGraph
Graph databases have always given me a bit of indigestion. Of course there are graph queries and graph problems. But is a graph really the right way to store the data? The Neo4j crowd claims it’s so efficient that you don’t need modern distributed storage and sharding and partitioning and all of that good stuff. However, if you’re running a really large data set, you quickly find out that maybe graph analysis is efficient but a storage graph isn’t.
JanusGraph lets you run Gremlin graph queries but store the actual data in a distributed database such as Cassandra, Yugabyte, ScyllaDB, HBase, or Google’s Bigtable. Like Neo4j and other “native graph” databases, JanusGraph is transactional and indexed and appropriate for both graph-shaped OLTP usage and OLAP analytical usage. If you’re doing really big graph stuff, JanusGraph is probably the right way to go.
— Andrew C. Oliver
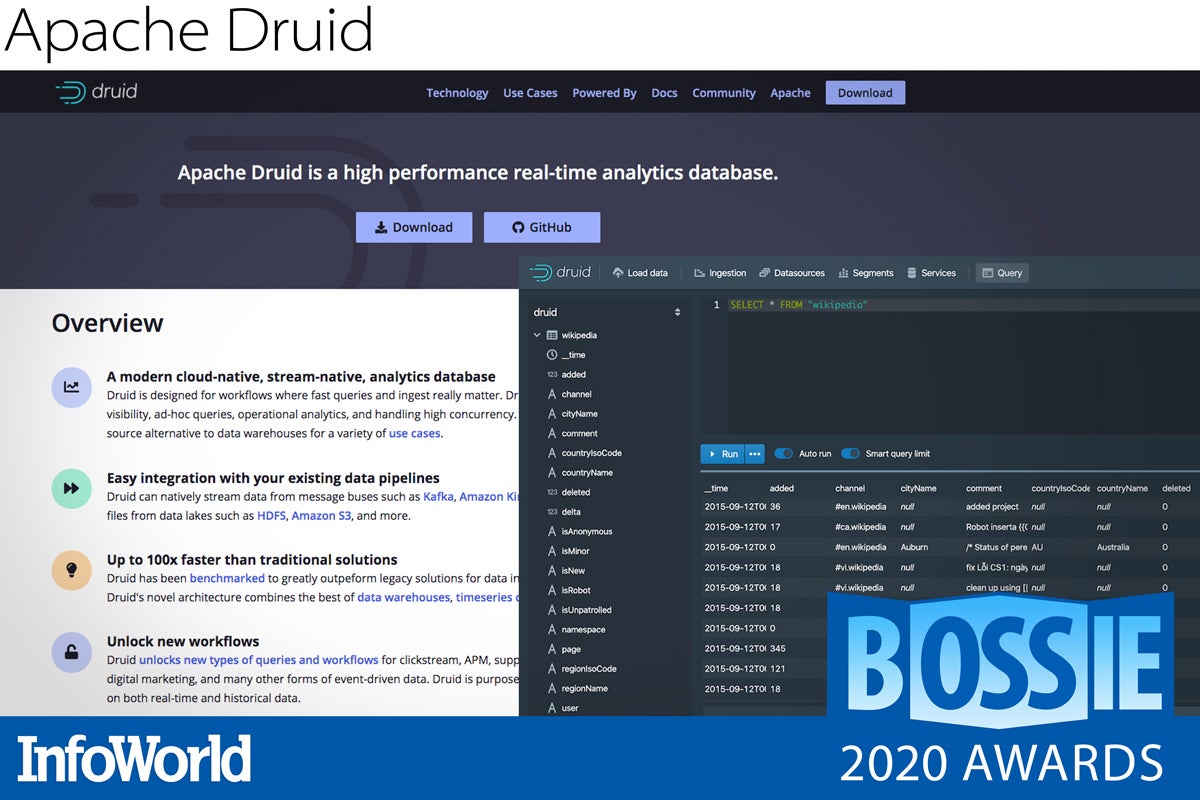
Apache Druid
The world of analytics is changing. Where we used to batch load everything into a giant MPP system and wait for long-running queries, now a large subset of analytics is done in real-time as events happen and get streamed. After all, what happened yesterday or a week ago might as well have been a lifetime ago.
