






Do you have data sets scattered all over the place: multiple local folders, Git repos, cloud services, databases? Is it sometimes difficult to remember which data set contains what, and where they're all stored?
Thanks to the pointblank R package, you can document your data sets via R scripts in a report that not only describes column types and data provenance, but also includes where the data set is stored, how it gets updated, what if any key projects use it, and anything else you'd like to add. Since each data dictionary report is generated by an R script, you can include whatever metadata fields are important to you, then use that same structure for each data set.
Once you've created the reports, you can write another script in a Quarto or R Markdown file to add all those files to single, searchable data dictionary catalog—regardless of where each data set is stored.
Here's how it all works.
Create a data dictionary report with R and pointblank
To document a data set with pointblank in R, you start by creating a pointblank informant object with the create_informant() function.
Let's use a simple data set of US state population data to see it in action.
The code in Listing 1 loads the pointblank and dplyr packages and uses the rio package to read the file into R. Feel free to use whatever import function you like best for importing CSV files—readr::read_csv(), vroom::vroom(), data.table::fread(), base R's read.csv(), etc.
Listing 1. Loading pointblank and rio
library(pointblank) # install with install.packages if needed
library(rio)
library(dplyr)
state_pops <- import("https://raw.githubusercontent.com/smach/SampleData/main/states.csv")
This next line of code creates a basic, bare-bones informant. create_informant() takes a data frame or several types of database tables as its first, mandatory argument:
my_informant <- create_informant(state_pops)
The informant object comes equipped with a rather nice print method, which you can see by running either print(my_informant) or simply my_informant in your R console.
You should see something like what's shown in Figure 1.
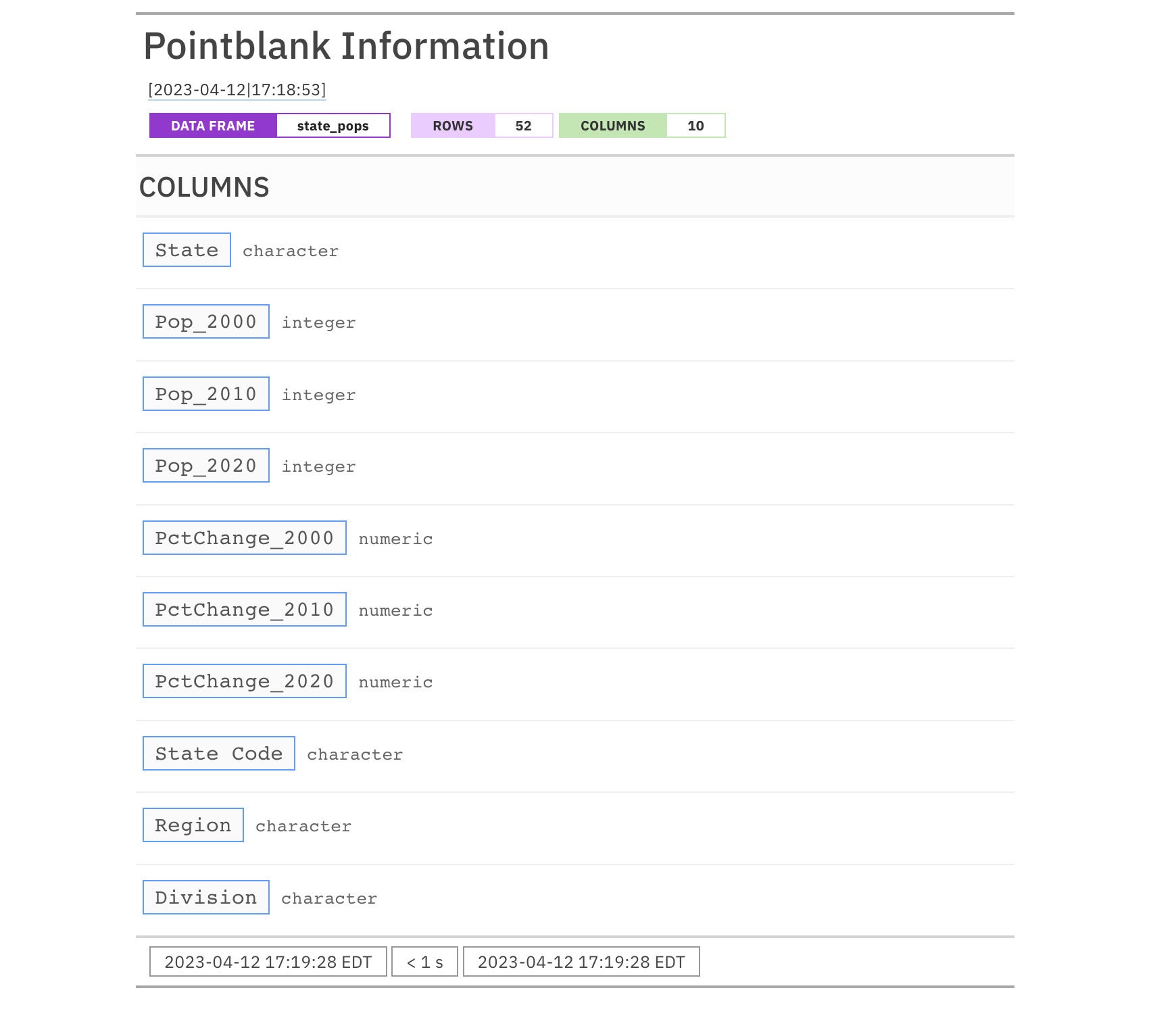 S
S
Figure 1. An absolute basic pointblank data report.
Add optional informant arguments
So far, this doesn't tell you more about your data frame than base R's str() or dplyr::glimpse()—although it's in a nicer format. So, let's start adding information.
create_informant() can take a few optional arguments for metadata, including tbl_name, label, and lang. The lang argument denotes the language used for summary table text—it defaults to English but includes options for Spanish, Chinese, German, French, Portuguese, and several others. Try create_informant(states, lang = "es") to see what a report in Spanish looks like, for example.
