Redis 6: A high-speed database, cache, and message broker
Redis is a powerful blend of speed, resilience, scalability, and flexibility, and Redis Enterprise takes it even further.






Contributor, InfoWorld |

-
Redis 6.0
Like many, you might think of Redis as only a cache. That point of view is out of date.
Essentially, Redis is a NoSQL in-memory data structure store that can persist on disk. It can function as a database, a cache, and a message broker. Redis has built-in replication, Lua scripting, LRU eviction, transactions, and different levels of on-disk persistence. It provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.
The core Redis data model is key-value, but many different kinds of values are supported: Strings, Lists, Sets, Sorted Sets, Hashes, Streams, HyperLogLogs, and Bitmaps. Redis also supports geospatial indexes with radius queries and streams.
To open source Redis, Redis Enterprise adds features for additional speed, reliability, and flexibility, as well as a cloud database as a service. Redis Enterprise scales linearly to hundreds of millions of operations per second, has active-active global distribution with local latency, offers Redis on Flash to support large datasets at the infrastructure cost of a disk-based database, and provides 99.999% uptime based on built-in durability and single-digit-seconds failover.
Further, Redis Enterprise extends the core Redis functionality to support any data modeling method with modules such as RediSearch, RedisGraph, RedisJSON, RedisTimeSeries, and RedisAI, and allows operations to be executed across and between modules and core. All this is provided while keeping database latency under one millisecond.
Core Redis features and use cases
What does it mean that Redis can now function as a database, cache, and message broker? And what are the use cases those roles support?
Cache is the classic function of Redis. Essentially, Redis sits in front of a disk-based database and saves queries and results; the application checks the Redis cache for stored results first, and queries the disk-based database for results not currently in the cache. Given the sub-millisecond response rate of Redis, this is usually a big win for application performance. Expiration timers and LRU (least recently used) eviction from the Redis cache help to keep the cache current and to use memory effectively.
The session store is an important part of modern web applications. It’s a convenient place to keep information about the user and her interactions with the application. In a web farm architecture, hosting the session store directly on the web server requires making the user “stick” to the same back-end server for future requests, which can limit the load balancer. Using a disk-based database for the session store removes the need to bind a session to a single web server, but introduces an additional source of latency. Using Redis (or any other fast in-memory database) as the session store often results in a low-latency, high-throughput web application architecture.
Redis can function as a message broker using three different mechanisms, and one of the important use cases for Redis as a message broker is to act as glue between microservices. Redis has a low-overhead publish/subscribe notification mechanism that facilitates fire-and-forget messages, but can’t work when the destination service is not listening. For a more persistent, Kafka-like message queue, Redis uses streams, which are time-stamp ordered key-value pairs in a single key. Redis also supports doubly-linked lists of elements stored at a single key, which are useful as a first-in/first-out (FIFO) queue. Microservices can, and often do, use Redis as a cache as well as using it as a message broker, although the cache should run in a separate instance of Redis from the message queue.
Basic replication allows Redis to scale without using the cluster technology of the Redis Enterprise version. Redis replication uses a leader-follower model (also called master-slave), which is asynchronous by default. Clients can force synchronous replication using a WAIT command, but even that doesn’t make Redis consistent across replicas.
Redis has server-side Lua scripting, allowing programmers to extend the database without writing C modules or client-side code. Basic Redis transactions allow a client to declare a sequence of commands as a non-interruptible unit, using the MULTI and EXEC commands to define and run the sequence. This is not the same as relational transactions with rollbacks.
Redis has different levels of on-disk persistence that the user can select. RDB (Redis database file) persistence takes point-in-time snapshots of the database at specified intervals. AOF (append-only file) persistence logs every write operation received by the server. You can use both RDB and AOF persistence for maximum data safety.
Redis Sentinel, itself a distributed system, provides high availability for Redis. It does monitoring of the master and replica instances, notification if there is something wrong, and automatic failover if the master stops working. It also serves as a configuration provider for clients.
Redis Cluster provides a way to run a Redis installation where data is automatically sharded across multiple Redis nodes. Redis Cluster also provides some degree of availability during partitions, although the cluster will stop operating if the majority of masters become unavailable.