Apache Druid is a distributed column store database that provides both low-latency ingest of data and low-latency queries on top. This is a BI or OLAP style database with out-of-the-box integration with message buses like Apache Kafka and data sources like HDFS. Part data warehouse and part search system, Druid is capable of handling massive amounts of data and designed for the cloud era.
— Andrew C. Oliver
Apache Arrow
With the recent 1.0 release, Apache Arrow has gone from strength to strength, bringing its in-memory columnar format to multiple languages such as C/C++, Go, Java/JVM, Python, JavaScript, Matlab, R, Ruby, and Rust. While Arrow is not something that you’ll explicitly go out and download, you’ll find it at the core of many of the big data and machine learning projects you probably use—Apache Spark, Dask, Amazon Athena, and TensorFlow to mention just a few.
The Arrow project is now turning its attention to communication across machines as well as in-memory. Apache Arrow Flight is its new, general-purpose, client-server framework designed to simplify high performance transport of large data sets over network interfaces. Expect to find Flight powering cluster data transfers in some of your distributed computing applications in the year to come.
— Ian Pointer
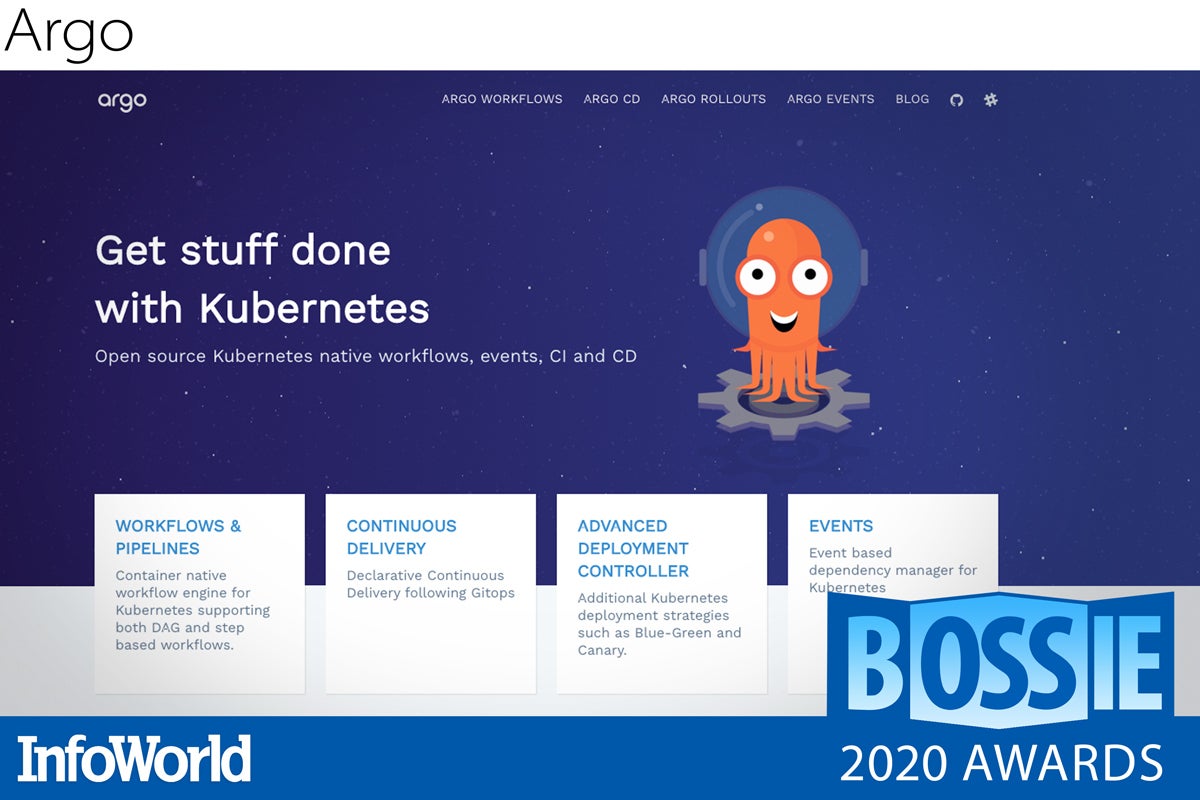
Argo
There are many open source workflow engines out there, such as Apache Oozie and Apache Airflow, but unlike those stalwarts, Argo has been designed from the ground up to work with Kubernetes. Originally developed by Intuit, Argo fits right in with your deployments and can directly interact with Kubernetes resources, as well as Docker-led custom steps.