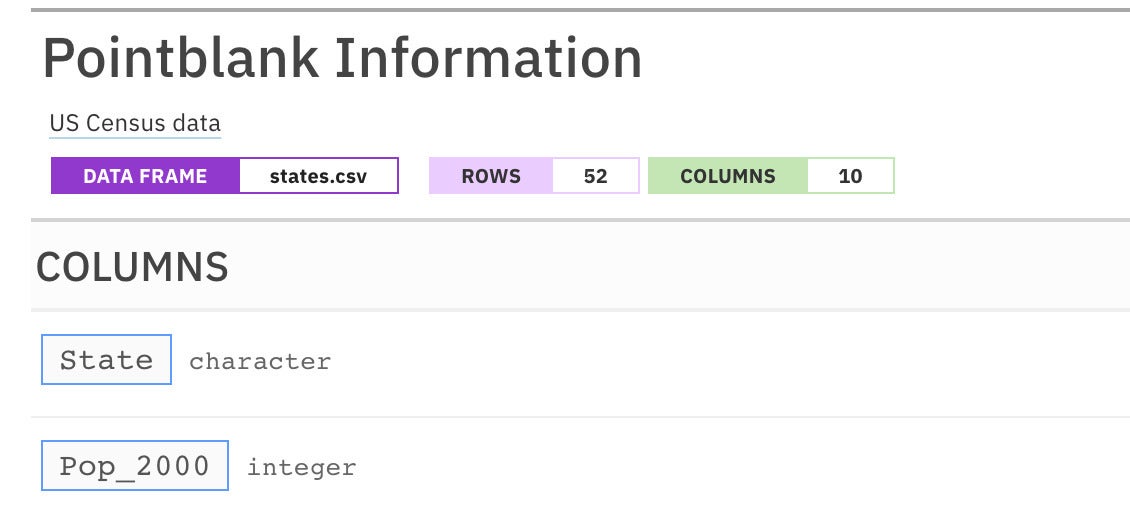
I generally use the tbl_name argument for the name of the file where I store the data set. I don't have a philosophy for the label, which appears in tiny print below the title. Here's a simple example:
my_informant <- create_informant(state_pops,
tbl_name = "states.csv", label = "US Census data")
my_informant
Figure 2 shows the informant with tbl_name and label added.
 Screen shot by Sharon Machlis
Screen shot by Sharon Machlis
Figure 2. An informant with table name and label added.
The tbl_name and label are now below the headline.
Build up your report by layers
Somewhat like a ggplot2 graphic, you can beef up and customize the basic informant with additional layers. But instead of adding on ggplot2 geom_ and theme_ functions, you can use a family of pointblank info_ functions. I use these three most often:
- info_tabular() adds useful metadata at the top of the data dictionary report—things like a data set description, info on how it updates, and where it's stored if your dictionary covers more than one platform. You can customize this however you'd like.
- info_columns() allows you to add text descriptions to a data columns along with the column name and data type that appear by default. That description can be static text, such as "US Census Bureau region." Or, it can include dynamically generated values from the data set, such as "Daily dates from {starting_date} to {ending_date}."
- To include dynamic values, you use the info_snippet() function to create what
pointblankcalls snippets (not to be confused with RStudio code snippets). We'll take a look atinfo_snippet()in a bit.
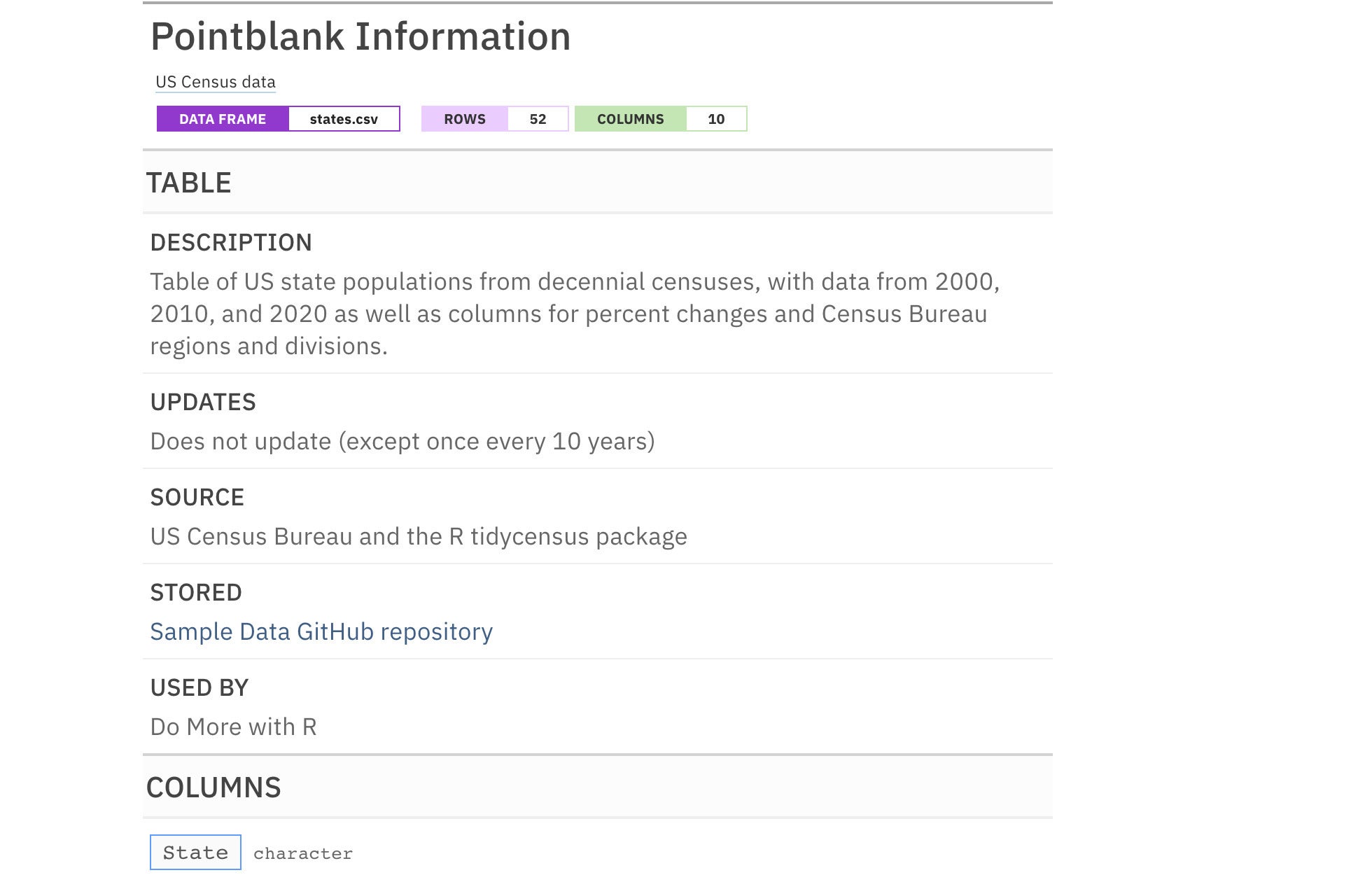
Now, though, I'll start by adding more metadata to the top of my report with info_tabular(). I've chosen to add the fields Description, Updates, Source, Stored, and Used By, but you can add any fields you want here.