As I mentioned earlier, Redis is a key-value store that supports Strings, Lists, Sets, Sorted Sets, Hashes, Streams, HyperLogLogs, and Bitmaps as values. One of the simplest and most common use cases is using integer values as counters. In support of this, INCR (increment), DECR (decrement), and other single operations are atomic, and therefore safe in a multi-client environment. In Redis, when keys are manipulated they will automatically be created if they don’t already exist.
> SET connections 10
OK
> INCR connections
(integer) 11
> INCR connections
(integer) 12
> DEL connections
(integer) 1
> INCR connections
(integer) 1
> INCRBY connections 100
(integer) 101
> DECR connections
(integer) 100
> DECRBY connections 10
(integer) 90
The other kinds of value structures also have their own examples in the Try Redis tutorial. The tutorial was undergoing maintenance when I tried it myself; I expect that to be fixed soon, as Redis Labs has become involved in what was originally a community effort.
There are a number of add-on modules for Redis including (in descending order of popularity) a neural network module, full-text search, SQL, a JSON data type, and a graph database. The licenses for modules are set by the authors. Some of the modules that work with Redis are primarily modules for Redis Enterprise.
Redis Enterprise enhancements
Using a shared-nothing cluster architecture, Redis Enterprise delivers infinite linear scaling without imposing any non-linear overheads in a scaled-out architecture. You can deploy multiple Redis instances on a single cluster node, to take full advantage of multi-core computer architecture. Redis Enterprise has demonstrated scaling to hundreds of millions of operations per second with five nines (99.999%) uptime. Redis Enterprise does automatic re-sharding and rebalancing while maintaining low latency and high throughput for transactional loads.
Redis Enterprise offers active-active deployment for globally distributed databases, enabling simultaneous read and write operations on the same dataset across multiple geo-locations. To make that more efficient, Redis Enterprise can use conflict-free replicated data types (CRDTs) to maintain consistency and availability of data. Riak and Azure Cosmos DB are two other NoSQL databases that support CRDTs.
While there is extensive academic literature on CRDTs, I admit I don’t completely understand how or why they work. The short summary of what they do is that CRDTs can resolve inconsistencies without intervention, using a mathematically derived set of rules. CRDTs are valuable for high-volume data that require a shared state, and can use geographically dispersed servers to reduce latency for users.
One of the major differences between Redis and Redis Enterprise is that Redis Enterprise decouples the data path from cluster management. This improves the operation of both components. The data path is based on multiple zero-latency, multi-threaded proxies that reside on each of the cluster nodes to mask the underlying complexity of the system. The cluster manager is a governing function that provides capabilities such as resharding, rebalancing, auto-failover, rack-awareness, database provisioning, resource management, data persistence configuration, and backup and recovery. Because the cluster manager is entirely decoupled from the data path components, changes to its software components do not affect the data path components.
Redis on Flash is a Redis Enterprise feature that can drastically reduce the cost of hardware for Redis. Instead of having to pay through the nose for terabytes of RAM or restrict the size of your Redis datasets, you can use Redis on Flash to place frequently accessed hot data in memory and colder values in Flash or persistent memory, such as Intel Optane DC.
Redis Enterprise modules include RedisGraph, RedisJSON, RedisTimeSeries, RedisBloom, RediSearch, and RedisGears. All Redis Enterprise modules also work with open source Redis.
What’s new in Redis 6?
Redis 6 is a big release, both for the open source version and the Redis Enterprise commercial version. The performance news is the use of threaded I/O, which gives Redis 6 a 2x improvement in speed over Redis 5 (which was no slouch). That carries over into Redis Enterprise, which has additional speed improvements for clusters as described above.