Over the past year, Argo has added new features for templating and resiliency, and now is probably one of the best ways to handle workflows within your clusters. The Argo project includes more features, allowing workflows to be triggered by events and even a CI/CD system, while the well-thought-out modularity means you can use as much or as little of the Argo ecosystem as you desire.
— Ian Pointer
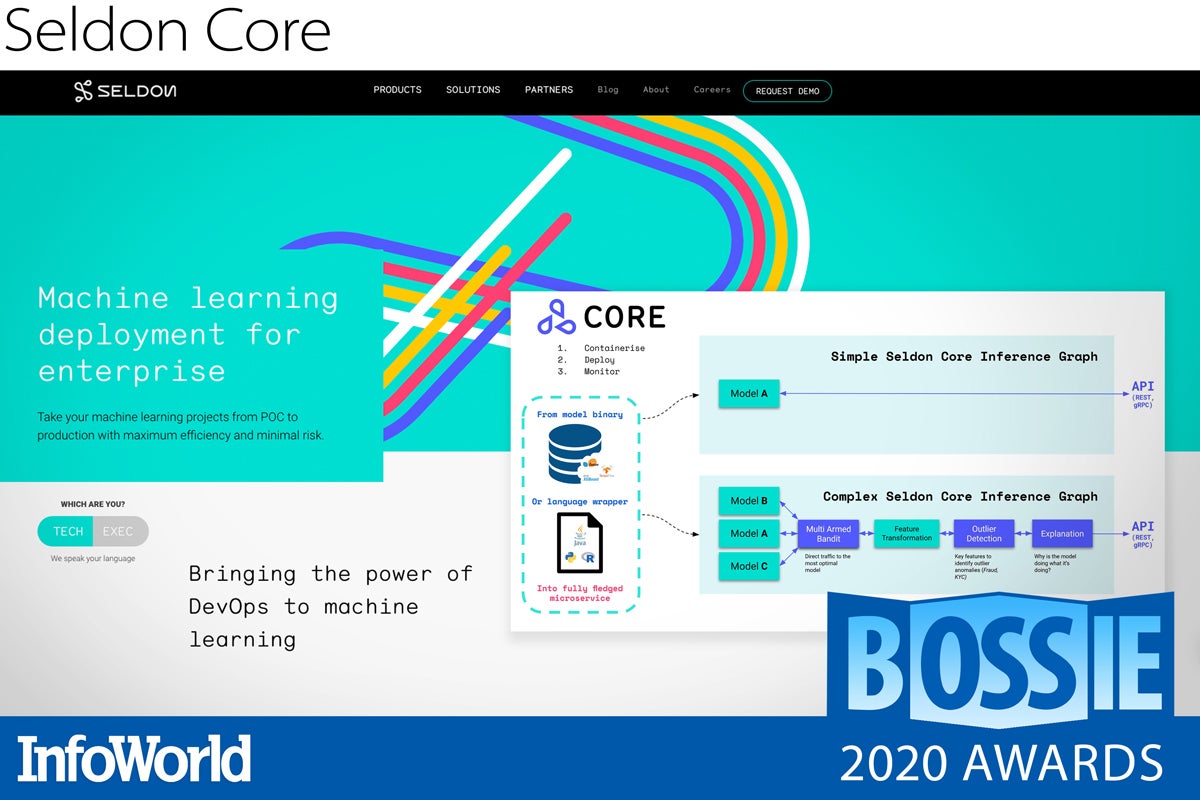
Seldon Core
Creating a good machine learning model is hard, but that’s only the first part of the story. Deploying, monitoring, and maintaining is likely to be even more important to the success of your machine learning strategy in the long run.