Listing 2. Adding metadata with the info_tabular() function
my_informant <- my_informant %>%
info_tabular(
Description = "Table of US state populations from decennial censuses, with data from 2000, 2010, and 2020 as well as columns for percent changes and Census Bureau regions and divisions.",
Updates = "Does not update (except once every 10 years)",
Source = "US Census Bureau and the R tidycensus package",
Stored = "[Sample Data GitHub repository](https://github.com/smach/SampleData)",
`Used by` = "Do More with R"
)
I suggest creating a template file you can copy and fill in, or an RStudio code snippet, with the info_tabular() fields you want in your data dictionary. That way, you can standardize your metadata.
Many pointblank arguments will take Markdown syntax such as [text to hyperlink](https://url.com). As an example, Stored in Listing 2 creates a hyperlink to my repository.
If you run the above info_tabular() code chunk or something similar and print the informant, you should see output similar to what's shown in Figure 3 at the top of your report.
 Screenshot by Sharon Machlis
Screenshot by Sharon Machlis
Figure 3. An informant with custom metadata fields added.
Add column details
Next, I'll add details about the data set's columns. I don't always describe every column in a data set when the column names seem clear, although admittedly that's not best practice. For example, "Pop_2020" in a data set of Census population information seems pretty self-explanatory.
You can describe as many or as few columns as you'd like in an informant; those details aren't required.
To add a static text description to a column, you use the info_columns() function, which has the following syntax:
my_informant <- my_informant %>%
info_columns(
columns = "column_name",
info = "My description of the column"
)
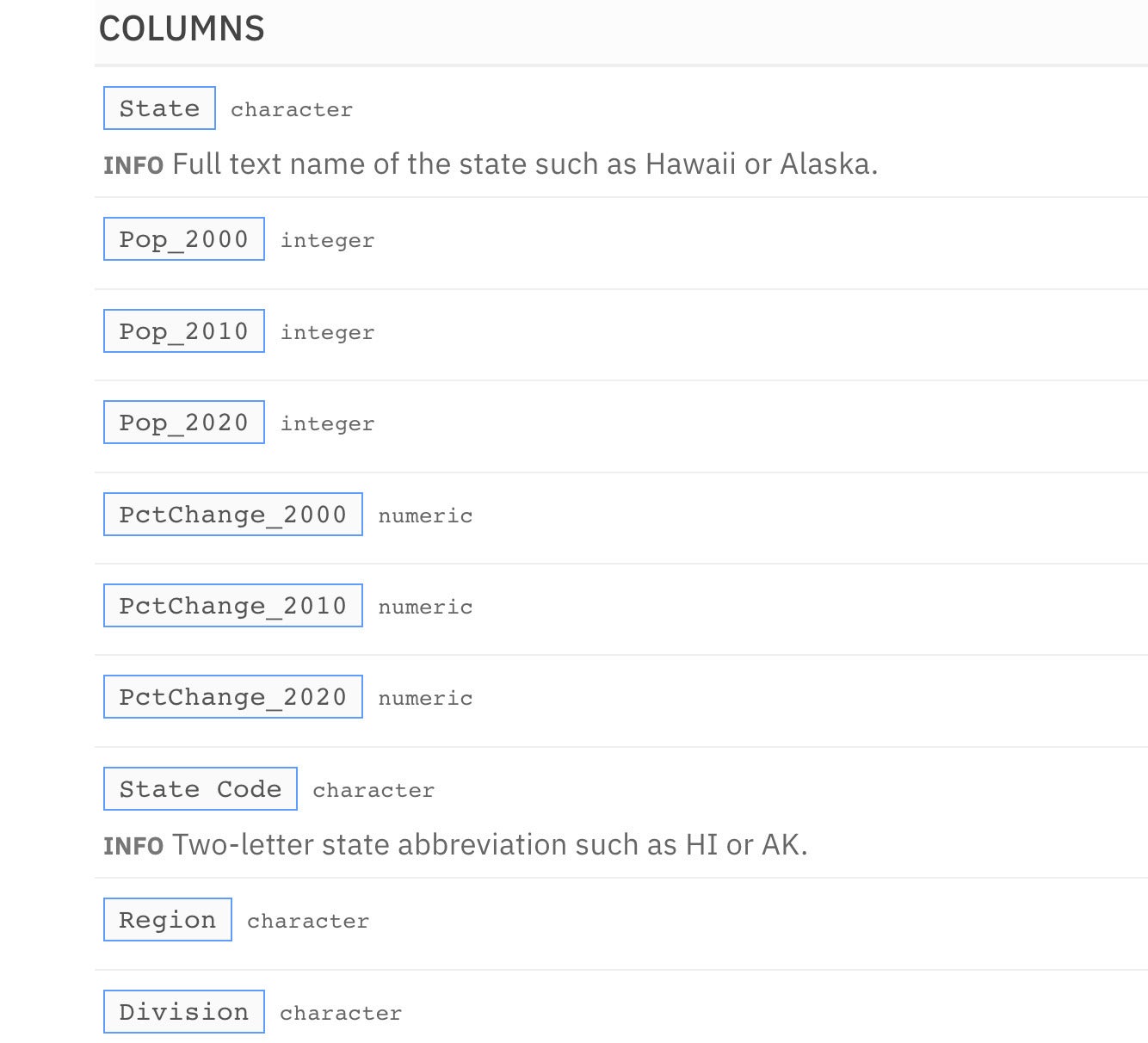
Each info_columns() description is a new layer added to the informant via a %>% or |> pipe. For example, this description
my_informant <- my_informant %>%
info_columns(
columns = "State",
info = "Full text name of the state such as Hawaii or Alaska."
) %>%
info_columns(
columns = "State Code",
info = "Two-letter state abbreviation such as HI or AK."
)
results in adding the following to the informant's columns section, shown in Figure 4.
