Rockset review: Real-time SQL for operational data
One-of-a-kind database for operational analytics analyzes gigabytes to terabytes of recent, real-time, and streaming data in milliseconds






Contributor, InfoWorld |

-
Rockset
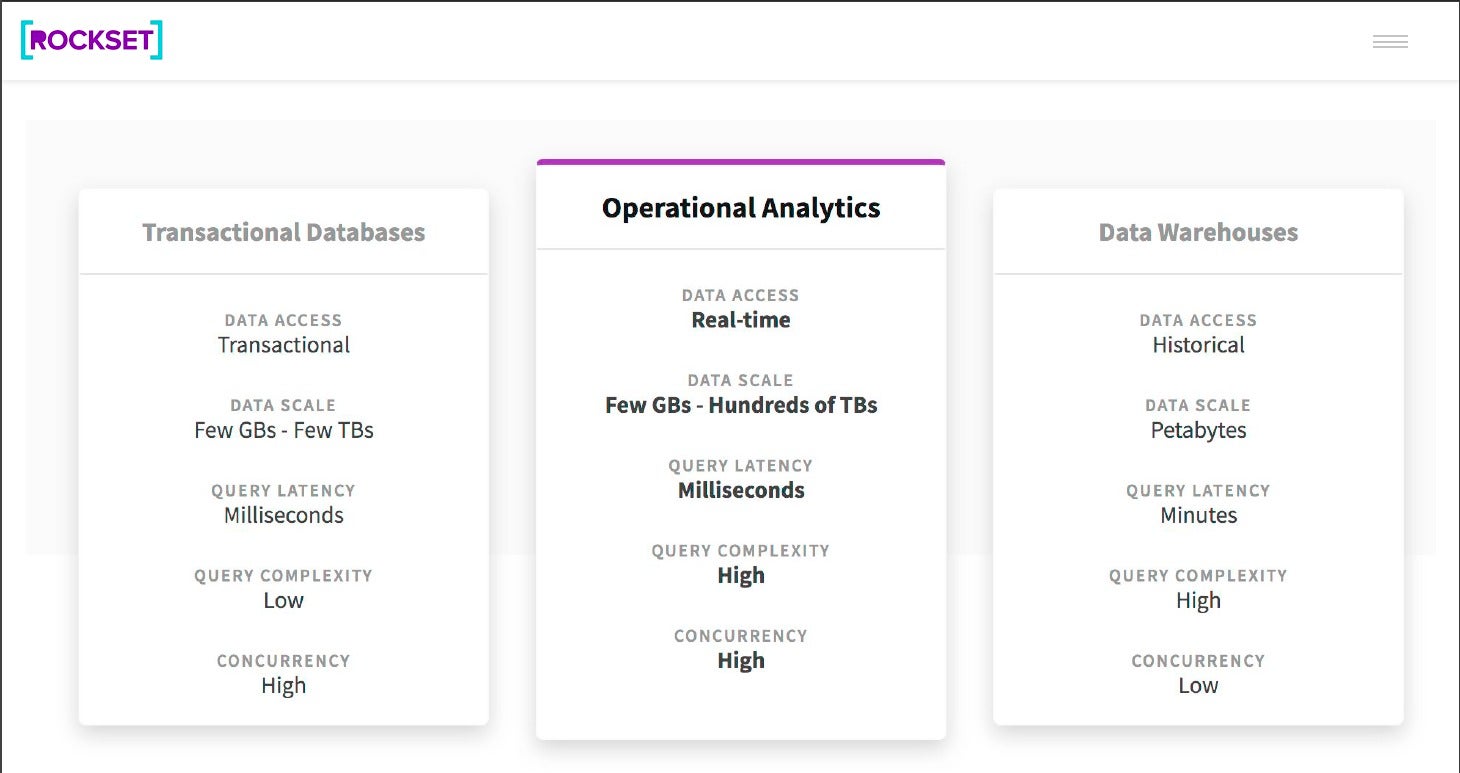
There are, or were, two kinds of SQL database—transactional (OLTP) and analytic (OLAP). After some technological advances, you could combine the OLTP and OLAP functionality and have a hybrid (HTAP). If you have an OLAP database that massively scales complex queries on historical data, then you have a data warehouse.