A toolkit for deploying models on Kubernetes, Seldon Core offers a boatload of functionality to help you along that journey — a multilingual API that ensures that a model written in Java can be deployed with a PyTorch model in exactly the same way, the ability to construct arbitrary graphs of different models, support for routing requests to A/B or multi-armed bandit experiments, and integration with Prometheus for those all-important metrics.
And it’s all built upon Kubernetes and standard components like Istio or Ambassador. You can expect to find Seldon Core at the heart of many companies’ model deployment strategies for years to come.
— Ian Pointer
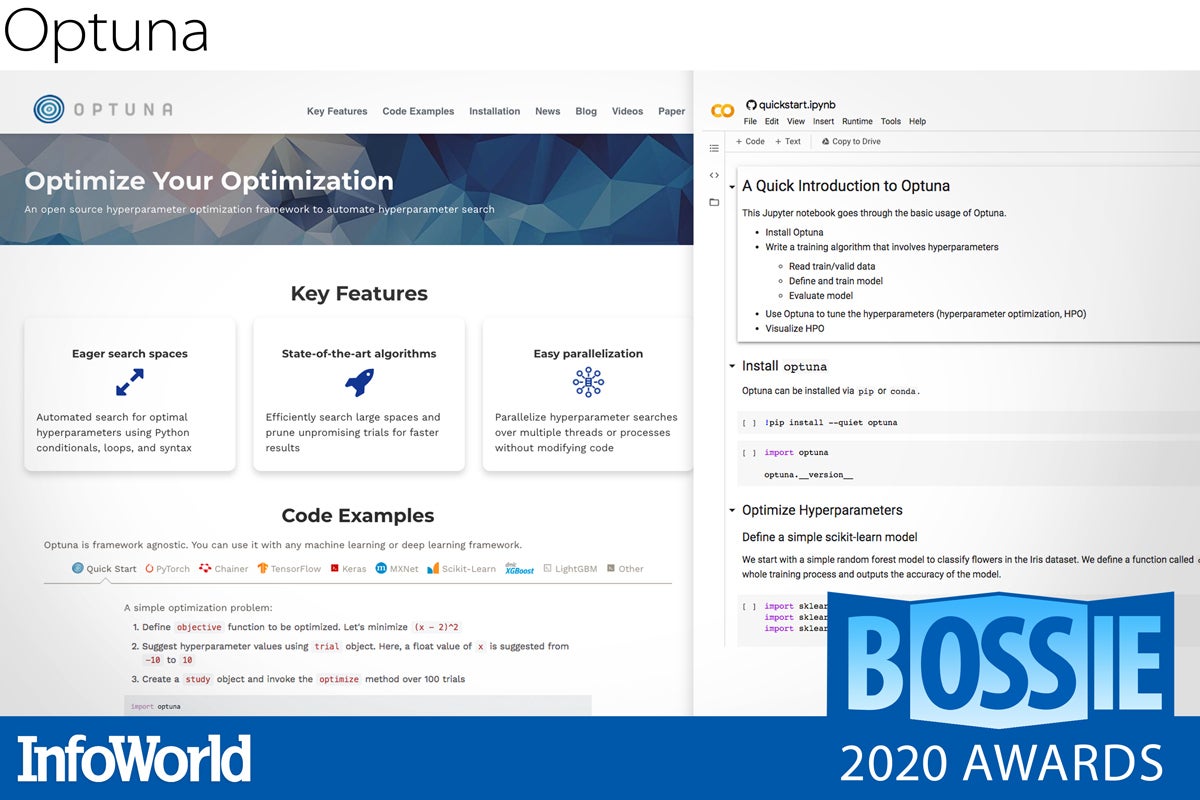
Optuna
If you ask a machine learning expert for advice on hyperparameter tuning, they will likely point you in the direction of Hyperopt. But maybe you should give Preferred Networks’ Optuna a whirl instead. The new Optuna 2.0 release comes complete with out-of-the-box integration with TensorFlow, Scikit-learn, Apache MXNet, and PyTorch, with further specific framework support for Keras, PyTorch Lightning, PyTorch Ignite, and Fastai.
Offering faster samplers and hyperband pruning, Optuna can significantly reduce the time required to discover performant parameter optima, and you can get all of this with just a few lines of code. In addition, the framework is incredibly simple to extend for scenarios that step outside of the supplied integrations.