 Screenshot by Sharon Machlis
Screenshot by Sharon Machlis
Figure 4. The pointblank informant with column information added.
You can add the same description to multiple columns, like so:
my_informant <- my_informant %>%
info_columns(
columns = c("PctChange_2000", "PctChange_2010", "PctChange_2020"),
info = c("Percent population change from prior decennial census. Format already multiplies the decimal by 100, so, for example, a 10.1% change is represented as the number 10.1.")
)
The following snippet adds the same text description to all three PctChange columns.
The columns argument also can take dplyr "tidy select" selection helpers like starts_with(), in which case you could rewrite the above as
my_informant <- my_informant %>%
info_columns(
columns = starts_with("PctChange"),
info = "Percent population change from prior decennial census. Format already multiplies the decimal by 100, so, for example, a 10.1% change is represented as the number 10.1."
)
Other available column selection helpers are ends_with(), contains(), matches() to match a regular expresion, and everything() for all columns.
You can add more than one info_columns() description to a column. That means you can have boilerplate text for several columns such as above and specific text for just one of those columns, as in the following example for the PctChange_2020 column:
my_informant <- my_informant %>%
info_columns(
columns = "PctChange_2020",
info = " This column shows the percent change from the 2020 Census compared with 2010."
)
Running both of the info_columns() code chunks produces the following for the percent change columns. All three columns have the same explanatory text, but PctChange_2020 had additional text added:
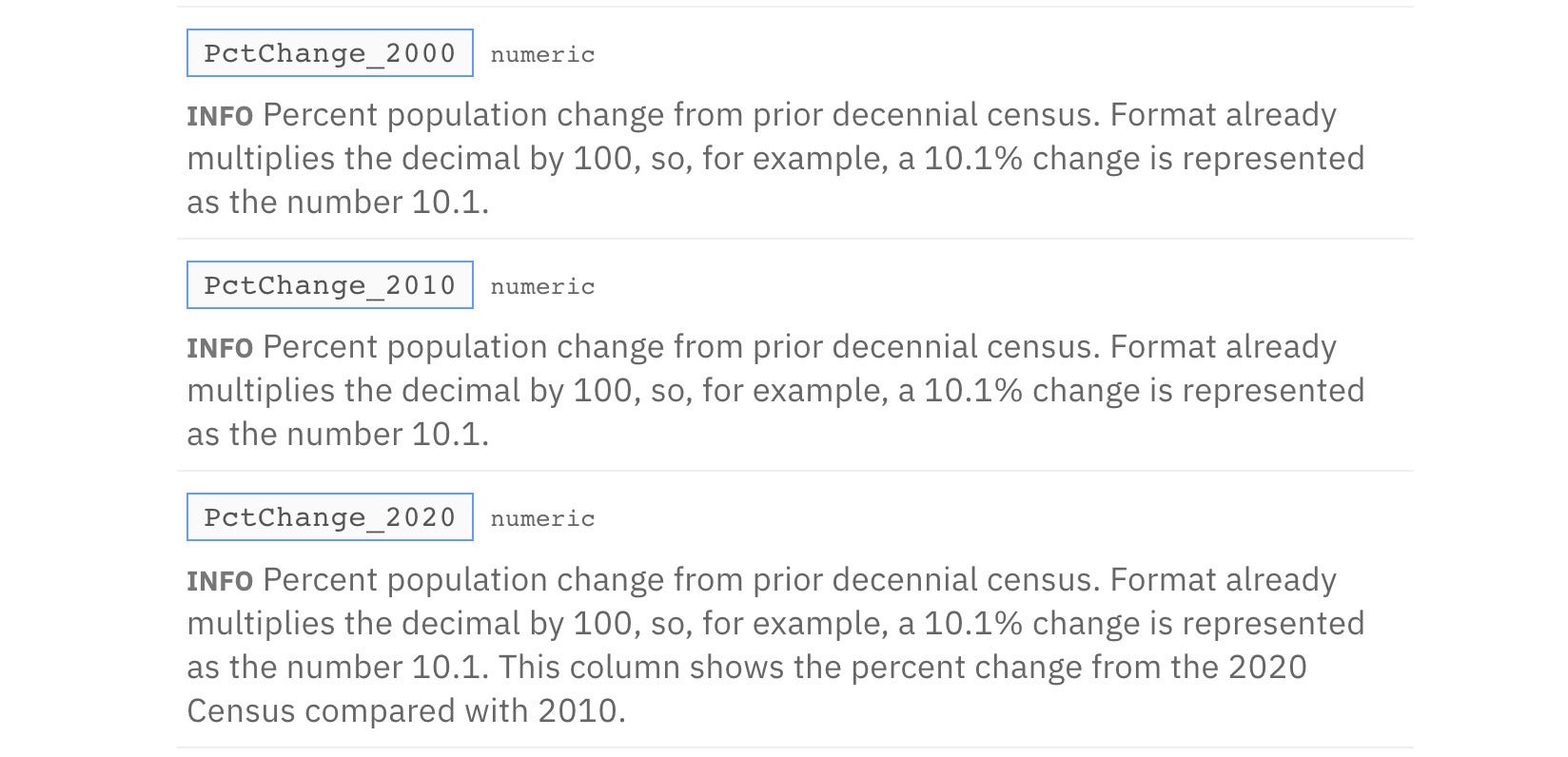 Screen shot by Sharon Machlis
Screen shot by Sharon Machlis
Figure 5. Result of running info_columns() on three columns and a second info_columns() on one of them
Add calculated values to your report
You may find it useful to add calculated values to your data set descriptions. For example, what are all the possible Census Bureau Region and Division values? What were the highest and lowest percent changes in the Pop_2020 data set?
You could add those manually to static text. But besides being clunky, that might not work well for data set values that frequently update. Instead, you can use pointblank snippets to add calculations from your data to informant descriptions. Here's an example:
my_informant <- my_informant %>%
info_snippet(
snippet_name = "name_of_my_snippet",
fn = ~ R CODE GOES HERE
)
info_snippet() stores a calculated value in name_of_my_snippet. You can then use that snippet value inside an info_column() info argument by putting the snippet name in braces. That is easier to see in code than to explain:
my_informant <- my_informant %>%
info_columns(
columns = "the_column_name",
info = "Info about the column and {name_of_my_snippet} interesting data value"
)
The R code syntax for snippet calculations is generally something like:
fn = ~ . %>% .$column_name %>% more R code here
The ~ says, "This is a formula which will not be evaluated right now." The . represents the data set being used by the informant.