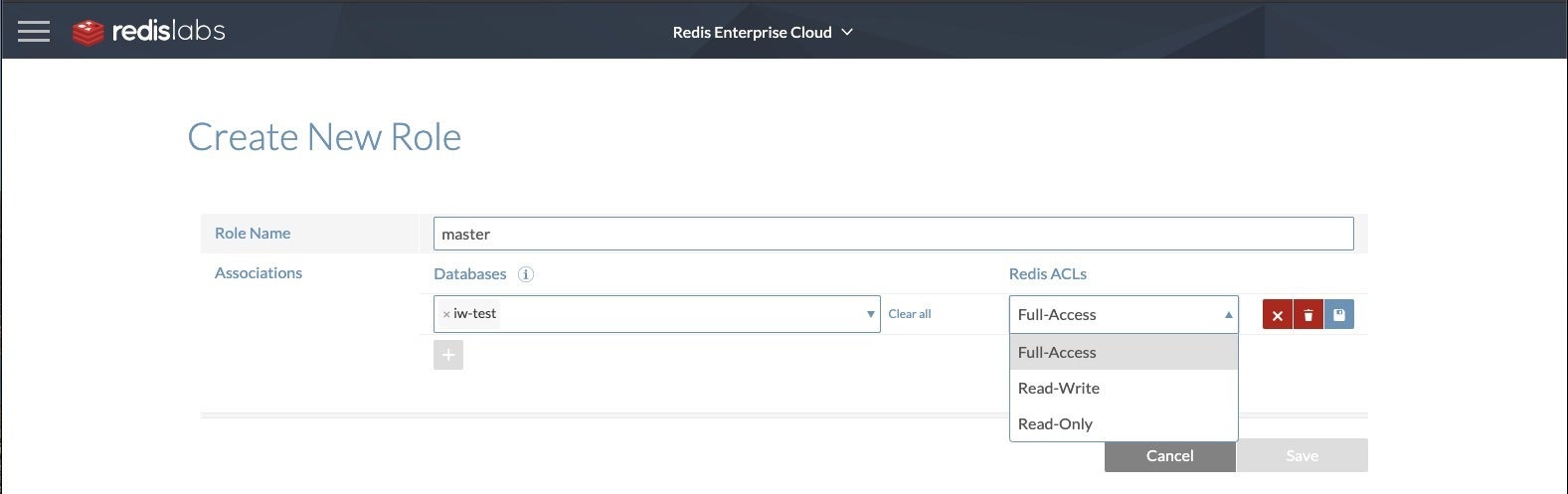
The addition of access control lists (ACLs) gives Redis 6 the concept of users, and allows developers to write more secure code. Redis Enterprise 6 builds on ACLs to offer role-based access control (RBAC), which is more convenient for the programmers and DBAs.
Redis Enterprise 6.0 adds support for the Streams data type in active-active databases. That allows both high availability and low latency while concurrently reading and writing to and from a real-time stream in multiple data centers in multiple geographic locations.
RedisGears is a dynamic framework that enables developers to write and execute functions that implement data flows in Redis. It lets users write Python scripts to run inside Redis, and enables a number of use cases including write-behind (Redis acts as a front-end to a disk-based database), real-time data processing, streaming and event processing, operations that cross data structures and models, and AI-driven transactions.
RedisAI is a model serving engine that runs inside Redis. It can perform inference with PyTorch, TensorFlow, and ONNX models. RedisAI can run on CPUs and GPUs, and enables use cases such as fraud detection, anomaly detection, and personalization.
 IDG
IDG
Creating a new role in Redis Enterprise Cloud. RBAC is considerably easier to manage that ACLs.
Installing Redis
You can install Redis by downloading and compiling a source tarball or by pulling a Docker image from the Docker Hub. Redis can be compiled and used on Linux, MacOS, OpenBSD, NetBSD, and FreeBSD. The source code repository is on GitHub. On Windows, you can run Redis either in a Docker container or under Windows Subsystem for Linux (WSL), which requires Windows 10.