— Ian Pointer

K9s
K9s is the SRE’s best friend, and you’ll often find it hidden away in one of their terminals. A Swiss Army knife of monitoring Kubernetes clusters, K9s wraps all of that kubectl functionality in a constantly updating fashion. You can see all of your pods at a glance, or drill down into descriptions and logs with a single keystroke.
Not only that, but K9s allows you to edit resources, shell into pods, and even run benchmarks—all from the same command-line interface. Paired with an extensive plug-in system and skin support, it’s the hacker-friendly interface to Kubernetes that you’ll soon wonder how you managed without.
— Ian Pointer

KubeDirector
KubeDirector is an open source project designed to make it easy to run stateful applications on Kubernetes clusters. Normally this requires writing custom operators, a task requiring high levels of expertise in both the application and Kubernetes.
KubeDirector is implemented as a Kubernetes operator for long-lived, watchful orchestration of stateful applications. At its core it models a domain of applications, allowing the user to specify service endpoints, persistent directories, and anything that must remain constant between instantiations.
There is an example application catalog that includes Apache Kafka, Apache Spark, TensorFlow, Cloudera, and Cassandra. If you have a Kubernetes cluster available, you can get started with any of these applications in just a few minutes.
— Steven Nuñez

Bottlerocket
A Linux derivative purpose-built to run containers on large-scale Kubernetes clusters, Bottlerocket is more of a software appliance than an OS. Management is accomplished with a REST API, a command-line client, or a web console. Updates are managed with a Kubernetes operator in a single step, using the “two partition pattern,” and rolled back in case of error. Security is enhanced by presenting a minimal attack surface and enforcing inter-container isolation with cgroups, kernal namespaces, and eBPF. SELinux is enabled by default.
Although designed for running in Amazon EKS, Bottlerocket will also run on premises. The source code is on GitHub and the OS is easily buildable. Core components are written in Rust, and Amazon makes it easy to add your own operators or control containers. Delivering high performance, based on standard Linux, and supported by AWS, Bottlerocket is a compelling choice for both AWS devotees and customers implementing a multicloud strategy.
— Steven Nuñez

SPIFFE
SPIFFE (Secure Production Identity Framework For Everyone) is a specification for “cloud native security,” where cloud native is defined as an environment where hosts and processes are created and destroyed frequently. SPIFFE solves the identity problem inherent in large container clusters: how to identify a service, issue the service credentials, and verify those credentials with providers.
Within a single cloud environment, Kerberos and OAuth work nicely for identity management, but things get a bit tricky with true hybrid and multicloud setups. To solve this problem SPIFFE binds identities to workload entities instead of specific hosts. This means that as containers come and go, they can maintain the same identity.
Additionally, SPIFFE assumes a zero-trust network and requires neither keys nor passwords to establish identity. This prevents leakage of secrets because authentication information doesn’t need to be injected into the system at any point. SPIFFE can work with existing identity providers like OAuth.
— Steven Nuñez
Lem
There have been attempts to modernize Emacs, the 40-year-old standby of “hard core” programmers, but all are fundamentally limited by the underlying engine: Emacs Lisp. Lisp is a great language for an editor, and was the basis for Zmacs, the superb editor of the Lisp Machine, but Emacs Lisp missed out on the millions of DARPA dollars spent on the Common Lisp ANSI specification process that created a language suitable for deploying military-grade applications.
Lem is a greenfield rewrite of Emacs using Common Lisp. Common Lisp gives Lem access to GUI libraries for a modern graphical experience (there’s an alpha version of an Electron GUI), seamless calls to C/C++, and access to a vast array of third-party libraries. Already there is a critical mass of contributors, financial backing, and editing modes for 28 languages. Emacs hackers will no doubt feel right at home with Lem.
— Steven Nuñez

Chapel
As data sets get larger and larger, concurrency, parallelism, and distribution become increasingly important when building predictive models, and no one does this better than the supercomputing crowd. A High Performance Computing program is a low-level programming task that might consist of C/C++ or Fortran code, some shell scripts, OpenMP/MPI, and a high level of skill to put it all together.