 InfoWorld
InfoWorldIf you take out the transactions, add search, do schemaless ingestion, and do analytics on real-time data, then you have operational analytics. There’s currently only one database designed for operational analytics, Rockset.
It’s easy to confuse Rockset with a data warehouse, but they are used for somewhat different purposes. You want a data warehouse to analyze petabytes of historical data that you’ve ingested from your databases of record, and for the queries to run in minutes. You want Rockset to analyze gigabytes to terabytes of recent, real-time, and streaming data, and for the queries to run in milliseconds.
Rockset is useful as the data layer for operational dashboards, embedded analytics, IoT applications, personalization, and 360-degree customer analytics.
 Rockset
Rockset
Rockset is an operational analytics database. It occupies a niche between transactional databases and data warehouses.
Running complex queries on hundreds of terabytes of data in milliseconds sounds like magic, but isn’t. As we’ll see, Rockset has an architecture designed to make this possible, as long as your queries take advantage of its indexes.
Relational document model
Rockset doesn’t use a traditional tabular relational database model with a fixed schema. Instead it stores data in a relational document model, a new model that is a better match to data stored in document databases such as DynamoDB and MongoDB, as well as other NoSQL and file data stores. Essentially, Rockset handles semi-structured data formats such as JSON, Parquet, XML, CSV, and TSV by indexing and storing them in a way that can support relational queries using SQL, as shown in the figure below. Of necessity, Rockset implements extensions to its SQL dialect to unnest arrays and to handle JSON paths.
Rockset documents contain fields. Sets of documents are called collections, roughly equivalent to relational tables. A set of collections is called a workspace.
 Rockset
Rockset
JSON document ingestion to a Rockset collection. All information in the documents is transferred, including nested arrays. No schema is enforced, so no data is lost.
Strong dynamic typing
As you probably know, data types can be strong or weak, and static or dynamic, depending on the programming language or the database. Rockset has strong dynamic typing with something of a twist: The type of a field is determined at runtime by every column, rather than by entire columns. This differs from most SQL databases, where the values in the same column always have the same type, and the type is determined when the table is created.
For example, a ZIP code field might be a string in some documents in a collection (as it should be), an integer in others, missing in some, and occasionally even a floating point number—the Rockset ingestion process doesn’t try to make them consistent. Missing values are treated as null. Given that Rockset can import streams continuously, that’s probably the right thing to do.
Converged indexing
In a transactional SQL database, index tuning is a constant battle for DBAs and developers. The entire database can slow to a crawl if there is contention for an index, and that can easily happen when there are writes to an indexed field while queries that rely on the index are running.
If you eliminate transactions and make most writes asynchronous and non-blocking, then the constraint goes away, and you can index any field you want without a performance penalty. There’s still storage overhead for the indexes, but Rockset doesn’t charge you for that: You pay only for active data storage. Rockset does allow for a commit marker to block queries until a write has been indexed; that should be reserved for special cases.
Rather than make you carefully tune your indexes, Rockset automatically builds a converged index that uses three kinds of data structures: inverted list indexes, columnar indexes, and document indexes. All columns are indexed. The converged index is physically represented as a key-value store. Rockset uses LSM trees for indexes rather than B-trees, to reduce the overhead of index writes.
Rockset makes the converged index highly space-efficient by using delta-encoding between keys, and Zstandard compression with dictionary encoding per file. In addition, it uses bloom filters to quickly find the keys—a 10-bit bloom gives Rockset a 99 percent reduction in I/O.
Time series data optimizations
Conventional databases expect to retain all data forever, which can be a problem if time-series data is continually streamed, since the database will grow without bounds. Running SQL jobs to trim the database periodically often has a high overhead (I used to run jobs like that in the wee hours on weekends) and can disrupt the database index statistics (which can require an index rebuild, potentially incurring downtime) as well as blowing out the database cache.