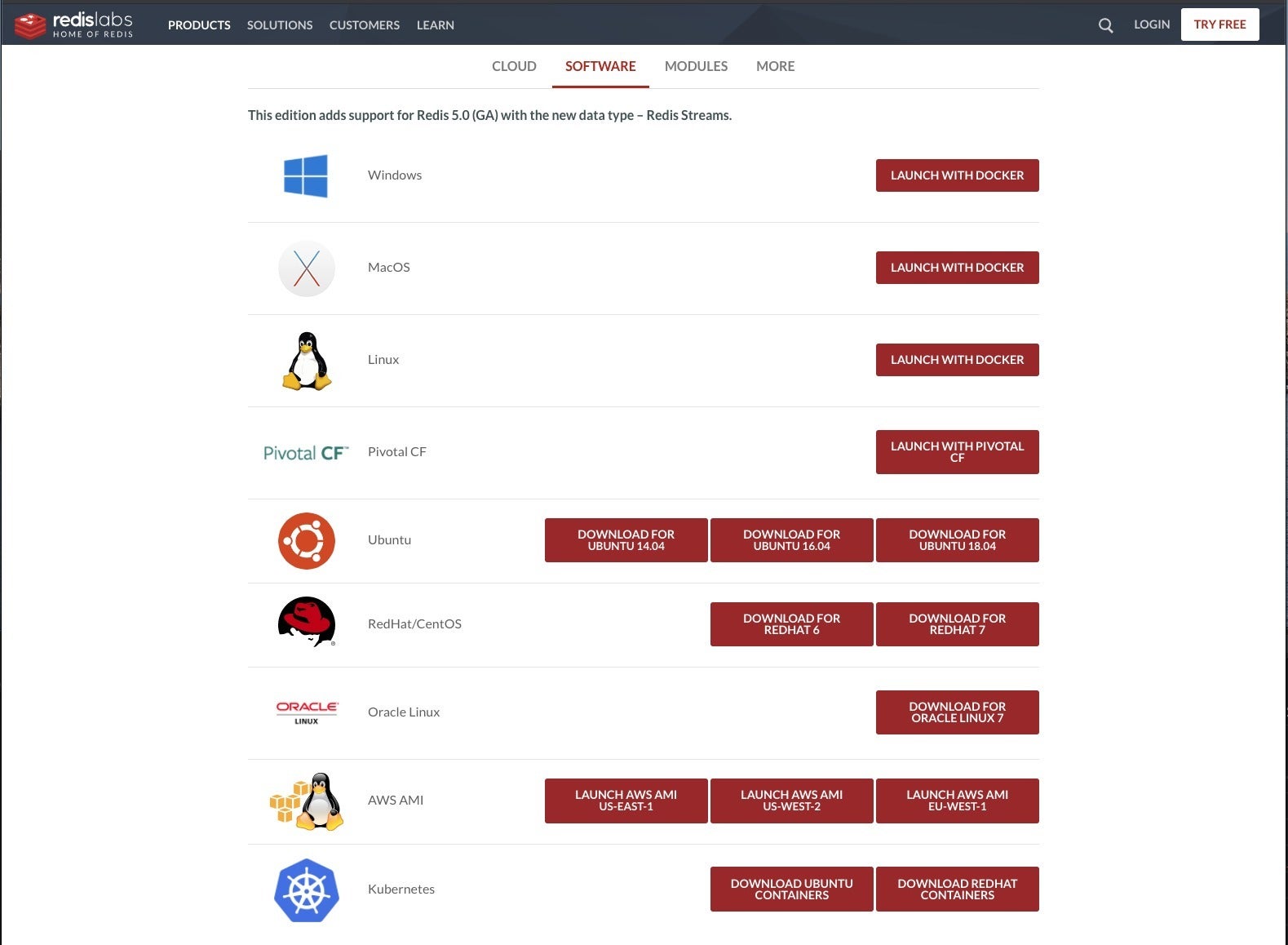
You can install Redis Enterprise on Linux or in Docker containers. The Linux downloads come in the form of binary packages (DEB or RPM depending on the flavor of Linux) and Bash shell scripts for cluster installation. The scripts check for the required four cores and 15 GB of RAM for installation.
 IDG
IDG
Redis Enterprise installs on Docker and on Linux systems. This page shows the Redis Enterprise 5.0 installers, as the Redis Enterprise 6.0 installers are still in the release candidate phase, although I was given the Linux installers for Redis Enterprise 6.0 RC privately when I asked.
