






Thanks to the technology behind ChatGPT, it's become surprisingly simple to query a data set in plain English.
As with most generative AI, results from OpenAI's API are still imperfect, which means you can't just trust them. Fortunately, you can now write code to ask GPT how it would calculate a response—and then you can run the code yourself if you agree with the approach. This means you'll be able to ask natural language questions like, “What were total sales by region last year?” and be confident in accuracy of the response.
Here’s a quick-and-dirty technique for setting up a natural language query of your own database with GPT:
- Put the structure of your data, a few sample rows, or both into a single text string.
- Craft a "prompt" to the AI with that information plus your natural language question.
- Send the prompt to OpenAI's GPT-3.5-turbo API and request an SQL query to answer your question.
- Run the SQL that comes back on your data set to calculate your answer.
- (Optional) Create an interactive application to make it easy to query a data set in plain English.
This method has several advantages when handling real-world data. By sending only the data structure and some sample rows (which could include fake data), there’s no need to send actual sensitive data to OpenAI. There’s also no worry if your data is too big for OpenAI's prompt size limits. And, by requesting SQL instead of a final answer, the ability to check how GPT generates its answer is baked into the process.
Generative AI for enterprise queries
If you’re serious about using generative AI to develop enterprise-grade queries, you might want to investigate tools like LangChain, a framework for working with multiple different large language models (LLMs), not only OpenAI's GPT. OpenAI also recently announced the possibility of including function calls inside of API requests, which is aimed at making querying and similar tasks easier and more reliable. But for a quick prototype or your own use, the process described here is an easy way to get started. My demonstration is done with R, but the technique will work in just about any programming language.
Step 1: Turn your sample data into a single-character string
The sample data in this step could include the database schema and/or a few rows of data. Turning it all into a single-character string is important because it will be part of the larger text-string query you will send to GPT 3.5.
If your data is already in an SQL database, this step should be pretty easy. If it's not, I suggest turning it into SQL-queryable format. Why? After testing both R and SQL code results, I’m more confident in the SQL code GPT generates than its R code. (I suspect that's because the LLM had more SQL data than R for training.)
In R, the sqldf package lets you run SQL queries on an R data frame, and that's what I'll use in this example. There's a similar sqldf library in Python. For larger data where performance is important, you might want to check out the duckdb project.
The following code imports the data file into R, uses sqldf to see what the SQL schema would look like if the data frame were an SQL database table, extracts three sample rows with dplyr's filter() function, and turns both the schema and sample rows into character strings. Disclaimer: ChatGPT wrote the base R apply() portion of the code that turns the data into a single string (I usually do those tasks with purrr).
library(rio)
library(dplyr)
library(sqldf)
library(glue)
states <- rio::import("https://raw.githubusercontent.com/smach/SampleData/main/states.csv") |>
filter(!is.na(Region))
states_schema <- sqldf("PRAGMA table_info(states)")
states_schema_string <- paste(apply(states_schema, 1, paste, collapse = "\t"), collapse = "\n")
states_sample <- dplyr::sample_n(states, 3)
states_sample_string <- paste(apply(states_sample, 1, paste, collapse = "\t"), collapse = "\n")
Step 2: Create a prompt for the LLM
The format should be something like “Act as if you’re a data scientist. You have an SQLite table called {table_name} with the following schema: ```{schema}```. The first rows look like this: ```{rows_sample}```. Based on this data, write an SQL query to answer the following question: {query}. Return the SQL only, do not include explanations."
The following function creates a query in that type of format, taking arguments for the data schema, sample rows, user query, and table name.
create_prompt <- function(schema, rows_sample, query, table_name) {
glue::glue("Act as if you're a data scientist. You have a SQLite table named {table_name} with the following schema:
```
{schema}
```
The first rows look like this:
```{rows_sample}```
Based on this data, write a SQL query to answer the following question: {query}. Return the SQL query ONLY. Do not include any additional explanation.")
