Snowflake review: A data warehouse made better in the cloud
A fast, no-fuss data warehouse as a service, Snowflake scales dynamically to give you the performance you need exactly when you need it






Contributor, InfoWorld |

-
Snowflake
Data warehouses, also called enterprise data warehouses (EDW), are highly parallel SQL or NoSQL databases designed for analysis. They let you import data from multiple sources and generate complicated reports quickly from petabytes of data.
 InfoWorld
InfoWorldThe difference between a data warehouse and a data mart is that, typically, a data mart is limited to a single topic and a single department. The difference between a data warehouse and a data lake is that a data lake stores data in its natural format, often blobs or files, while a data warehouse stores data as a database.
Snowflake in brief
Snowflake is a fully relational ANSI SQL data warehouse that was built from the ground up for the cloud. Its architecture separates compute from storage so that you can scale up and down on the fly, without delay or disruption, even while queries are running. You get the performance you need exactly when you need it, and you only pay for the compute you use. Snowflake currently runs on Amazon Web Services and Microsoft Azure.
Snowflake is a fully columnar database with vectorized execution, making it capable of addressing even the most demanding analytic workloads. Snowflake’s adaptive optimization ensures queries automatically get the best performance possible, with no indexes, distribution keys, or tuning parameters to manage.
Snowflake can support unlimited concurrency with its unique multi-cluster, shared data architecture. This allows multiple compute clusters to operate simultaneously on the same data without degrading performance. Snowflake can even scale automatically to handle varying concurrency demands with its multi-cluster virtual warehouse feature, transparently adding compute resources during peak load periods and scaling down when loads subside.
Snowflake competitors
Competitors to Snowflake in the cloud include Amazon Redshift, Google BigQuery, and Microsoft Azure SQL Data Warehouse. Other major competitors, such as Teradata, Oracle Exadata, MarkLogic, and SAP BW/4HANA, may be installed in the cloud, on premises, and on appliances.
Amazon Redshift
Amazon Redshift is a fast, scalable data warehouse that lets you analyze all your data across your data warehouse and your Amazon S3 data lake. You query Redshift using SQL. A Redshift data warehouse is a cluster that can automatically deploy and remove capacity with concurrent query load. However, all of the cluster nodes are provisioned in the same availability zone.
Microsoft Azure SQL Data Warehouse
Microsoft Azure SQL Data Warehouse is a cloud-based data warehouse that uses the Microsoft SQL engine and MPP (massively parallel processing) to quickly run complex queries across petabytes of data. You can use Azure SQL Data Warehouse as a key component of a big data solution by importing big data into SQL Data Warehouse with simple PolyBase T-SQL queries, then using the power of MPP to run high-performance analytics.
Azure SQL Data Warehouse is available in 40 Azure regions around the world, but a given warehouse server only exists in a single region. You can scale your data warehouse performance on demand, but any running queries will be canceled and rolled back.
Google BigQuery
Google BigQuery is a serverless, highly scalable, and cost-effective cloud data warehouse with GIS queries, an in-memory BI Engine and machine learning built in. BigQuery runs fast SQL queries on gigabytes to petabytes of data and makes it straightforward to join public or commercial data sets with your data.
You can set the geographic location of a BigQuery data set at creation time only. All tables referenced in a query must be stored in data sets in the same location. That also applies to external data sets and storage buckets. There are additional restrictions on the location of external Google Cloud Bigtable data. By default, queries run in the same region as the data.
Locations may be specific places, such as Northern Virginia, or large geographic areas, such as the EU or US. To move a BigQuery data set from one region to another, you have to export it to a Google Cloud Storage bucket in the same location as your data set, copy the bucket to the new location, and load that into BigQuery in the new location.
Snowflake architecture
Snowflake uses virtual compute instances for its compute needs and a storage service for persistent storage of data. Snowflake cannot be run on private cloud infrastructures (on-premises or hosted).
There is no installation to perform, and no configuration. All maintenance and tuning is handled by Snowflake.
Snowflake uses a central data repository for persisted data that is accessible from all compute nodes in the data warehouse. At the same time, Snowflake processes queries using MPP (massively parallel processing) compute clusters where each node in the cluster stores a portion of the entire data set locally.
