






Consensus is fundamental to consistent, distributed systems. In order to guarantee system availability in the event of inevitable crashes, systems need a way to ensure that each node in the cluster is in alignment, such that work can seamlessly transition between nodes in the case of failures. Consensus protocols such as Paxos, Raft, and View Stamped Replication (VSR) help to drive resiliency for distributed systems by providing the logic for processes like leader election, atomic configuration changes, synchronization, and more.
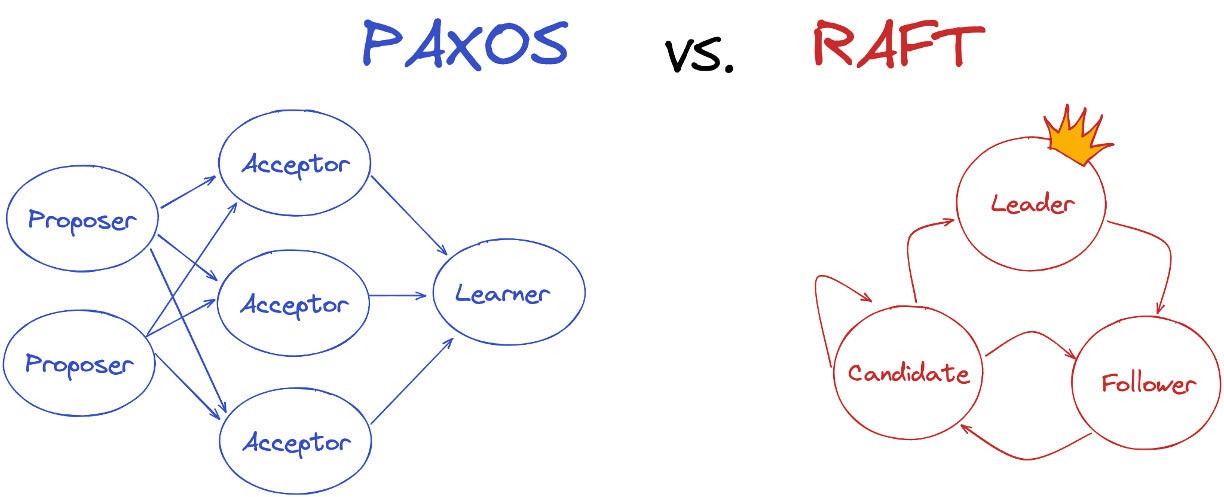
As with all design elements, the different approaches to distributed consensus offer different trade-offs. Paxos is the oldest consensus protocol around and is used in many systems like Google Cloud Spanner, Apache Cassandra, Amazon DynamoDB, and Neo4j. Paxos achieves consensus in a three-phased, leaderless, majority-wins protocol. While Paxos is effective in driving correctness, it is notoriously difficult to understand, implement, and reason about. This is partly because it obscures many of the challenges in reaching consensus (e.g. leader election, reconfiguration), making it difficult to decompose into subproblems.
Raft (for reliable, replicated, redundant, and fault-tolerant) can be thought of as an evolution of Paxos focused on understandability. Raft can achieve the same correctness as Paxos but is easier to understand and implement in the real world, so often can provide greater reliability guarantees. For example, Raft uses a stable form of leadership, which simplifies replication log management, and its leader election process is more efficient.
 Redpanda Data
Redpanda DataAnd because Raft decomposes the different logical components of the consensus problem, for example by making leader election a distinct step before replication, it is a flexible protocol to adapt for complex, modern distributed systems that need to maintain correctness and performance while scaling to PBs of throughput, all while being simpler to understand to new engineers hacking on the codebase.
For these reasons, Raft has been rapidly adopted for today’s distributed and cloud-native systems like MongoDB, CockroachDB, TiDB, and Redpanda in order to achieve greater performance and transactional efficiency.
How Redpanda implements Raft
When Redpanda founder Alex Gallego determined that the world needed a new streaming data platform to support the kind of GBps+ workloads that can cause Apache Kafka to fall over, he decided to rewrite Kafka from the ground-up.
The requirements for what would become Redpanda were 1) it needed to be simple and lightweight in order to reduce the complexity and inefficiency of running Kafka clusters reliably at scale; 2) it needed to maximize the performance of modern hardware in order to provide low latency for large workloads; and 3) it needed to guarantee data safety even for very large throughputs.