}
Step 3: Send the data to OpenAI's API
You can start with cutting and pasting the data into one of OpenAI's web interfaces to see the results in either ChatGPT or the OpenAI API playground. ChatGPT doesn't charge for usage, but you can't tweak the results. The playground lets you set things like temperature—meaning how "random" or creative the response should be—and which model you want to use. For SQL code, I set the temperature to 0.
Next, I save a natural language question to the variable my_query, create a prompt with my create_prompt() function, and see what happens when I paste that prompt into the API playground:
> my_query <- "What were the highest and lowest Population changes in 2020 by Division?"
> my_prompt <- get_query(states_schema_string, states_sample_string, my_query, "states")
> cat(my_prompt)
Act as if you're a data scientist. You have a SQLite table named states with the following schema:
```
0 State TEXT 0 NA 0
1 Pop_2000 INTEGER 0 NA 0
2 Pop_2010 INTEGER 0 NA 0
3 Pop_2020 INTEGER 0 NA 0
4 PctChange_2000 REAL 0 NA 0
5 PctChange_2010 REAL 0 NA 0
6 PctChange_2020 REAL 0 NA 0
7 State Code TEXT 0 NA 0
8 Region TEXT 0 NA 0
9 Division TEXT 0 NA 0
```
The first rows look like this:
```Delaware 783600 897934 989948 17.6 14.6 10.2 DE South South Atlantic
Montana 902195 989415 1084225 12.9 9.7 9.6 MT West Mountain
Arizona 5130632 6392017 7151502 40.0 24.6 11.9 AZ West Mountain```
Based on this data, write a SQL query to answer the following question: What were the highest and lowest Population changes in 2020 by Division?. Return the SQL query ONLY. Do not include any additional explanation.
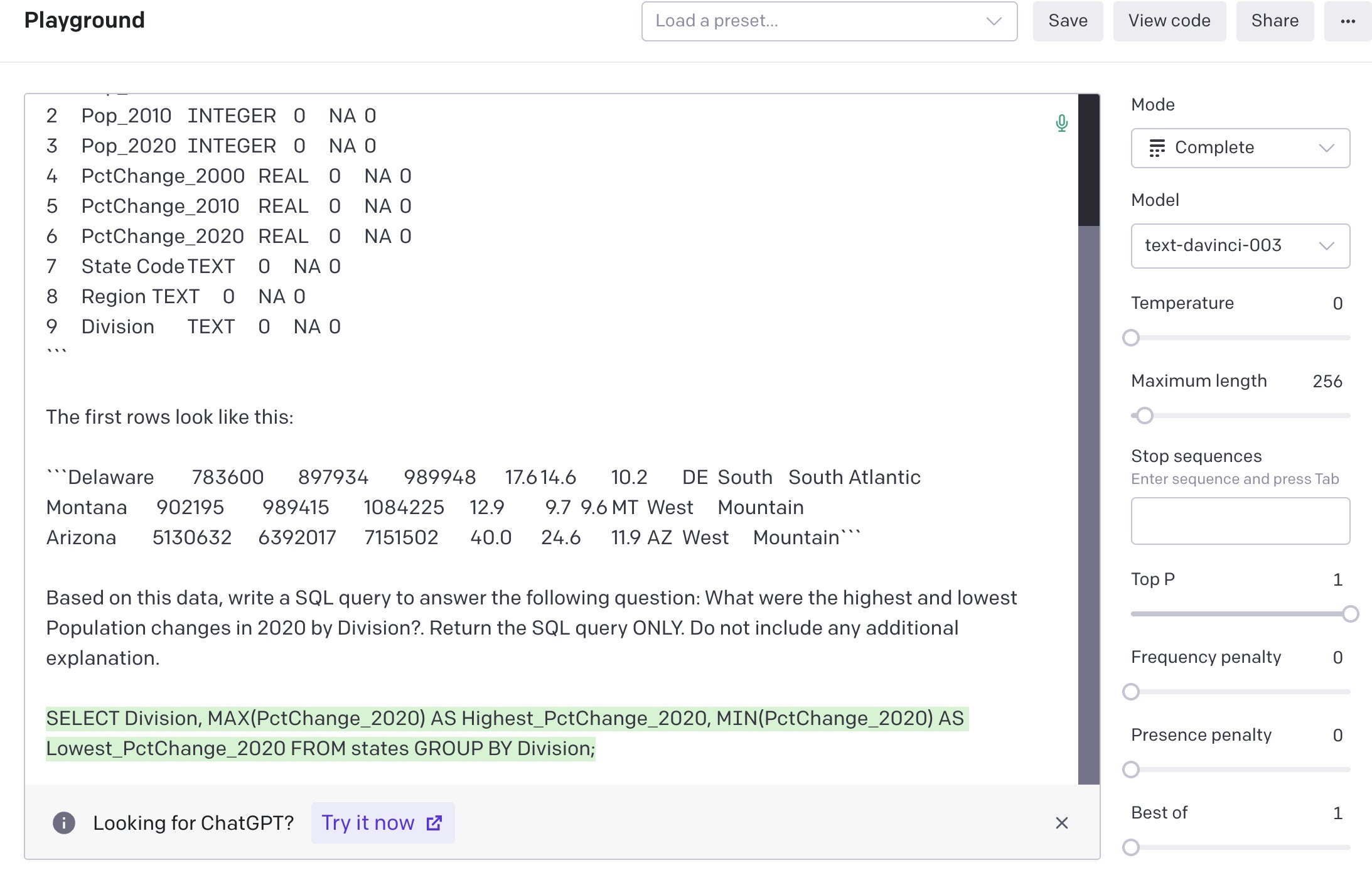 Sharon Machlis screenshot
Sharon Machlis screenshot
Prompt entered into the OpenAI API playground and the resulting SQL code.
Here are the results when I run the suggested SQL:
sqldf("SELECT Division, MAX(PctChange_2020) AS Highest_PctChange_2020, MIN(PctChange_2020) AS Lowest_PctChange_2020 FROM states GROUP BY Division;")
Division Highest_PctChange_2020 Lowest_PctChange_2020
1 East North Central 4.7 -0.1
2 East South Central 8.9 -0.2