To execute the snippets so values are calculated, you need to call pointblank's incorporate() function on an informant. As an example, to get the median value for my data set's Pop_2020 column, I could add the code in Listing 3 to my informant:
Listing 3. Executing a snippet calculation
my_informant <- my_informant %>%
info_snippet(
snippet_name = "median_2020",
fn = ~ . %>% .$Pop_2020 %>% median()
) %>%
info_columns(
columns = "Pop_2020",
info = "State population from the 2020 Census. Median value is {median_2020}"
)
# View results:
my_informant %>%
incorporate()
Above I created a snippet called median_2020 and then used that value by putting its name in braces when I was adding a description to a column.
Unfortunately, as far as I know, there's no way to use a single info_snippet() function call on multiple columns at once. So if you wanted median values for multiple columns, you'd need to create multiple info_snippets.
Because snippets aren't calculated until incorporate() runs, the order of informant "layers" doesn't matter. info_columns() using a snippet can come before the info_snippet() code that creates the snippet. So, this would also work:
my_informant <- my_informant %>%
info_columns(
columns = "Pop_2020",
info = "State population from the 2020 Census. Median value is {median_2020}"
) %>%
info_snippet(
snippet_name = "median_2020",
fn = ~ . %>% .$Pop_2020 %>% median()
)
That code generates this for the Pop_2020 Info: "State population from the 2020 Census. Median value is 4,371,546.00."
Built-in snippet convenience functions
In addition to creating your own snippet R code, there are several built-in snippet convenience functions. I use three of them pretty often: snip_highest() for a column's maximum value, snip_lowest() for minimum value, and snip_list() for a column's unique values. There's also snip_stats() for a statistical summary of the column. I don't often use that one but you might.
To use them, you add the convenience function to the fn argument. For example, to add all existing Division values to my data set's Division column, I could use snip_list():
my_informant <- my_informant %>%
info_snippet(
"census_divisions",
fn = snip_list("Division", limit = 10, sorting = "inseq")
) %>%
info_columns(
"Division",
info = "Census Bureau divisions. Possible values: {census_divisions}"
) %>%
incorporate()
Figure 6 is a partial look at the updated informant with all possible values in the Division column.
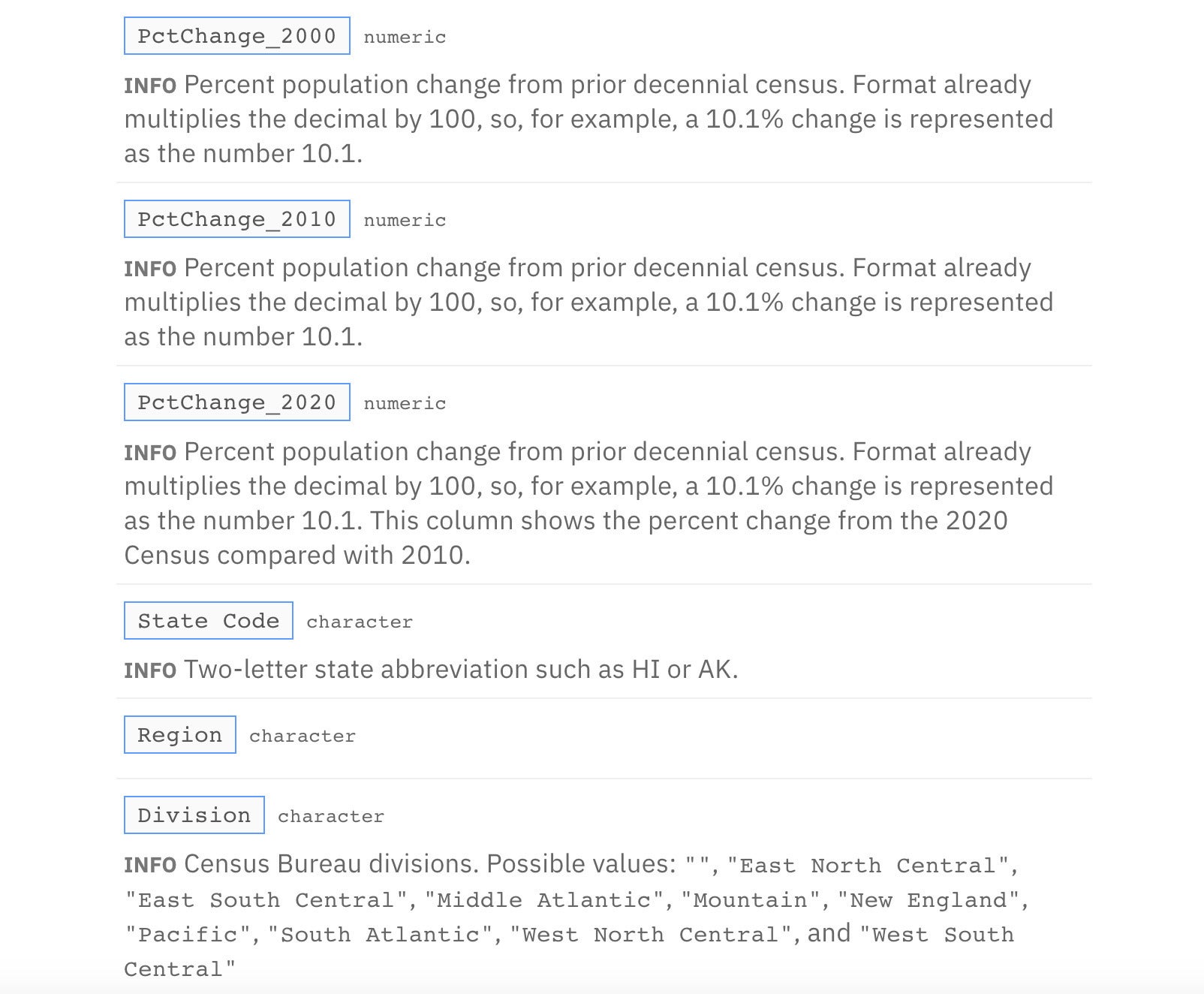 Sharon Machlis
Sharon Machlis
Figure 6. Column descriptions for the informant.