Chapel makes it easier by providing higher level language constructs for parallel computing that are similar to languages like Python or Matlab. All of the things that make HPC a hard nut to crack in C are handled at a higher level in Chapel—things like creating a distributed array spanning thousands of nodes, a namespace available on any node, and concurrency and parallel primitives.
HPC has always been somewhat of a niche. Partly because the need previously wasn’t there, and partly because the skills were rare. Chapel brings the possibility of running machine learning algorithms at very large scale to the general software programmer. If nothing else, there’s value for everyone in understanding the ideas and concepts that are surfaced elegantly in this language.
— Steven Nuñez

Apromore
Whether you’re trying to improve the efficiency of a longstanding business process, or rolling out a new compliance monitoring service, the first step toward success is gaining an accurate view into your IT systems. Apromore process discovery tools provide this insight by analyzing KPIs from your IT back end, ingesting BPMN activities and flows, and creating a dependency graph of your operations.
Apromore’s browser-based, visual dashboards display an animated process map of resources, activities, timestamps, and domain-specific attributes to reveal statistical and temporal insights. Easy filtering gets you the details you need. Apromore even lets you shift focus between application workflows and the human capital implementing them to identify outliers and bottlenecks.
You will need to pay up for the Enterprise Edition to gain access to the application features and BI connector plug-ins you might need. But the metrics and visual insights provided by Apromore will do wonders to inform your change impact analyses and end-to-end optimization efforts in your enterprise workflows.
— James R. Borck
Sourcegraph
Enterprise app dev projects have become too complex to be managed by IDE alone. Modern codebases and their dependencies span multiple programming languages, repositories, and geographically distributed teams, creating a challenge just to index the code, let alone search or refactor it.
With plug-ins for major IDEs and web browsers, Sourcegraph integrates into your development workflow to unify the search process. Using regular expressions and language-specific filters, you get a quick and complete picture of the entire codebase enhanced with code intelligence, comprehensive navigation, and hover tooltips that provide references and definitions right inside your browser.
Sourcegraph supercharges the dated IDE with a new class of code navigation, review, and intelligence tools previously reserved for Google and Facebook engineers. If your development team spends any amount of time searching for code, reviewing code, or wondering where code is being reused, you’ll want to explore the power of Sourcegraph.
— James R. Borck

QuestDB
High-performance time series databases are often closed-source products that not only can be costly to maintain, but also require learning proprietary query languages. Not QuestDB.
A free open source database developed for fast processing of time series data and events, QuestDB is queried using familiar SQL, along with time series extensions for temporal aggregations. And yet its Java-based query engine delivers blazingly fast response times with minimal latency.
To deliver its impressive query performance, QuestDB takes advantage of a custom storage engine, modified Google Swiss Tables, SIMD instructions, parallel execution queuing, and pipeline prefetch optimizations. Its onboard web console provides a schema explorer, a code editor for interactive queries, and some basic table and visualization tools.
QuestDB is still a work in progress. Not all queries have been optimized yet, and the SQL dialect is still being fleshed out. But when you get breakthrough time series query performance together with SQL support, who cares about a few wrinkles?
Licensed under Apache 2.0, QuestDB runs on Linux, MacOS, and Windows and makes packages available for Docker and Homebrew.
— James R. Borck

Open Policy Agent
Authorization policy enforcement is typically done manually using hard-coded rules on an ad hoc basis, essentially reinventing the wheel for every application and service. Such a brittle approach inevitably leads to fragmented policy authorization point solutions that become impossible to maintain or audit.
Open Policy Agent provides a general-purpose authorization engine that decouples policy decision-making from application-level enforcement. OPA accepts a series of JSON attributes, evaluates them against the policies and data within its purview, and responds to the application with a Yes or No decision that gets enforced by the caller.
OPA can be run as a daemon or integrated directly into your service as a library. It is an excellent fit for use cases like microservices, service meshes, API authorization, and Kubernetes admission control, but could just as easily be extended for use in SaaS delivery models, for example.
Combining flexible enforcement with a declarative policy language that simplifies policy creation, OPA returns control over a wide range of technologies back to administrators by treating policy like code that can be managed uniformly and logically across the stack—from bare metal to cloud.
— James R. Borck
Copyright © 2020 IDG Communications, Inc.

