






In previous articles we used Google’s PaLM API to generate a blog post and build a chatbot. In this article, we will explore how to generate text embeddings and perform semantic searches using the PaLM API. The PaLM API makes Google’s PaLM 2 large language model available to developers through the Google Cloud Vertex AI platform.
Unlike typical queries based on a string pattern or regular expressions, semantic search retrieves text with similar meanings. This is useful in building Q&A bots, text classification, recommendation systems, and machine translation.
Similarity search is based on finding the distance between two vectors and retrieving the closest. The vectors are numerical representations of words or phrases. Text is converted into vector embeddings by passing it through a machine learning model that is trained to translate semantic similarity into a vector space. In a text embedding, vectors of words and phrases with similar meanings will be located near one another.
For this tutorial, we will use textembedding-gecko, a model based on the PaLM 2 foundation model, to generate text embeddings.
For a detailed guide to setting up the environment and configuring the SDK, please refer to my previous article. This guide assumes you completed that tutorial.
To perform the semantic search, we will download the TREC (Question Classification) dataset from Kaggle. Download the zip file and place the test.csv file in the data directory. We will load this file and send a subset of the questions to the PaLM 2 model to generate text embeddings.
The library, vertexai.preview.language_models, has multiple classes including ChatModel, TextEmbedding, and TextGenerationModel. Here we will focus on the TextEmbeddingModel to generate the word embeddings.
As a first step, let’s import the appropriate classes from the library.
from vertexai.preview.language_models import TextEmbeddingModel import pandas as pd import numpy as np
We will create a function that accepts text and returns the associated embeddings. This function will be invoked for each row of a Pandas DataFrame.
def text_embedding(text) -> None:
model = TextEmbeddingModel.from_pretrained("textembedding-gecko@001")
embeddings = model.get_embeddings([text])
return [embedding.values for embedding in embeddings]Next we will define the function that performs the dot product of two vectors and returns the value. The higher the value, the closer the meaning.
def vector_similarity(vec1, vec2): return np.dot(np.squeeze(np.array(vec1)),np.squeeze(np.array(vec2)))
Assuming you downloaded test.csv and placed the file in the data directory, we will load that into a Pandas DataFrame.
df=pd.read_csv('./data/test.csv')Next, we will extract the column that contains the question and create a subset of the DataFrame with the first 10 rows. You can increase this number to load more text but it will slow down the execution because we call the PaLM 2 endpoint for each row.
df=df[['text']] df=df.head(10)
Printing the DataFrame shows the first 10 rows.
df
 IDG
IDGOur goal is to retrieve a question from this list that has a similar meaning to the prompt sent by the user.
Let’s invoke the PaLM 2 API and store the output in a new column added to the DataFrame.
df=df.assign(token=(df["text"].apply(lambda x : text_embedding(x))))
The above line invokes the function text_embedding for each row to invoke the API and stores the result in the token column associated with the text.
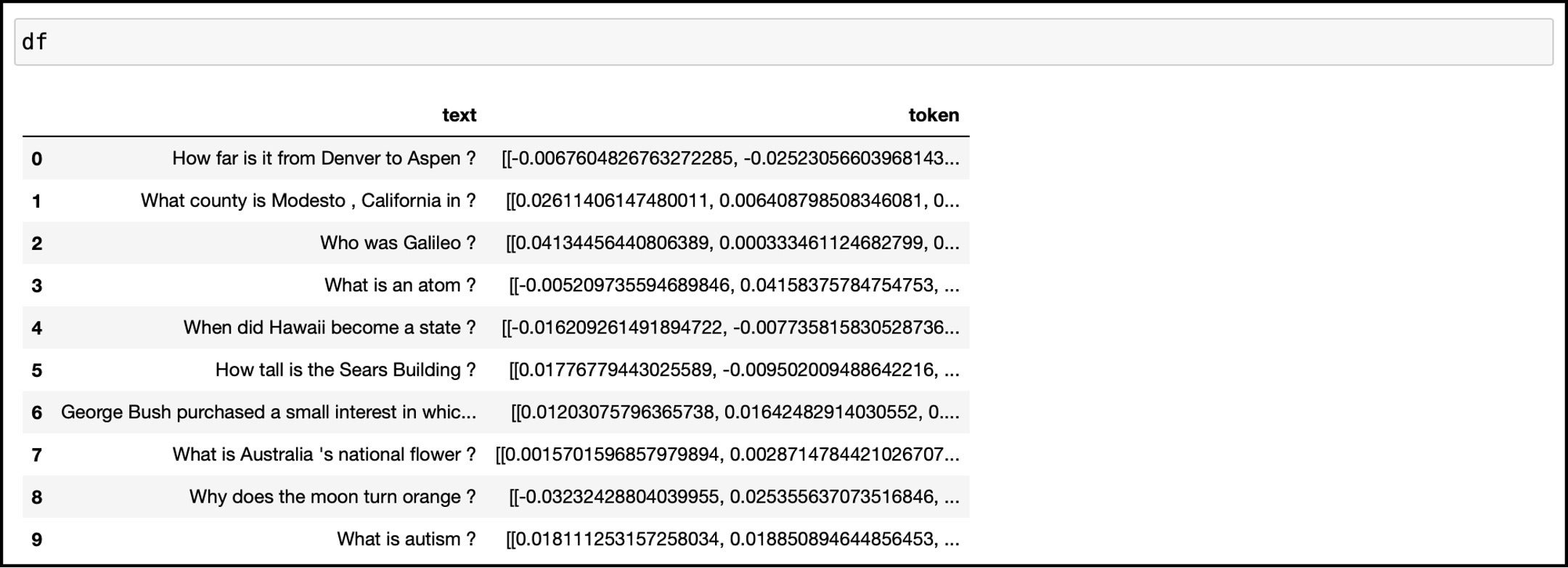
Let’s print the new DataFrame to check if the associated vectors are added to each row.
df
 IDG
IDGNotice that the column token contains a vector associated with the corresponding text.