When data is loaded into Snowflake, Snowflake reorganizes that data into its internal compressed, columnar format. The internal data objects are only accessible through SQL queries. You can connect to Snowflake through its web UI, through a CLI (SnowSQL), through ODBC and JDBC drivers from applications such as Tableau, through native connectors for programming languages, and through third-party connectors for BI and ETL tools.
 Snowflake
Snowflake
Snowflake architecture diagram. Note that the CPU resources of the virtual warehouses can be scaled independently of the database storage.
Snowflake features
Security and data protection. The security features offered in Snowflake vary by edition. Even the standard edition offers automatic encryption of all data and support for multi-factor authentication and single sign-on. The Enterprise addition adds periodic re-keying of encrypted data, and the Enterprise for Sensitive Data edition adds support for HIPAA and PCI DSS. You can choose where your data is stored, which helps conform to EU GDPR regulations.
Standard and extended SQL support. Snowflake supports most DDL and DML defined in SQL:1999, plus transactions, some advanced SQL features, and parts of the SQL:2003 analytic extensions (windowing functions and grouping sets). It also supports lateral and materialized views, aggregate functions, stored procedures, and user-defined functions.
Tools and interfaces. Notably, Snowflake allows you to control your virtual warehouses from the GUI or command line. That includes creating, resizing (with zero downtime), suspending, and dropping warehouses. Resizing a warehouse while a query is running is very convenient, especially when you need to speed up a query that is taking too much time. To the best of my knowledge that is not implemented in any other EDW software.
Connectivity Snowflake has connectors and/or drivers for Python, Spark, Node.js, Go, .Net, JDBC, ODBC, and dplyr-snowflakedb, an open source dplyr package extension maintained on GitHub.
Data import and export. Snowflake can load a wide range of data and file formats. That includes compressed files; delimited data files; JSON, Avro, ORC, Parquet, and XML formats; Amazon S3 data sources; and local files. It can do bulk loading and unloading into and out of tables, as well as continuous bulk loading from files.
Data sharing. Snowflake has support for securely sharing data with other Snowflake accounts. This is streamlined by the use of zero-copy table clones.
 Snowflake
Snowflake
Snowflake costs vary by edition and location. Features vary by edition. VPS instances are currently available only on AWS.
Snowflake tutorials
Snowflake offers quite a few tutorials and videos. Some help you get started, some explore specific topics, and some demonstrate features.
I recommend working through the hands-on overview described in the Hands-on Lab Guide for Snowflake Free Trial.) It took me under an hour, and cost less than five credits. That left another 195 credits in the free trial, which should be enough to import some real data and test out some queries.
The tutorial makes heavy use of Snowflake worksheets, a convenient way of running commands and SQL within the web UI. It covers, among other things, data loading; querying, results caching, and cloning; semi-structured data; and time travel for restoring database objects.