Redis Enterprise Cloud
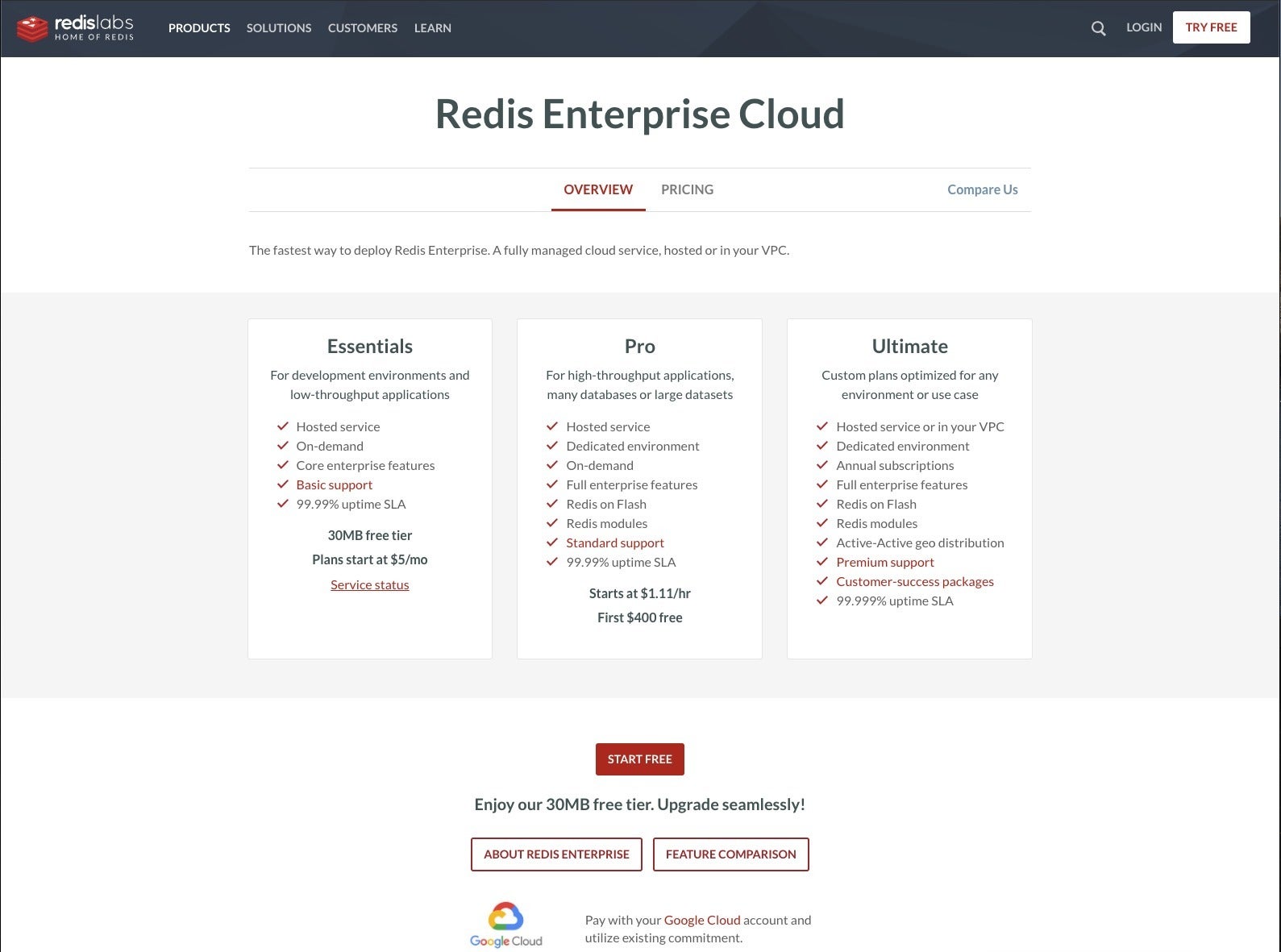
The fastest way to install Redis Enterprise is not to install it at all, but rather to run it in the Redis Enterprise Cloud. When I tried this myself for review purposes, I initially received a Redis 5 instance; I had to ask for an upgrade to Redis 6.