A few more commands worth knowing about:
snip_list()displays a maximum of five values by default. So, if you want all values to display and there are more than five, set a new limit argument as I did above.snip_list()sorting has three options: the default, which is the order items appear in the data set; infreq, by decreasing frequency of the items; or inseq, which is alphabetical.- Once you've finished creating an
informant, you can turn it into an HTML report withget_informant_report()and save it to an HTML file withexport_report(). get_informant_report()lets you set a report title.export_report()has options for report file name and directory path, if desired, such as in this example:myreport <- get_informant_report(my_informant, title = "US State Populations (decennial census data)") export_report(myreport, filename = "state_pops.html", path = "www")
More dynamic data sets
This example report documents a data set that doesn't update, except maybe once every 10 years. For data sets that are frequently updated via R scripts, you could add pointblank code to those scripts to create a dynamic report with useful, up-to-date info at a glance.
For instance, I have an auto-updating daily Boston temperature CSV file. I could use snippet values to include the latest date in the data set. Snippet values can be used in the top info_tabular() section of a report as well as in individual column descriptions, so I can add a snippet values to a description field at the top of my report. For example, the code in Listing 4 downloads my daily temperature data set, creates a basic informant, and then adds snippets for start_date and end_date:
Listing 4. Create an informant and add snippets
bos_temps <- rio::import("https://raw.githubusercontent.com/smach/SampleData/main/BOS_temperatures.csv")
temp_informant <- create_informant(bos_temps, tbl_name = "BOS_temperatures.csv",
label = "Weather data") %>%
info_tabular(
Description = "Table of daily Boston high and low temperatures as well as min, max,
and average 'feels like' temps starting {start_date} through {end_date}.
_Not_ official National Weather Service data.",
Updates = "Auto updates daily from script on my cloud server",
Source = "[Iowa State University's Iowa Environmental Mesonet METAR database](https://mesonet.agron.iastate.edu/request/download.phtml?network=MA_ASOS)",
Stored = "[Sample Data GitHub repository](https://github.com/smach/SampleData)",
`Used by` = "Do More with R"
) %>%
info_snippet(
snippet_name = "start_date",
fn = snip_lowest("day")
) %>%
info_snippet(
snippet_name = "end_date",
fn = snip_highest("day")
) %>%
incorporate()
Here's a view of the top of this informant:
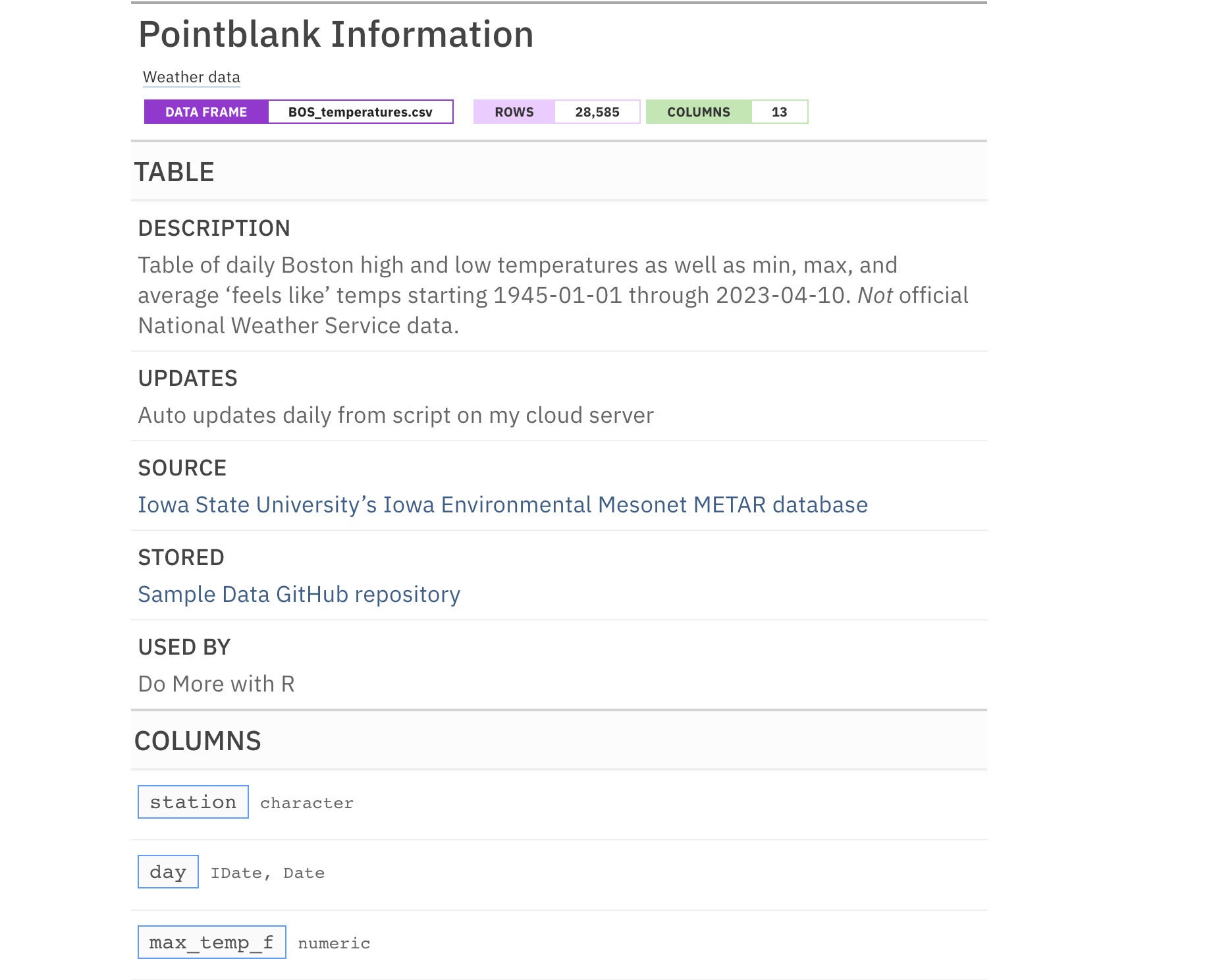 Sharon Machlis
Sharon Machlis
Figure 7. A pointblank report with dynamic data in the description.
Add pointblank data documentation code to the R script that updates the data set, and your report will stay up to date. Add multiple reports to a single data dictionary, and you'd have one place to scan the condition of all your data.
Create a single data dictionary catalog
So far, we've documented one data set at a time. The pointblank package doesn't have built-in functions to create a single data dictionary catalog from multiple data set reports. However, you can build one yourself.