3 Middle Atlantic 5.7 2.4
4 Mountain 18.4 2.3
5 New England 7.4 0.9
6 Pacific 14.6 3.3
7 South Atlantic 14.6 -3.2
8 West North Central 15.8 2.8
9 West South Central 15.9 2.7
Not only did ChatGPT generate accurate SQL, but I didn't have to tell GPT that "2020 population change" is in the Pop_2020 column.
Step 4: Execute the results of the SQL code returned by GPT
It would be a lot handier to send and return data to and from OpenAI programmatically instead of cutting and pasting it into a web interface. There are a few R packages for working with the OpenAI API. The following block of code sends a prompt to the API using the openai package, stores the API response, extracts the portion of the response containing the text with the requested SQL code, prints that code, and runs the SQL on the data.
library(openai)
my_results <- openai::create_chat_completion(model = "gpt-3.5-turbo", temperature = 0, messages = list(
list(role = "user", content = my_prompt)
))
the_answer <- my_results$choices$message.content
cat(the_answer)
SELECT Division, MAX(PctChange_2020) AS Highest_Population_Change, MIN(PctChange_2020) AS Lowest_Population_Change
FROM states
GROUP BY Division;
sqldf(the_answer)
Division Highest_Population_Change Lowest_Population_Change
1 East North Central 4.7 -0.1
2 East South Central 8.9 -0.2
3 Middle Atlantic 5.7 2.4
4 Mountain 18.4 2.3
5 New England 7.4 0.9
6 Pacific 14.6 3.3
7 South Atlantic 14.6 -3.2
8 West North Central 15.8 2.8
9 West South Central 15.9 2.7
You need an OpenAI API key if you want to use the API. For this package, the key should be stored in a system environment variable such as OPENAI_API_KEY. Note that the API is not free to use, but I ran this project well over a dozen times the day before I turned it into my editor, and my total account usage was 1 cent.
Step 5 (optional): Create an interactive application
You now have all the code you need to run your query in an R workflow in a script or terminal. But if you'd like to make an interactive application for querying data in plain language, I've included the code for a basic Shiny app that you can use.