





Syncing your knowledge base to the vector database
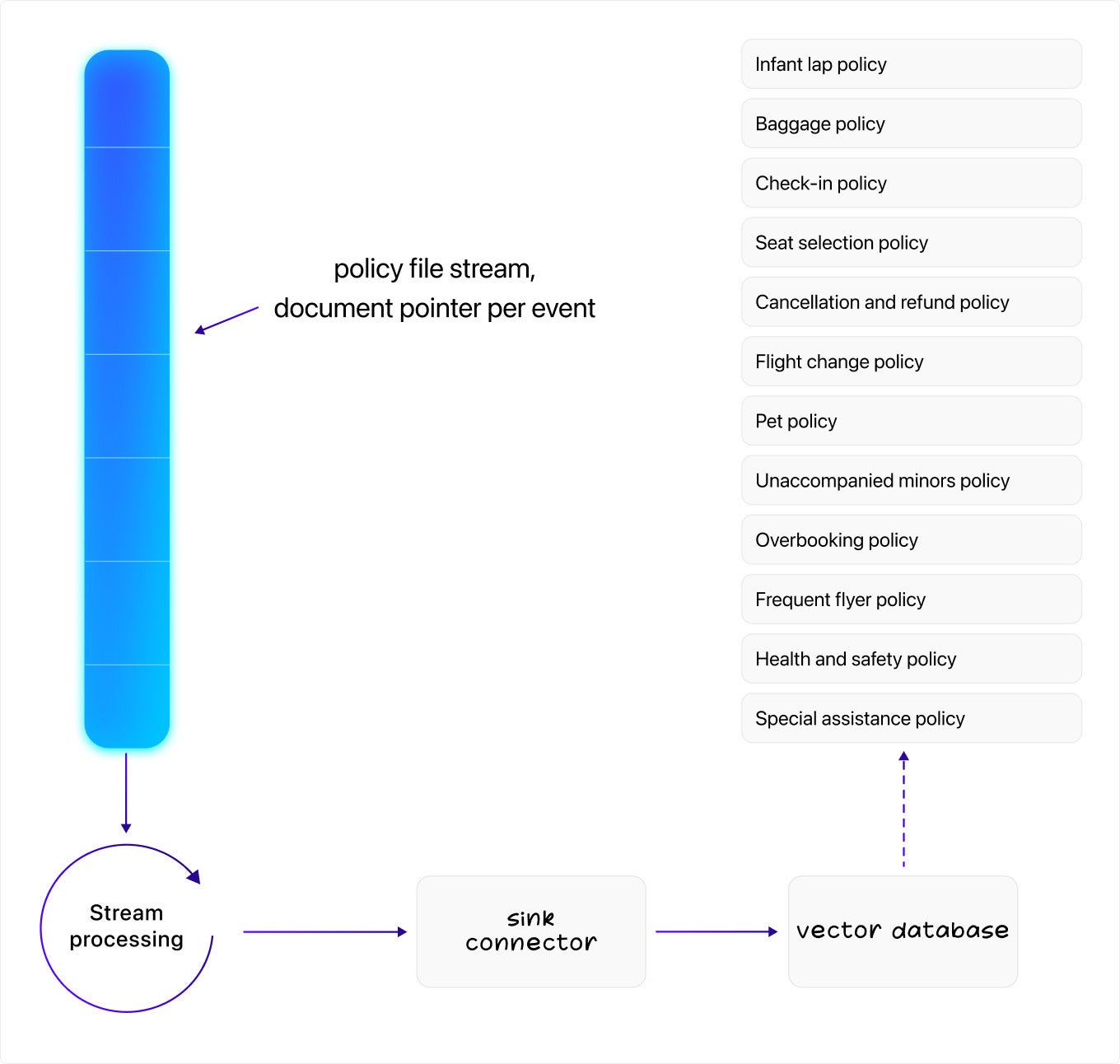
The next step is to get your policy information into the vector database. The biggest decision to make here is how you’ll chunk the data.
Chunking refers to the amount of data that you put together in one embedding. If the chunk size is too large or too small, it’ll be harder for the database to query for related information. To give you an idea of how this works in other domains, you might choose to chunk a Wikipedia article by section, or perhaps by paragraph.
Now, if your policies change slowly or never change, you can scrape all of your policy documents and batch upload them to the vector database, but a better strategy would be to use stream processing. Here again, you can set up connectors to your file systems so that when any file is added or changed, that information can be made rapidly available to the support agent.