My preferred method at the moment is with an R Markdown or Quarto document that includes code to create a searchable table from all my pointblank reports. I have a separate script that pulls together data for the table from all the HTML report files, and then stores that for use in the document that generates my searchable table. One key to organizing my reports this way is to make sure I have a copy of every report in one place, regardless of where the data is stored.
I generate data for my table by "scraping" each report's HTML file. Below are the two scripts I use.
The extract_report_info() function
The first script, shown in Listing 5, extracts all the info I need from a pointblank HTML report, where report_file is the name of a pointblank HTML file and report_path is the folder with the report. The code uses rvest package functions to extract various text information based on HTML CSS selectors. You can read more about this at the rvest package website.
Note that I hard-coded the names of all the metadata fields I include in my reports inside my info_tabular() function. If you want to use my extract_report_info() function and you use different fields at the top of your reports, make sure to change the fields:
Listing 5. Create a report with the extract_report_info() function
extract_report_info <- function(report_file, report_path = "www") {
report_file <- paste0(report_path, "/", report_file)
my_html <- read_html(report_file)
Title <- html_element(my_html, ".gt_title") %>%
html_text2()
metadata <- html_elements(my_html, ".gt_from_md") %>%
html_text2()
Description <- get_table_metadata_fields("DESCRIPTION", metadata)
Source <- get_table_metadata_fields("SOURCE", metadata)
Updates <- get_table_metadata_fields("UPDATES", metadata)
UsedBy <- get_table_metadata_fields("USED BY", metadata)
Columns <- html_elements(my_html, "code:nth-child(1)") %>%
html_text2() %>%
paste(. , collapse = ", ")
Title = glue("<a title='{Title}' href='{report_file}'>{Title}</a>")
report_info <- data.frame(Title = Title, Description = Description, Source = Source, Updates = Updates, UsedBy = UsedBy, Columns = Columns)
return(report_info)
}
get_table_metadata() is a helper function. I could have included it in the main extract_report_info() function, but I chose to separate it out so the main function wouldn't get too unwieldy.
get_table_metadata_fields <- function(field, char_vector) {
mytext <- char_vector[grepl(field, char_vector)]
mytext <- gsub(field, "", mytext, fixed = TRUE)
mytext <- gsub("\n", "", mytext, fixed = TRUE)
return(mytext)
}
The map_df function
Now that I have functions to extract the data I want from one report, I can create a single data frame from all my separate HTML report files with the map_df function from purrr. To start, I load the rvest, glue, and purrr packages (don't forget that part) and then run
table_data <- purrr::map_df(dir("www"), extract_report_info) %>%
arrange(Title)
I can then save the data with save() or saveRDS() for use in my Quarto document, such as saveRDS(table_data, "data_dictionary_table_data.Rds").
A Quarto document creating a searchable table from this data can be as simple as:
---
title: "Sample Data Dictionary"
format:
html:
page-layout: full
editor: source
---
```{r}
#| echo: false
table_data <- readRDS("data_dictionary_table_data.Rds")
library(DT)
datatable(table_data, escape = FALSE, filter = 'top', rownames = FALSE)
```
Render the document by clicking the Render button in RStudio or by running quarto render index.qmd in a terminal, and you've got a local copy of your data dictionary. You can view it in a web browser by opening the index.html file.
Publish your data dictionary on the web
If you want to share your data dictionary, it needs to live outside of your local hard drive. One Quarto-friendly option for publishing a data dictionary online is a GitHub repository. The advantage to GitHub is that you can use GitHub Pages to display the HTML files from a rendered Quarto document.
You can also use GitHub Actions to automate keeping data descriptions updated.
If you're not familiar with using Git and GibHub with R, Happy Git and GitHub for the useR by Jennifer Bryan is an excellent free online resource. The Quarto project has several sample GitHub Actions for use rendering documents. And if you want a complete how-to for GitHub Actions beginners, check out Beatriz Milz's Running Code While We're Sleeping: Introduction to GitHub Actions for R users presentation at R-Ladies Abuja, Nigeria.
There are other alternatives that would work, such as BitBucket Pipelines pushing to another display platform, cron jobs on a cloud server, or even just a local project where you run a script manually or via local scheduling.
For an enterprise data catalog, choices include data-focused Posit Connect or any cloud platform that can run R scripts on a schedule and display an HTML file that contains JavaScript.
You can see a sample small data catalog on GitHub Pages at my Sample Data repository, shown in Figure 8. There, I use the reactable package to create a table where some columns don't display by default but are still searchable, making the table easy to scan for basics. (Code for that document is in the repo's index.qmd file. You can see a tutorial on creating such tables at How to create tables in R with expandable rows.)