 IDG
IDG
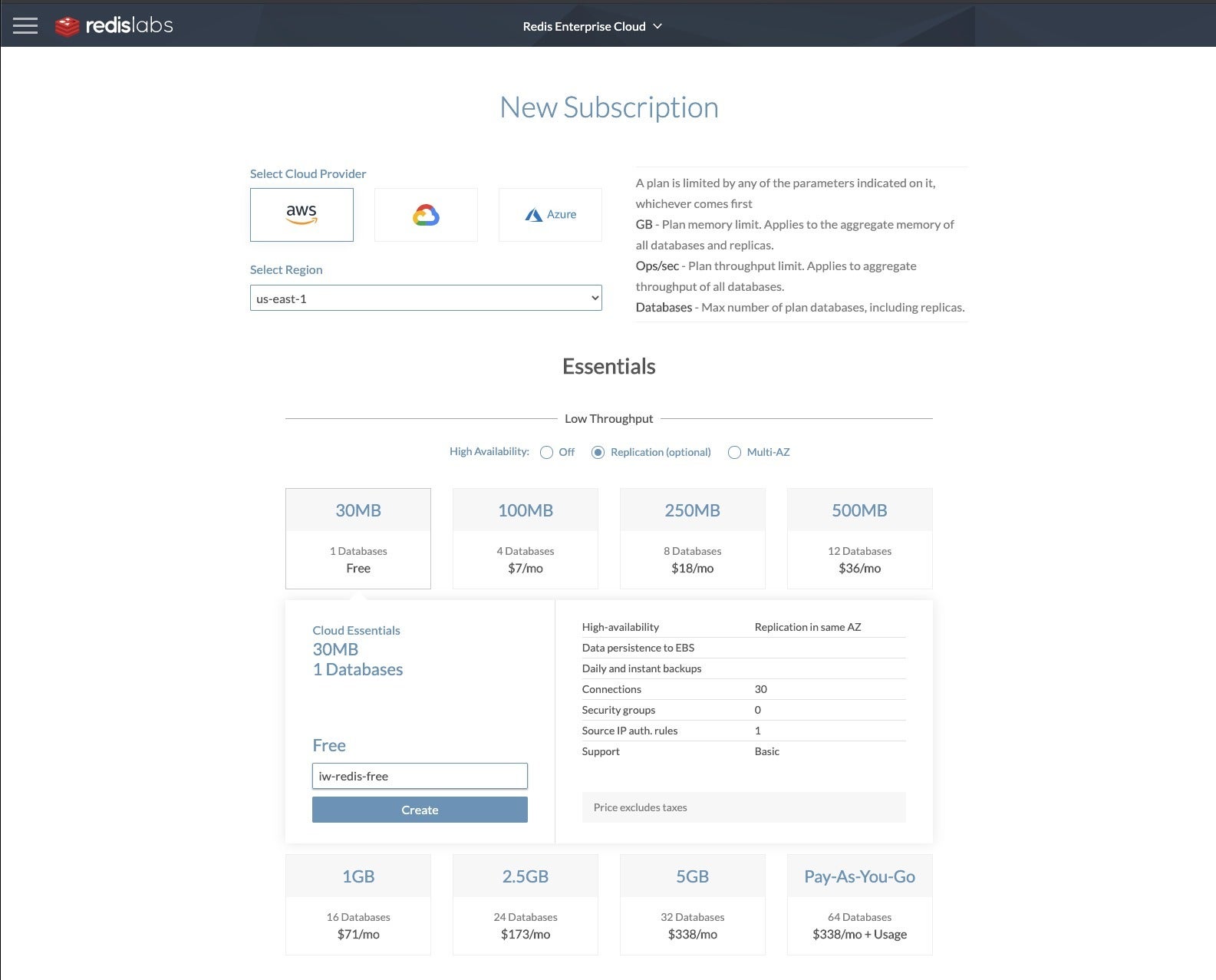
You can run a small instance in the Redis Enterprise Cloud for free, or a full-featured instance for a monthly price that depends on the amount of RAM provisioned. While this description says that Redis modules are not available for low-throughput Essentials environments, Redis Labs is currently rolling out Module support at the Essential level starting with the AWS Mumbai zone.