If you use stream processing, sink connectors help your data make the final jump, moving your embeddings into the vector database.
 Confluent
ConfluentTying it all together
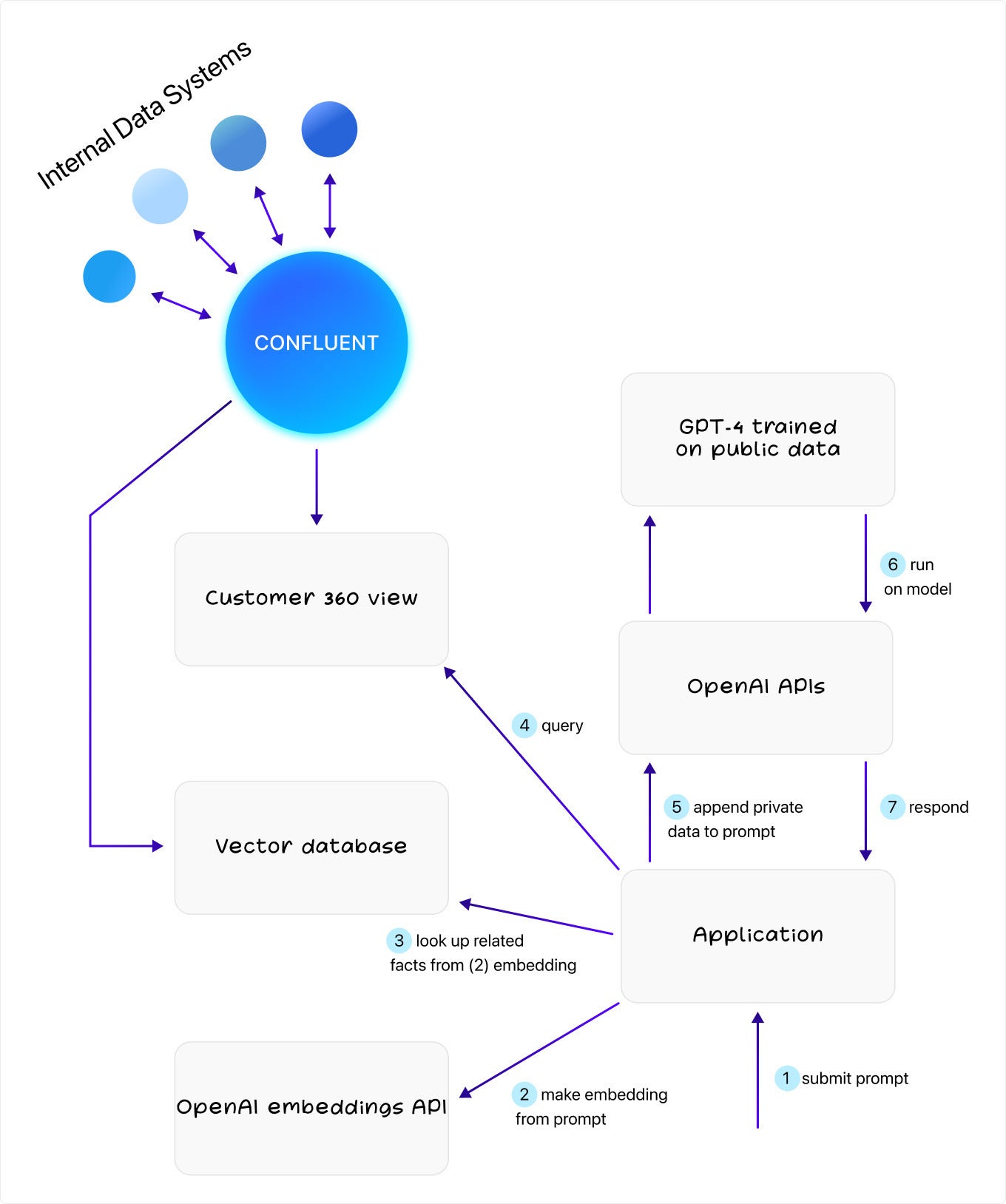
We’re now ready to bring all of this together into a working example. Here’s what the architecture looks like:
 Confluent
ConfluentThis architecture is hugely powerful because GPT will always have your latest information each time you prompt it. If your flight gets delayed or your terminal changes, GPT will know about it during your chat session. This is completely distinct from current approaches where the chat session would need to be reloaded or wait a few hours (or days) for new data to arrive.