Implementing Raft provided a solid foundation for all three requirements:
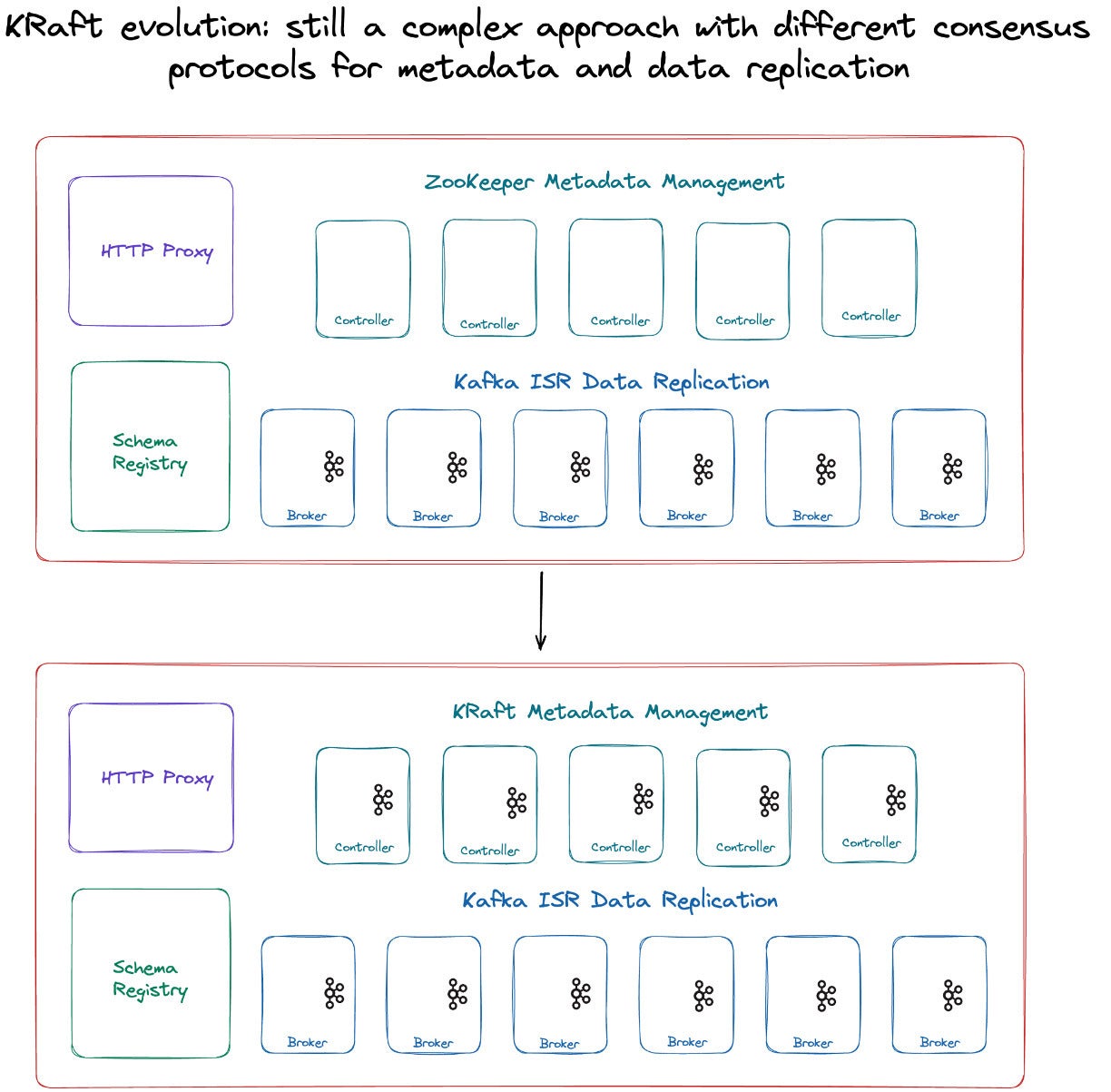
- Simplicity. Every Redpanda partition is a Raft group, so everything in the platform is reasoning around Raft, including both metadata management and partition replication. This contrasts with the complexity of Kafka, where data replication is handled by ISR (in-sync replicas) and metadata management is handled by ZooKeeper (or KRaft), and you have two systems that must reason with one another.