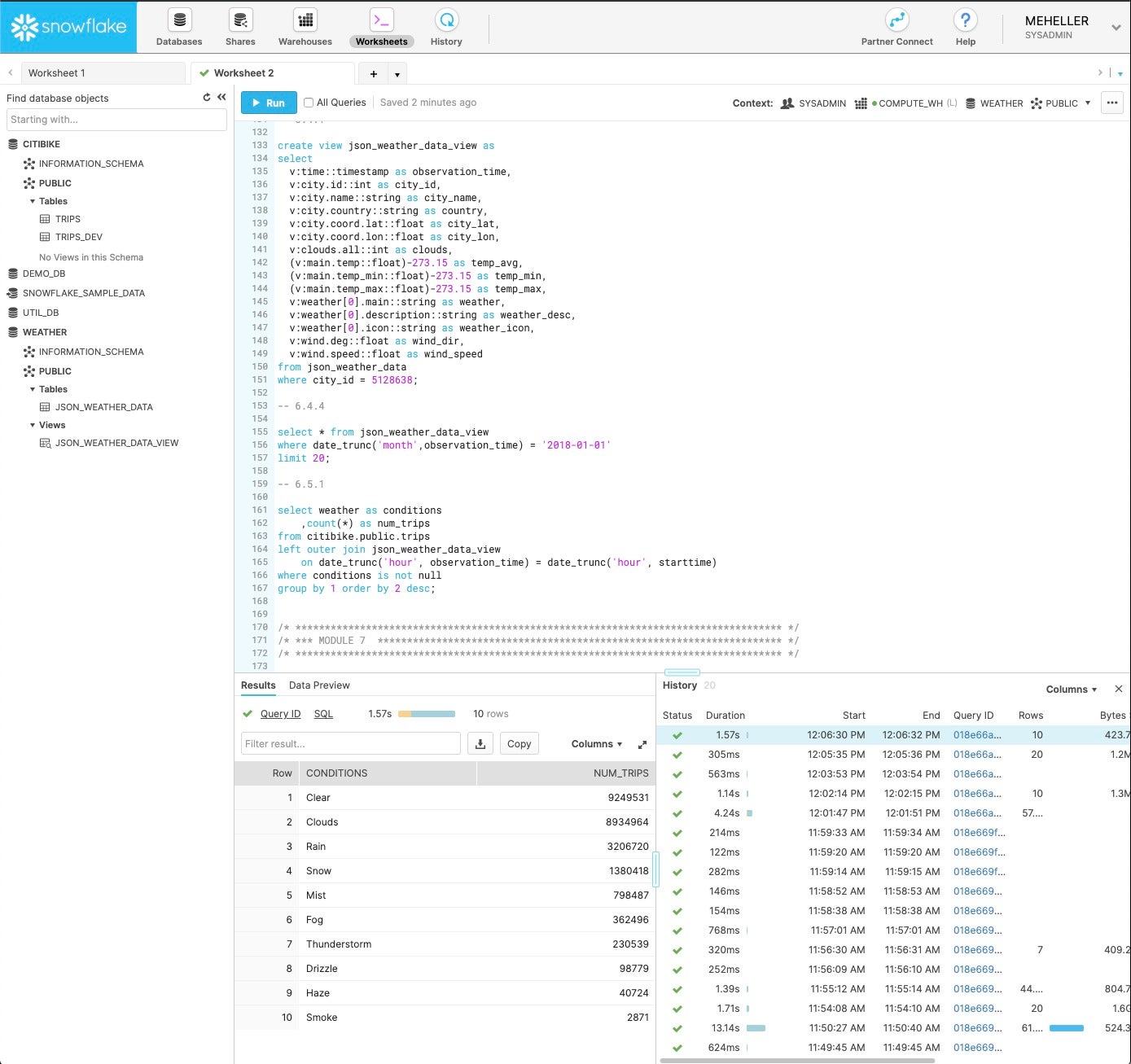 IDG
IDG
Snowflake worksheet (top right) during the hands-on tutorial. The schema information is at top left, the query results are at bottom left, and the query history with timings is at bottom right.
Overall, I find Snowflake quite impressive. I expected it to be clunky, but that isn’t the case at all. In fact, many of its data warehouse operations go much faster than I expected, and when there is one that seems to crawl, I can intervene and upsize the data warehouse without interrupting what’s happening.
 IDG
IDG
Snowflake data warehouse configuration dialog. There is a wide range of sizes, and there are several options to automate cluster scaling.
Much of the scaling can be automated. When creating a data warehouse (see screenshot above) there’s an option to allow multiple clusters, an option to set the scaling policy, an option to auto-suspend, and an option to auto-resume. The default auto-suspend period is 10 minutes, which keeps the warehouse from consuming resources when it’s idle for longer than that. Auto-resuming is nearly instantaneous and occurs whenever there’s a query against the warehouse.
Given that Snowflake offers a 30-day free trial with a $400 credit, and there’s no need to install anything, you should be able to determine whether Snowflake will suit your purposes without any cash outlay. I’d recommend giving it a spin.
—
Cost: $2/credit plus $23/TB/month storage, standard plan, prepaid storage. One credit equals one node*hour, billed by the second. Higher level plans are more expensive.
Platforms: Amazon Web Services, Microsoft Azure
Copyright © 2019 IDG Communications, Inc.