When we search for a question that has a similar meaning to our query, we will perform a dot product of the vector associated with the query with each vector in the DataFrame. Whichever has the highest value has a similar meaning to the prompt.
Question 3 in the DataFrame is “What is an atom ?” Let’s send the search phrase “Tell me about atom,” which means the same.
First we’ll need to generate the embeddings for the phrase by calling the API.
prompt = "Tell me about atom" prompt_embedding=text_embedding(prompt)
Then we will call the function vector_similarity to perform the dot product of the vectors and store it as a new row under the column similarity.
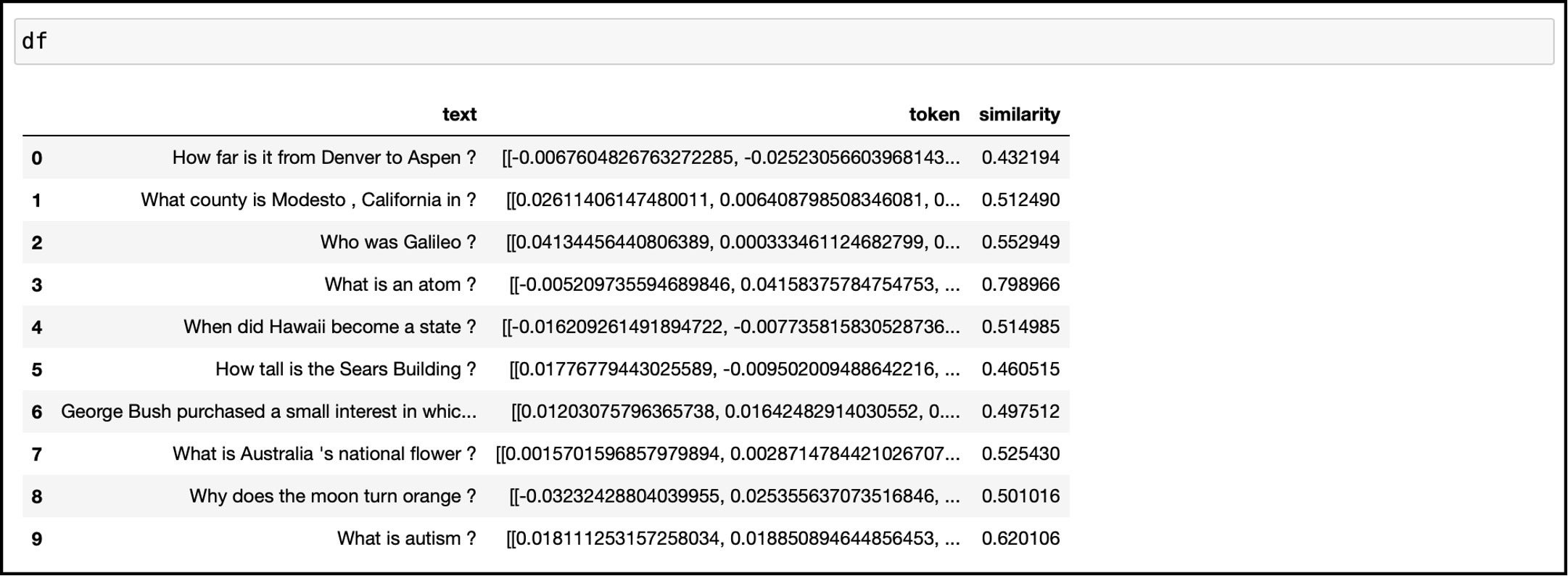 IDG
IDGAs you can see, row 3 has the highest value of 0.79, which means that “What is an atom?” has the most similar meaning to our search phrase.
Let’s sort the DataFrame and retrieve the text associated with the highest similarity score.
df.nlargest(1,'similarity').iloc[0]['text']
 IDG
IDGFinally, let’s try the phrase “What’s the reason for the moon to become amber?”
prompt = "what's the reason for the moon to become amber?" prompt_embedding=text_embedding(prompt) df["similarity"]=df["token"].apply(lambda x: vector_similarity(x,prompt_embedding[0])) df.nlargest(1,'similarity').iloc[0]['text']
As shown below, this prompt returns the question from row 8, which is “Why does the moon turn orange?”
 IDG
IDGBelow is the complete code for your reference.
from vertexai.preview.language_models import TextEmbeddingModel
import pandas as pd
import numpy as np
def text_embedding(text) -> None:
model = TextEmbeddingModel.from_pretrained("textembedding-gecko@001")
embeddings = model.get_embeddings([text])
return [embedding.values for embedding in embeddings]
def vector_similarity(vec1, vec2):
return np.dot(np.squeeze(np.array(vec1)),np.squeeze(np.array(vec2)))
df=pd.read_csv('./data/test.csv')
df=df[['text']]
df=df.head(10)
df=df.assign(token=(df["text"].apply(lambda x : text_embedding(x))))
prompt = "Tell me about atom"
prompt_embedding=text_embedding(prompt)
df["similarity"]=df["token"].apply(lambda x: vector_similarity(x,prompt_embedding[0]))
df.nlargest(1,'similarity').iloc[0]['text']
prompt = "what's the reason for the moon to become amber?"
prompt_embedding=text_embedding(prompt)
df["similarity"]=df["token"].apply(lambda x: vector_similarity(x,prompt_embedding[0]))
df.nlargest(1,'similarity').iloc[0]['text']This concludes my miniseries on Google’s PaLM API. We explored text completion, chat completion, and similarity search using the PaLM 2 large language model available in Google Cloud Vertex AI.