And there’s more. A GPT-enabled agent doesn’t have to stop at being a passive Q/A bot. It can take real action on your behalf. This is again something that ChatGPT, even with OpenAI’s plugins, can’t do out of the box because it can’t reason about the aftereffects of calling your internal APIs. Event streams work well here because they can propagate the chain of traceable events back to you. As an example, you can imagine combining command/response event pairs with chain-of-thought prompting to approach agent behavior that feels more autonomous.
The ChatGPT Retrieval Plugin
For the sake of giving a clear explanation about how all of this works, I described a few things a bit manually and omitted the topic of ChatGPT plugins. Let’s talk about that now.
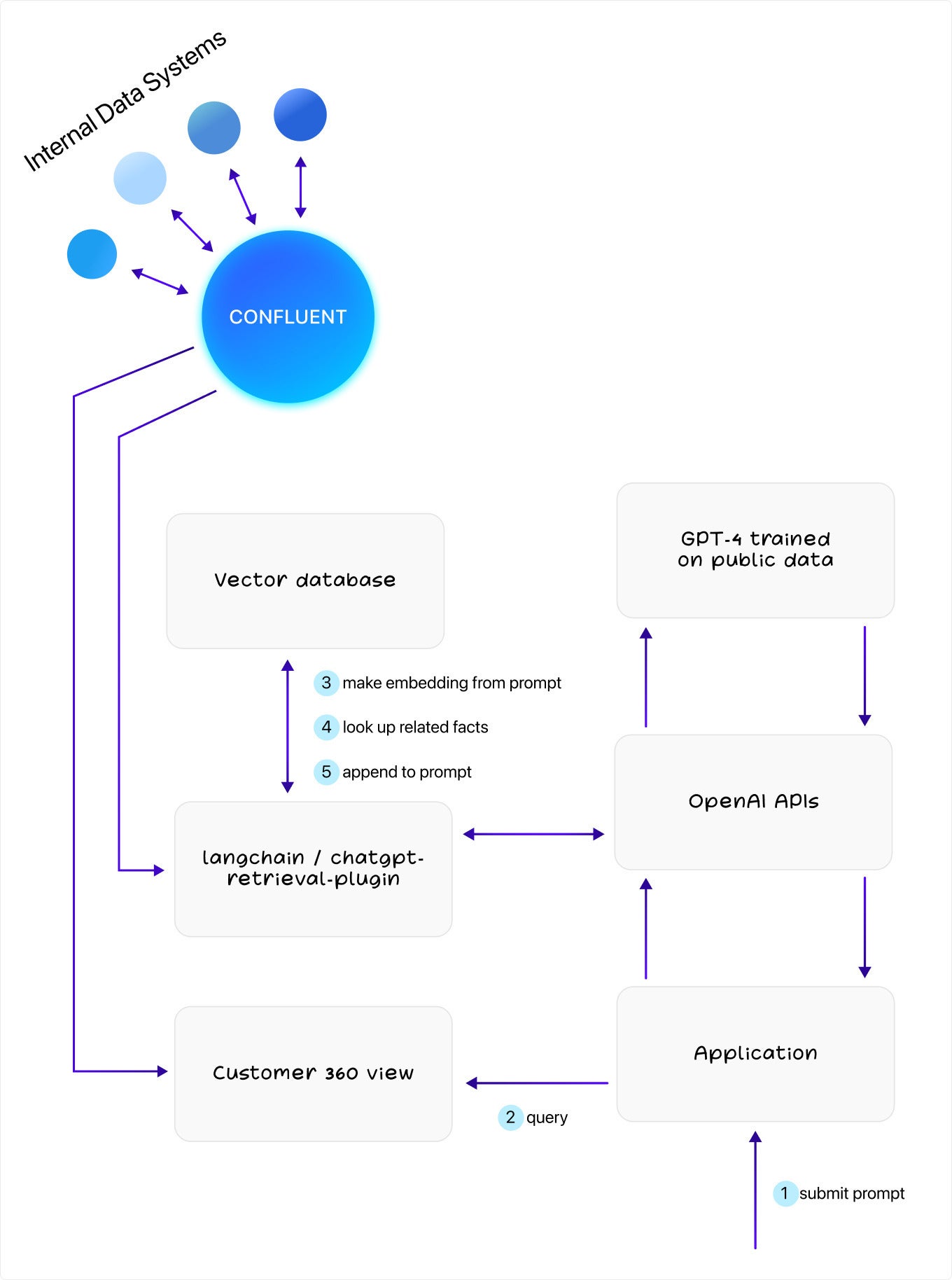
Plugins are a way to extend ChatGPT and make it do things it can’t do out of the box. New plugins are being added all the time, but one in particular is important to us: the ChatGPT Retrieval Plugin. The ChatGPT Retrieval Plugin acts as a sort of proxy layer between ChatGPT and the vector database, providing the glue that allows the two to talk to each other.