- Performance. The Redpanda Raft implementation can tolerate disturbances to a minority of replicas, so long as the leader and a majority of replicas are stable. In cases when a minority of replicas have a delayed response, the leader does not have to wait for their responses to progress, mitigating impact on latency. Redpanda is therefore more fault-tolerant and can deliver predictable performance at scale.
- Reliability. When Redpanda ingests events, they are written to a topic partition and appended to a log file on disk. Every topic partition then forms a Raft consensus group, consisting of a leader plus a number of followers, as specified by the topic’s replication factor. A Redpanda Raft group can tolerate ƒ failures given 2ƒ+1 nodes; for example, in a cluster with five nodes and a topic with a replication factor of five, two nodes can fail and the topic will remain operational. Redpanda leverages the Raft joint consensus protocol to provide consistency even during reconfiguration.
Redpanda also extends core Raft functionality in some critical ways in order to achieve the scalability, reliability, and speed required of a modern, cloud-native solution. Its innovations on top of Raft include changes to the election process, heartbeat generation, and, critically, support for Apache Kafka ACKS. These innovations ensure the best possible performance in all scenarios, which is what enables Redpanda to be significantly faster than Kafka while still guaranteeing data safety. In fact, Jepsen testing has verified that Redpanda is a safe system without known consistency problems, and a solid Raft-based consensus layer.
But what about KRaft?
While Redpanda takes a Raft-native approach, the legacy streaming data platforms have been laggards in adopting modern approaches to consensus. Kafka itself is a replicated distributed log, but it has historically relied on yet another replicated distributed log—Apache ZooKeeper—for metadata management and controller election. This has been problematic for a few reasons:
- Managing multiple systems introduces administrative burden;
- Scalability is limited due to inefficient metadata handling and double caching;
- Clusters can become very bloated and resource intensive; in fact, it is not uncommon to see clusters with equal numbers of ZooKeeper and Kafka nodes.
These limitations have not gone unacknowledged by Apache Kafka’s committers and maintainers, who are in the process of replacing ZooKeeper with a self-managed metadata quorum: Kafka Raft (KRaft). This event-based flavor of Raft reduces the administrative challenges of Kafka metadata management, and is a promising sign that the Kafka ecosystem is moving in the direction of modern approaches to consensus and reliability.
Unfortunately, KRaft does not solve the problem of having two different systems for consensus in a Kafka cluster. In the new KRaft paradigm, KRaft partitions handle metadata and cluster management, but replication is handled by the brokers, so you still have these two distinct platforms and the inefficiencies that arise from that inherent complexity.
 Redpanda Data
Redpanda DataCombining Raft with performance engineering
As data industry leaders like CockroachDB, MongoDB, Neo4j, and TiDB have demonstrated, Raft-based systems deliver simpler, faster, and more reliable distributed data environments. Raft is becoming the standard consensus protocol for today’s distributed data systems because it marries particularly well with performance engineering to further boost the throughput of data processing.