Rockset does rolling window compaction, meaning that you can mark any collection for timed retention (time to live) and optionally designate an event-time field. In the absence of a designated time stamp field, Rockset will use the document creation time. In addition, Rockset automatically maintains an index on event time in descending order. Rockset’s time-based compaction has much lower overhead than SQL deletion operations.
Distributed query processing and ALT
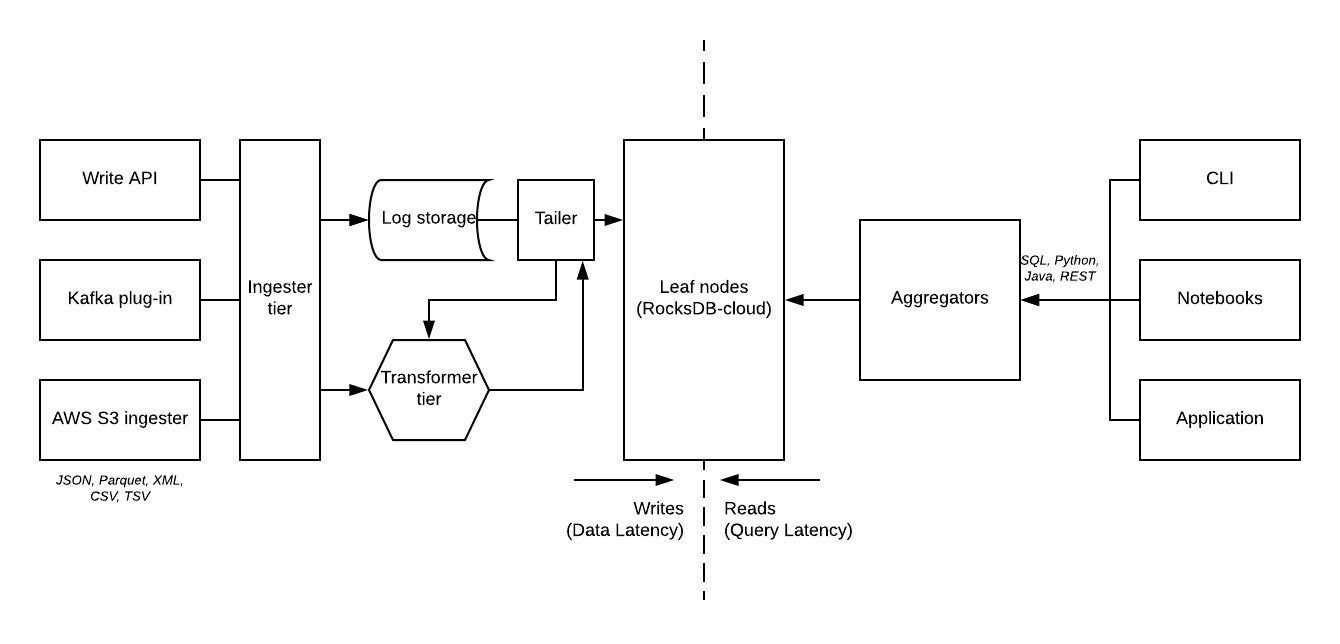
Traditional SQL databases were designed to run on single servers. Rockset was designed for the cloud, and that is reflected in its discrete, containerized microservices architecture and its scalable-on-demand resource use. It uses an aggregator-leaf-tailer (ALT) architecture, the same as Facebook and Google use for newsfeeds, search, ads, spam detection, and graph indexing.
Rockset separates durability from performance. It uses hierarchical storage, with the help of RocksDB-Cloud, which is a high performance embedded storage engine optimized for SSDs. A RocksDB-Cloud instance automatically places hot data in SSD and cold data in cloud storage. The cloud storage contains the entire database and the local storage contains only the files in the working set.
 Rockset
Rockset
Rockset distributed query processing. The SQL coordinator does the query planning and task scheduling, the leaf nodes do the work, and the aggregators combine the results.