In my example, I illustrated how you’d receive a prompt, make an embedding, search the vector database, send it to GPT, and so on. Instead of doing that by hand, the ChatGPT Retrieval Plugin makes the right API calls back and forth on your behalf. This would allow you to use ChatGPT directly, rather than going underneath to OpenAI’s APIs, if that makes sense for your use case.
Keep in mind that plugins don’t yet work with the OpenAI APIs. They only work in ChatGPT. However, there is some work going on in the LangChain framework to sidestep that.
If you take this approach, one key change to the architecture above is that instead of connecting Apache Kafka directly to the vector database, you’d want to forward all of your customer 360 data to the Retrieval plugin instead—probably using the HTTP sink connector.
 Confluent
ConfluentWhether you connect these systems manually or use the plugin, the mechanics remain the same. Again, you can choose whichever method works best for your use case.
Capturing conversation and fine-tuning
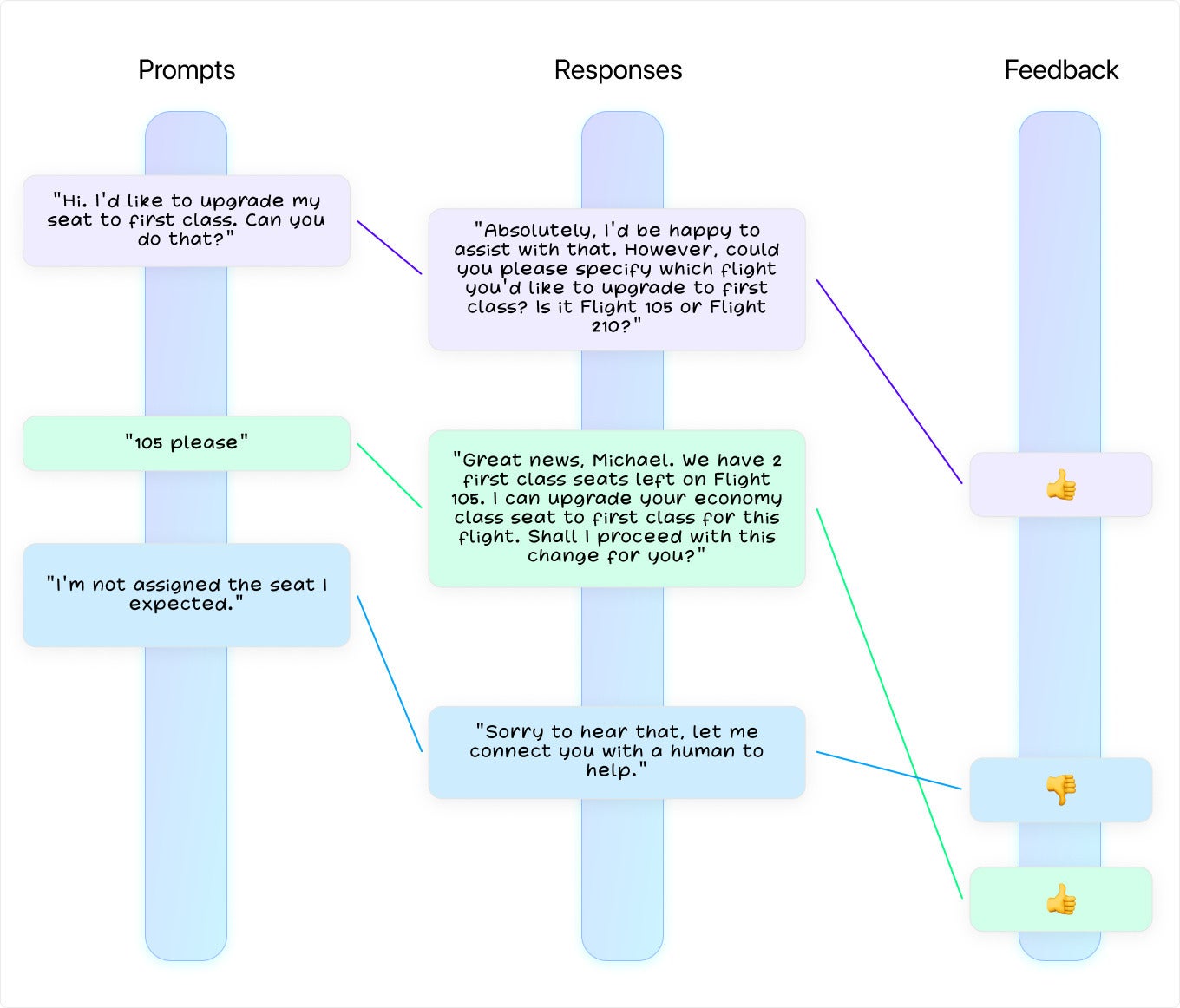
There’s one last step to tidy up this example. As the support agent is running, we want to know what exactly it’s doing. What’s a good way to do that?