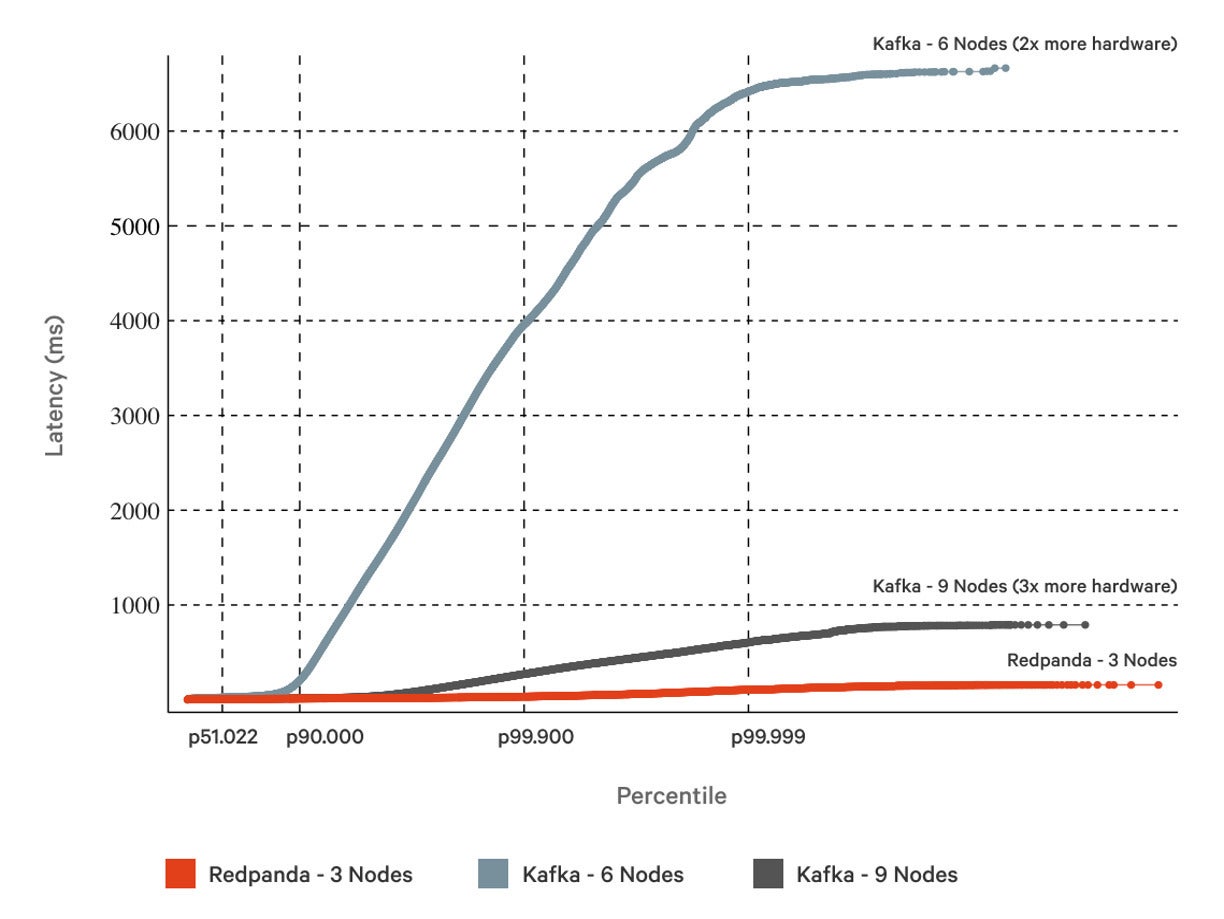
For example, Redpanda combines Raft with speedy architectural ingredients to perform at least 10x faster than Kafka at tail latencies (p99.99) when processing a 1GBps workload, on one-third the hardware, without compromising data safety. Traditionally, GBps+ workloads have been a burden for Apache Kafka, but Redpanda can support them with double-digit millisecond latencies, while retaining Jepsen-verified reliability.
How is this achieved? Redpanda is written in C++, and uses a thread-per-core architecture to squeeze maximum performance out of modern chips and network cards. These elements work together to elevate the value of Raft for a distributed streaming data platform.
 Redpanda Data
Redpanda DataFor example, because Redpanda bypasses the page cache and the Java Virtual Machine (JVM) dependency of Kafka, it can embed hardware-level knowledge into its Raft implementation. Typically, every time you write in Raft you have to flush in order to guarantee the durability of writes on disk. In Redpanda’s optimistic approach to Raft, smaller intermittent flushes are dropped in favor of a larger flush at the end of a call. While this introduces some additional latency per call, it reduces overall system latency and increases overall throughput, because it reduces the total number of flush operations.
While there are many effective ways to ensure consistency and safety in distributed systems (Blockchains do it very well with proof-of-work and proof-of-stake protocols), Raft is a proven approach and flexible enough that it can be enhanced, as with Redpanda, to adapt to new challenges. As we enter a new world of data-driven possibilities, driven in part by AI and machine learning use cases, the future is in the hands of developers who can harness real-time data streams.
Raft-based systems, combined with performance-engineered elements like C++ and thread-per-core architecture, are driving the future of data streaming for mission-critical applications.
Doug Flora is head of product marketing at Redpanda Data.
—
New Tech Forum provides a venue to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to newtechforum@infoworld.com.