 Rockset
Rockset
Rockset ALT architecture diagram.
Data security
Rockset currently runs on AWS and uses AWS best security practices, although it may run on other public clouds in the future. Data in flight from customers to Rockset and from Rockset back to customers is encrypted via SSL/TLS certificates, which are created and managed by AWS Certificate Manager. An AWS application load balancer terminates SSL connections. All data at rest is encrypted, and the encryption keys are managed by AWS KMS. Rockset supports role-based access controls for fine-grained permissions.
Data sources and SQL clients
Rockset can ingest data from Amazon S3, Kinesis, DynamoDB, and Redshift, Google Cloud Storage, Apache Kafka, and its own Write API. It integrates at the SQL level with Jupyter notebooks, Redash, Apache Superset, JetBrains DataGrip, Tableau, RStudio, and Grafana. It has API integrations for REST API, Python, Java, Node.js, Go, and R.
You can map fields during ingestion, for example to mask personally identifiable information and protected health information, to tokenize text fields for searching, and to pre-compute the result of expensive SQL expressions, such as applying regular expressions to parse email addresses or URLs.
 Rockset
Rockset
Rockset system diagram with integrations.
Testing Rockset
I tested on two instances of Rockset: a private instance as part of a 30-day free trial, and a shared instance maintained by Rockset for demo purposes. I used the private instance to walk through the Rockset quick start tutorial, and the demo instance to test Rockset on a large collection, a month’s worth of Twitter posts.
An enterprise would be likely to use a private instance to import its own data and set up a proof of concept of a dashboard, and Rockset would be willing to assist in setting that up.
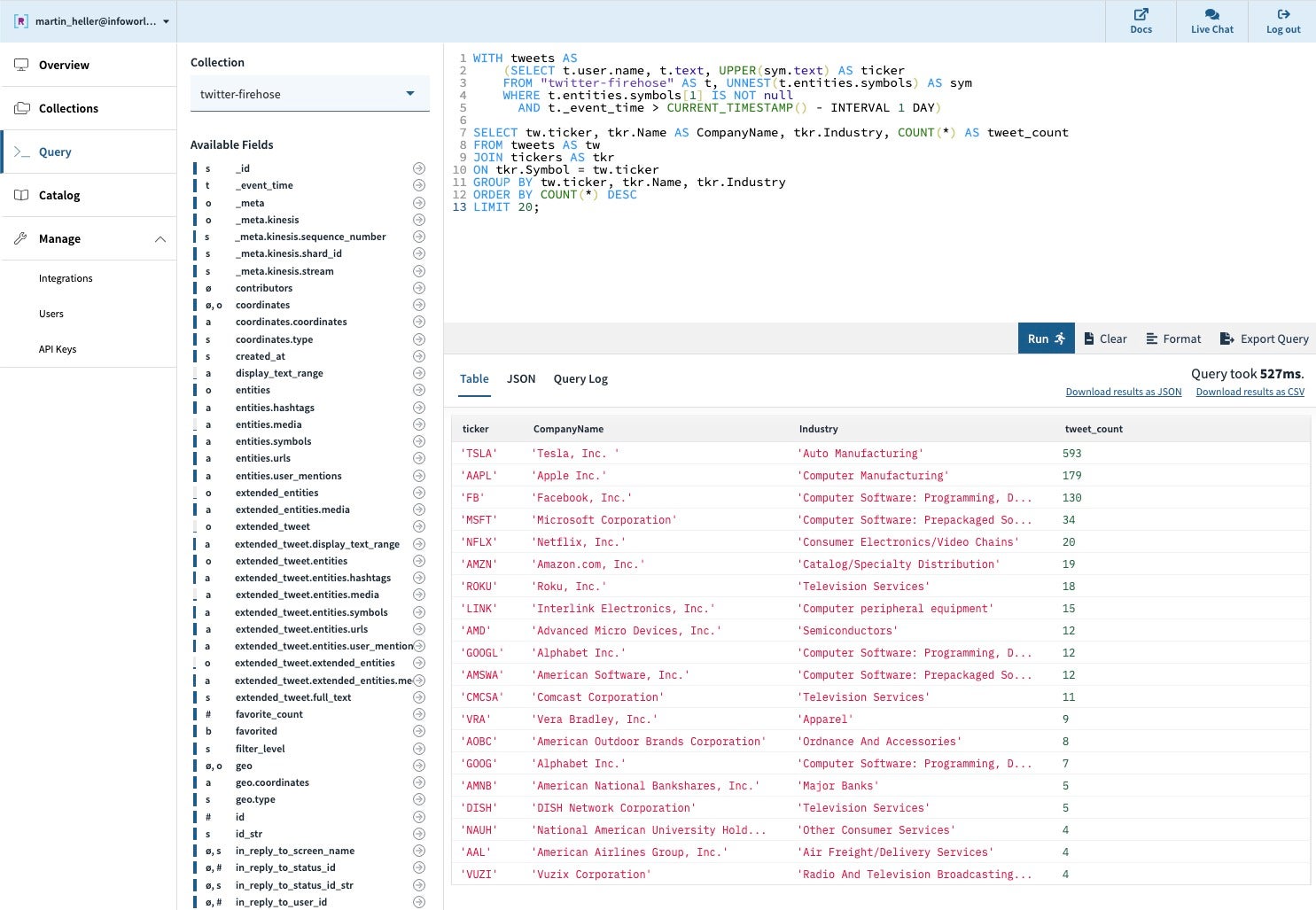
The most interesting query I tried is shown in the screenshot below. Note that there are far fewer tweets that mention stock symbols (22 thousand) than total tweets in the collection (60 million). The speed of queries in Rockset is determined by the selectivity of the query, not the total size of the collections queried.
> select count(*) from "twitter-firehose" as t;
59851099
> select count(*) from “twitter-firehose” as t where t.entities.symbols[1] is not null;
