






Imagine you are getting groceries delivered, or looking for a recommendation on what to watch next on TV, or using a credit card without worrying too much about fraud. The applications that power these interactions all rely on data in motion, and there’s a decent chance Apache Kafka powers the applications.
More than 80% of the Fortune 100 use Kafka as the event streaming substrate to power real-time, user-facing applications and software-driven back ends. Kafka has become the go-to for any organization looking to integrate increasingly diverse portfolios of applications and microservices through immutable event logs rather than mutable data stores. The benefits are manifold, but recall that Kafka is a distributed system, and volunteering to operate a distributed system yourself is an increasingly controversial choice.
This is why the cloud exists. Through fully managed cloud services, vendors bear the capital expenses and accumulate the operational expertise necessary to run infrastructure well. Confluent, the first fully managed Kafka service on the market, lets you focus on building applications and adding value to the business rather than turning dials on operationally complex infrastructure layers. I’d like to walk you through how Confluent can bring peace and simplicity to the lives of the people who work with Kafka.
Cloud-native is the future of infrastructure
There is always a greater demand for application functionality than there is the capacity to deliver it. This implies that application teams should focus on the activities that create the most value that they possibly can. Generally, this means providing new features that directly give a competitive edge to customers and users.
Of course, all applications require storage and compute infrastructure to function with ongoing development and maintenance, distracting from value-creating feature development. This is especially true for Kafka, because distributed data infrastructure imposes a significant opportunity cost on teams deciding to operate it themselves. Put simply: Your job is ultimately to take care of your customers. While running Kafka may be a means to that end, it is likely not the most practical way to get the job done. This challenge is one of many reasons that led to the rise of managed cloud services.
Elastic scaling for reals this time
Elastic scalability has always been an inherent part of the cloud’s mythology but has been slow in coming to reality. Early on in the cloud’s history, database innovators applied new approaches to horizontal elastic scalability of massive datasets. More recently, microservices and container orchestration have helped bring application scalability to the masses. However, data infrastructure generally has remained notoriously resistant to easy scalability.
Kafka has an excellent horizontal scale story: topics are partitioned, individual partition logs are assigned to different brokers, then consumed by scalable clusters of client applications. There are some scriptable tools to administer these scale-oriented capabilities, but self-managed clusters still require significant operational and technical expertise. For example, partition logs don’t remain evenly distributed on brokers as a cluster changes over time. Further, new topics are added, and partitions receive potentially uneven read and write traffic, as business conditions evolve. That’s just one example of something cluster administrators must attend to over time.
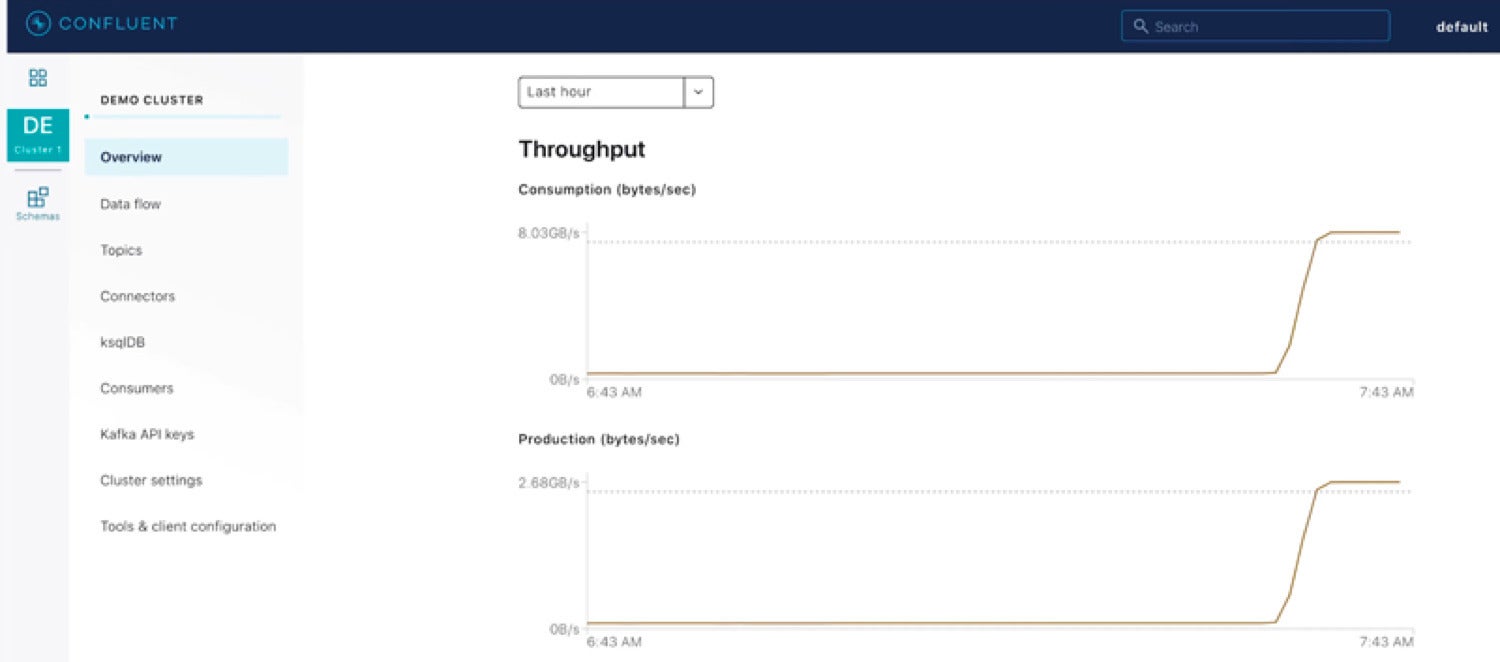
Confluent has built-in elastic scalability. Clusters scale from 0 to 100MBps throughput with no intervention and up to 11GBps (the current record as of this writing) through a simple web UI—no moving partitions around, no rebalancing brokers. As the world slowly catches up to the cloud’s original promises of elastic scale, Confluent brings scale to data infrastructure in a truly cloud-native way.