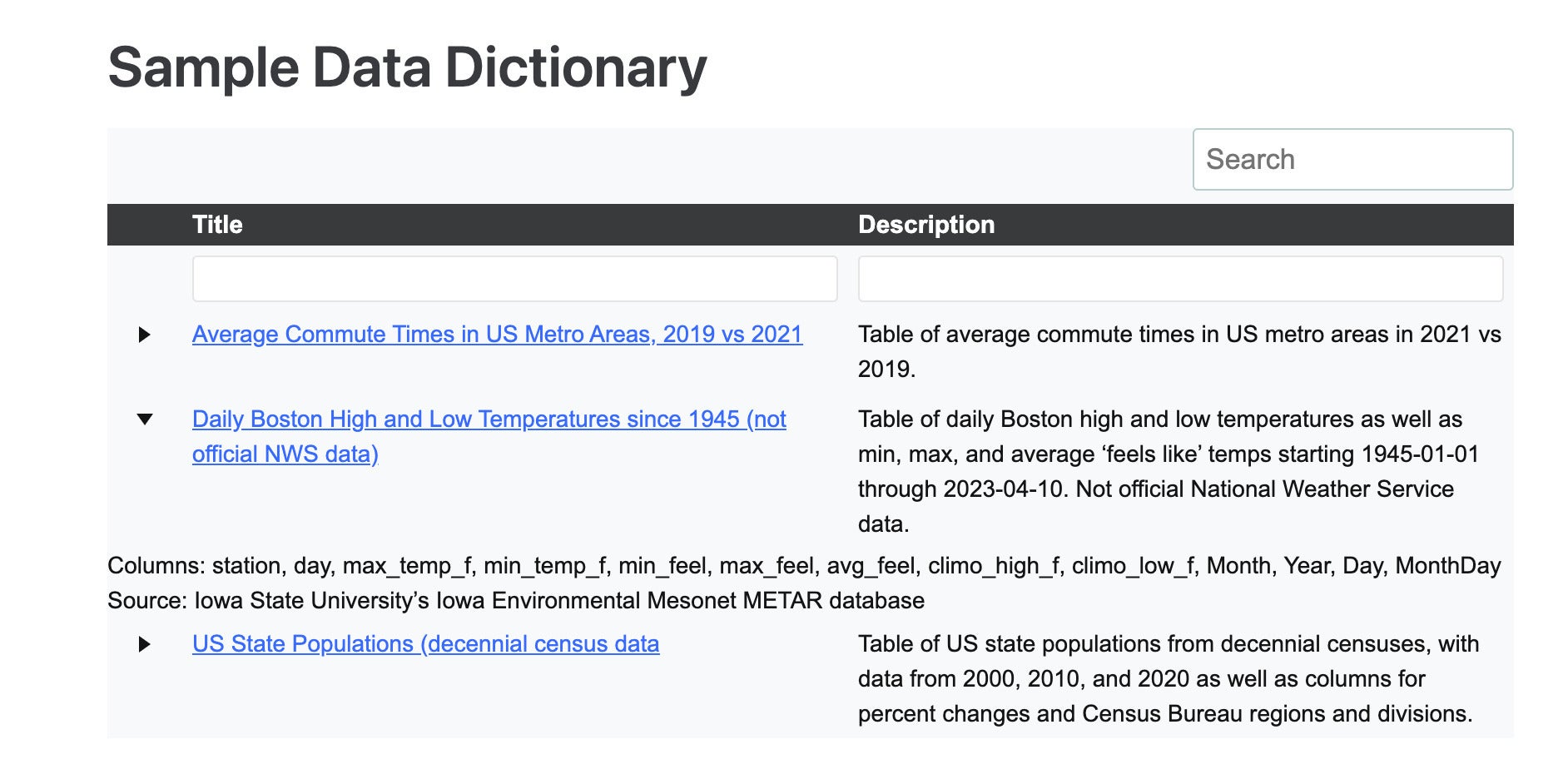 Sharon Machlis
Sharon Machlis
Figure 8. A reactable table with collapsible columns.
Publish your Quarto document on GitHub Pages
Quarto documentation explains how to use GitHub Pages for publishing an index.qmd file. The basics: Add a _quarto.yml file to your repository containing the following:
project:
type: website
output-dir: docs
In addition, add a .nojekyll file to the root of your repo which contains touch .nojekyll if you're working on a Mac or Linux system or copy NUL .nojekyll on a Windows PC.
You also need to configure your repository on GitHub to publish from a docs directory on your repo's main branch, by going to the repository's Settings > Pages (see the Quarto docs for more specifics).
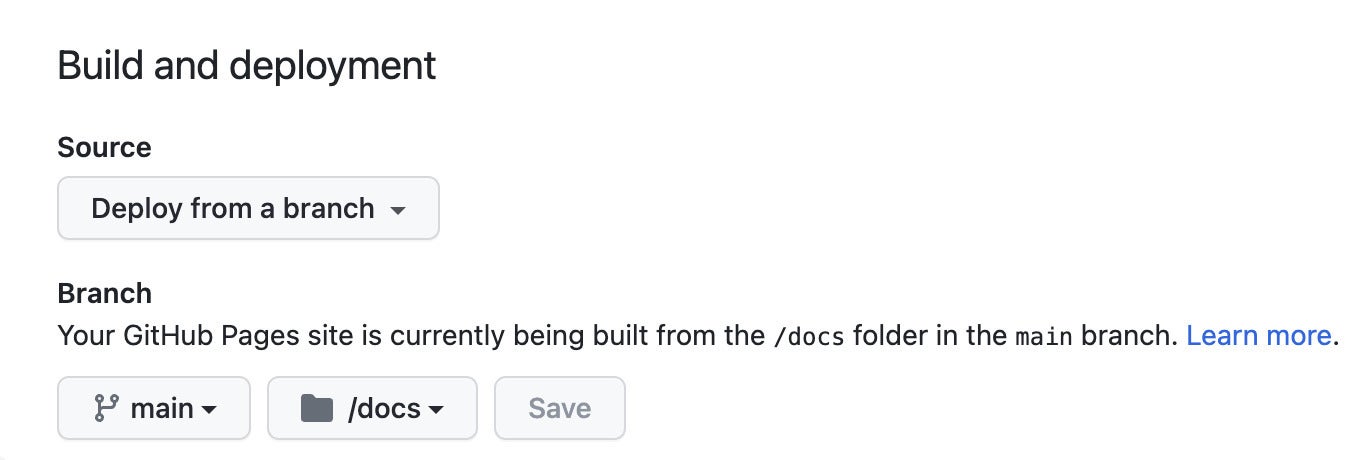 Screenshot by Sharon Machlis
Screenshot by Sharon Machlis
Figure 9. The GitHub repo setting to publish to GitHub Pages.
With setup done, you need to render your document and push it to GitHub each time the document updates. One way is to run the following commands manually in your terminal (not the R console) or add them to a shell script:
quarto render git add * git commit -m "Updating data dictionary" git push
Or, if you'd rather keep everything in R, create a render_dictionary.R script with
system('quarto render')
system('git add *')
system('git commit -m "Updating data dictionary"')
system('git push')
I followed all those instructions when I first set up my repo but ended up with a problem: My www directory wasn't copied to my docs directory, so my report links ended up as 404 document not found errors.
There's probably a more elegant way to solve this, but I got it working by adding commands to copy my www directory to the docs directory and add that to my git commit:
system('quarto render')
system('cp -r www docs')
system('git add www/*')
system('git add docs/www/*')
system('git add *')
system('git commit -m "Updating data dictionary"')
system('git push')
That will give you a basic data dictionary you can share and keep updated.
Conclusion
Using the pointblank package by Richard Iannone is an effective way to document your data sets, and you can make that documentation as basic or detailed as you’d like. Use the defaults for basic info about the data, or add text descriptions for some or all of your data’s columns. You can also include dynamically calculated values from your data set. While pointblank doesn’t have a way to generate a single catalog from individual data set reports, you can do this yourself with a Quarto or R Markdown document.
There are many more capabilities to pointblank, including a lot of custom styling options. Check out the pointblank package website for more details.
And for more R tips, head to the Do More With R page.