 IDG
IDG
At the Essentials level, instances range from 30 MB of RAM (free) to 5 GB of RAM ($338 per month) and over. Redis Enterprise Cloud instances are available on AWS, GCP, and Azure. You can choose your own region or regions.
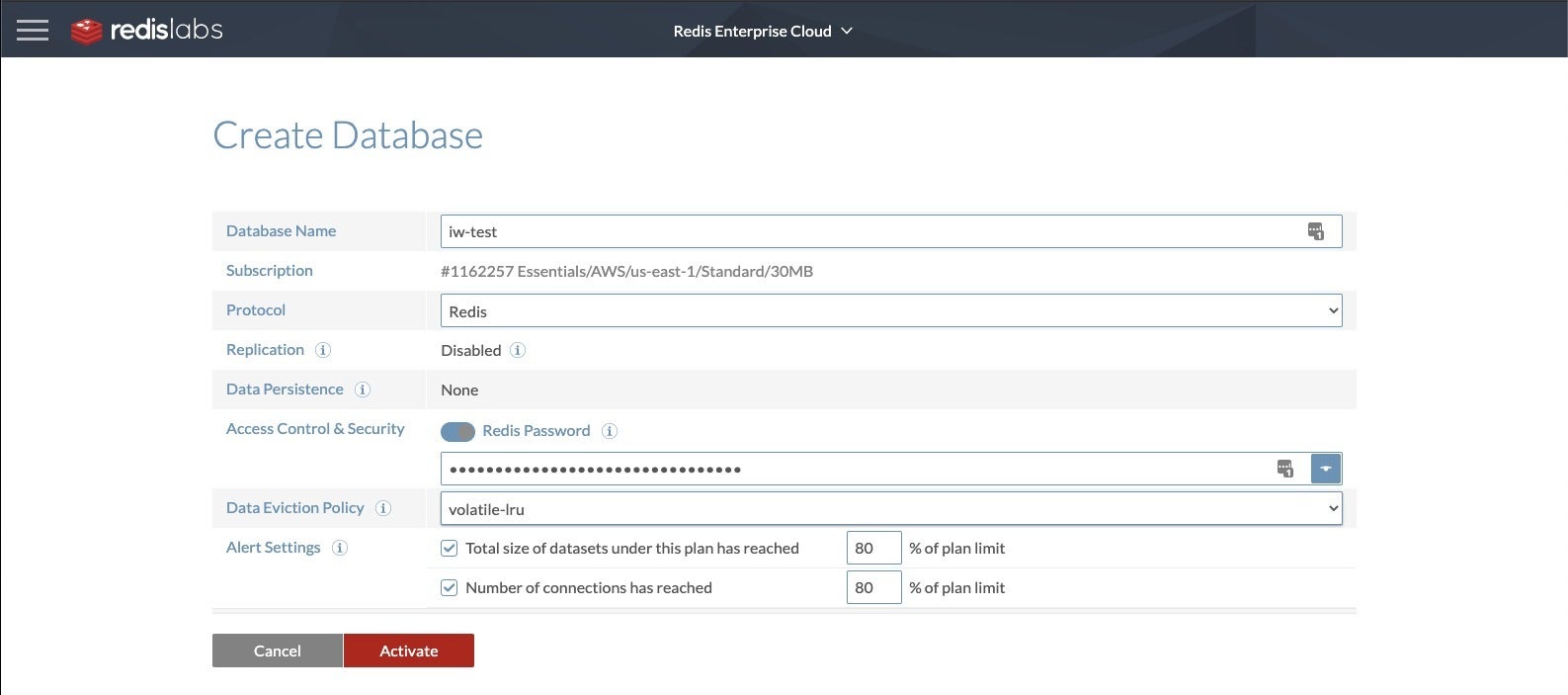 IDG
IDG
Creating a database once you have a Redis Enterprise Cloud subscription is a simple matter of naming the database, choosing a Redis or Memcached protocol, choosing your replication and persistence options, choosing your data eviction policy, and setting your usage alerts.