21877
 IDG
IDG
Rockset query against one month of Twitter Firehose tweets; the query and data set are courtesy of Rockset. Note the use of unnest in line 3 of the query, and the event_time range clause in line 5. The tickers collection provides the descriptions for the stock symbols mentioned in the tweets.
As I said earlier, Rockset is useful as the data layer for operational dashboards, embedded analytics, IoT applications, personalization, and 360-degree customer analytics. It really has no direct competition at this point. When I asked the company about losing sales to Snowflake, they said that their experience is that customers want Rockset in addition to a data warehouse, and that the products tend to coexist rather than compete.
I have to admire the strategy of creating a converged index on all fields. It flies in the face of all my experience with SQL databases, but it makes perfect sense, and clearly it works to speed up queries. It helps that Rockset doesn’t charge for index storage.
I was only able to make a query time out once, with the following query:
SELECT * from commons."twitter-firehose"
ORDER by "twitter-firehose".favorite_count desc
LIMIT 10
In fact, there is no way to make that query run fast with Rockset’s converged index, or any indexing scheme I can think of: It requires a full scan and a global sort. Given that the collection has 60 million records, it would take an outlandish amount of RAM to make the query complete in a reasonable amount of time. Taking out the ORDER BY clause allows the query to run in about 300 ms, which is perfectly reasonable.
Given the 30-day free trial, and the ease of doing data imports, it’s worth doing a trial of Rockset if you have significant amounts of data in any of the data stores it knows how to ingest.
—
Cost: Free plan, limit 2 GB of active data (does not include indexes). Basic, $6 per active GB per month, multitenant, 9-to-5 Monday-thru-Friday ticket-based support. Pro, $9 per active GB per month, dedicated scalable compute, RBAC, 9-to-5 Monday-thru-Friday support with four-hour SEV1 response. Enterprise, call for pricing, two-factor authentication, AWS private link, 24/7 one-hour SEV1 response.
Platform: Hosted on AWS cloud
Copyright © 2019 IDG Communications, Inc.