The prompts and responses are good candidates to be captured as event streams. If there’s any feedback (imagine an optional thumbs up/down to each response), we can capture that too. By again using stream processing, we can keep track of how helpful the agent is from moment to moment. We can feed that knowledge back into the application so that it can dynamically adjust how it constructs its prompt. Think of it as a bit like working with runtime feature flags.
 Confluent
ConfluentCapturing this kind of observability data unlocks one more opportunity. Earlier I mentioned that there are two ways to modify how GPT behaves: search and fine-tuning. Until now, the approach I’ve described has centered on search, adding information to the start of each prompt. But there are reasons you might want to fine-tune, and now is a good time to look at them.
When you add information to the start of a prompt, you eat up space in the context window, eroding GPT’s ability to remember things you told it in the past. And with more information in each prompt, you pay more for tokens to communicate with the OpenAI APIs. The incentive is to send the least amount of tokens possible in each prompt.
Fine-tuning is a way of side-stepping those issues. When you fine-tune a machine learning model, you make small adjustments to its neural network weights so that it will get better at a particular task. It’s more complicated to fine-tune a model, but it allows you to supply vastly more information to the model once, rather than paying the cost every time a prompt is run.
Whether you can do this or not depends on what model you’re using. This post is centered around the GPT-4 model, which is closed and does not yet permit fine-tuning. But if you’re using an open-source model, you have no such restrictions, and this technique might make sense.
So in our example, imagine for a moment that we’re using a model capable of being fine-tuned. It would make sense to do further stream processing and join the prompt, response, and feedback streams, creating a stream of instances where the agent was being helpful. We could feed all of those examples back into the model for fine-tuning as human-reinforced feedback. (ChatGPT was partly constructed using exactly this technique.)
Keep in mind that any information that needs to be real-time still needs to be supplied through the prompt. Remember, fine-tuning only happens once offline. So it’s a technique that should be used in conjunction with prompt augmentation, rather than something you’d use exclusively.
Known limitations
As exciting as this is, I want to call out two limitations in the approach outlined in this article.
First, this architecture predominantly relies on the context window being large enough to service each prompt. The supported size of context windows is expanding fast, but in the short term, this is a real limiter.
The second is that prompt injection attacks are proving challenging to defend against. People are constantly finding new ways to get GPT to ignore its previous instructions, and sometimes act in a malicious way. Implementing controls against injection will be even more important if agents are empowered to update existing business data as I described above.
In fact, we’re already starting to see the practical choices people are making to work around these problems.
Next steps
What I’ve outlined is the basic framework for how streaming and GPT can work together for any company. And while the focus of this post was on using streaming to gather and connect your data, I expect that streaming will often show up elsewhere in these architectures.
I’m excited to watch this area continue to evolve. There’s clearly a lot of work to do, but I expect both streaming and large language models to mutually advance one another’s maturity.
Michael Drogalis is a principal technologist on the TSG team at Confluent, where he helps make Confluent’s developer experience great. Before joining Confluent, Michael served as the CEO of Distributed Masonry, a software startup that built a streaming-native data warehouse. He is also the author of several popular open source projects, most notably the Onyx Platform.
—
Generative AI Insights, an InfoWorld blog open to outside contributors, provides a venue for technology leaders to explore and discuss the challenges and opportunities of generative artificial intelligence. The selection is wide-ranging, from technology deep dives to case studies to expert opinion, but also subjective, based on our judgment of which topics and treatments will best serve InfoWorld’s technically sophisticated audience. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content.