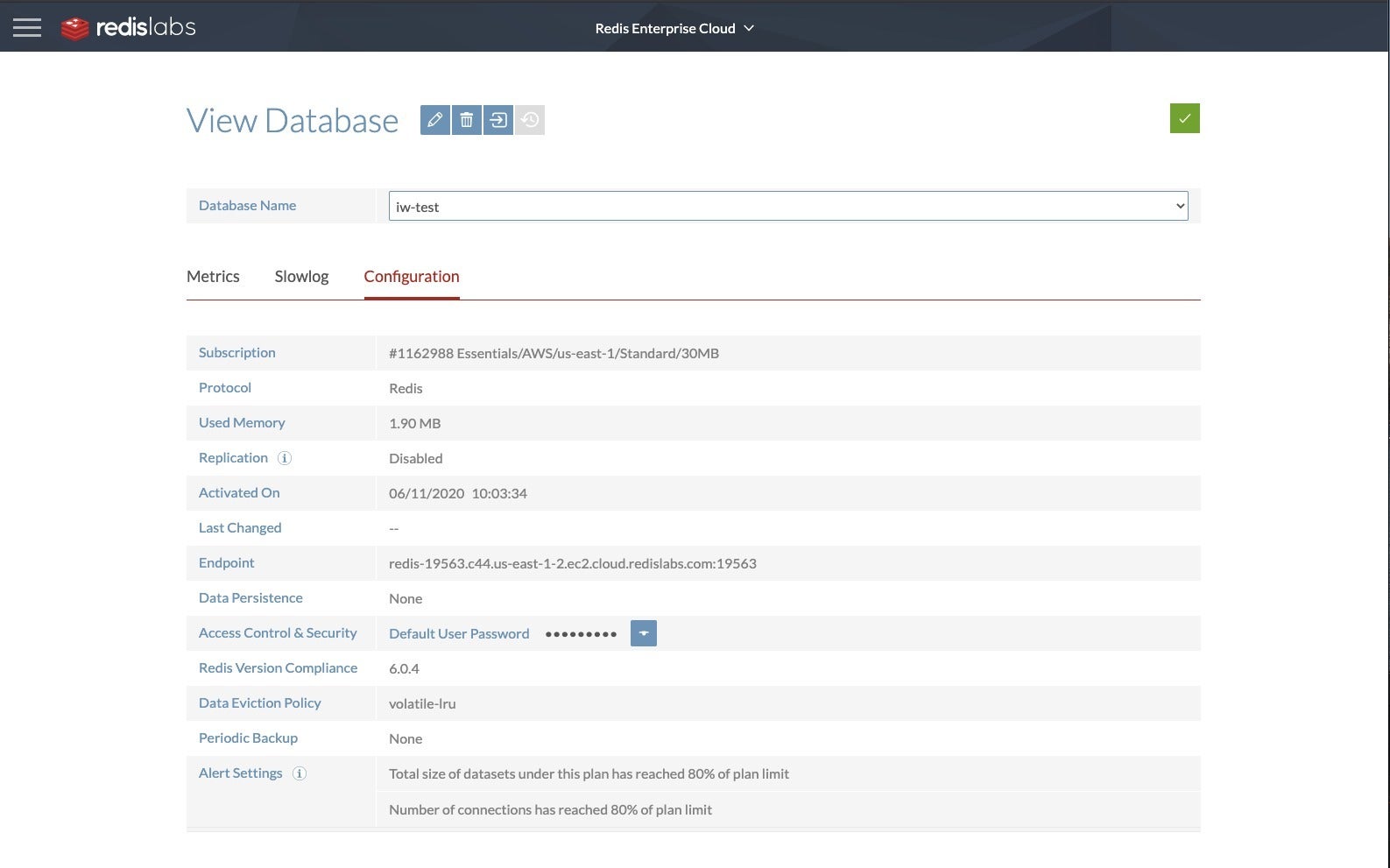 IDG
IDG
Viewing the Redis Enterprise Cloud database configuration shows you the settings as well as the endpoint link. You can copy this link to your client to make connections.