 Confluent
ConfluentConnecting your data everywhere
Your life will be multicloud anyway, so data infrastructure layers need to be multicloud-capable to be serious contenders. Confluent is multicloud, natively supporting AWS, Microsoft Azure, and Google Cloud. This flexibility is essential when you need to run on more than one cloud, or at least be able to threaten to. Confluent makes this easy by using a single management web UI and a unified control plane abstracted from the particular cloud infrastructure.
 Confluent
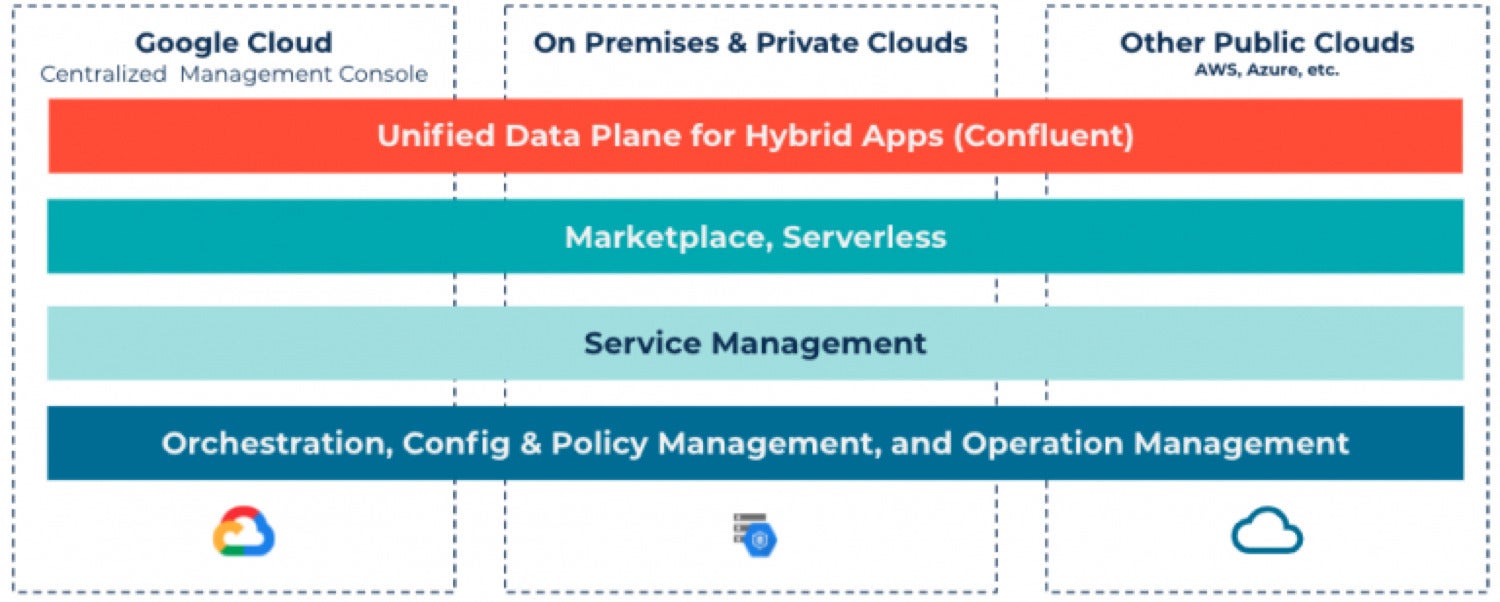
ConfluentBut multicloud isn’t always enough! Sometimes you don’t want to move everything to the cloud. Many companies want to maintain a mix of on-prem, private cloud, or public cloud services. This hybrid cloud experience is top of mind for Confluent, making it possible to maintain backup services, segregate products, and manage a sophisticated Plan B through the Confluent UI.
 Confluent
ConfluentDon’t get lost in the ecosystem, get the whole package
As the Kafka community has discovered in the 10 years since its birth, you need more than distributed logs to build a successful event-driven system. You also need reliable and secure connections between all your systems and streams, which is no mean feat. Then you can start to extract value from the whole system with real-time stream processing.
Several components have emerged around core Kafka functionality to help deliver on those needs, both from the open source ecosystem and from Confluent:
- Kafka Connect: The universal data integration framework that provides an ecosystem of connectors. It removes the need to re-write connectors for every new data source.
- Kafka Streams: A stream processing framework that enriches the existing Kafka client framework with sophisticated stream processing functionality, rather than offloading stream processing to another distributed system.
- Confluent Schema Registry: Helps maintain compatibility between evolving applications as message formats change over time.
- ksqlDB: The event streaming database for Kafka using SQL to build stream processing applications you might otherwise have built with Kafka Streams.
- Confluent Metrics API: Unifies many of the individual metrics you could collect through the JMX interface on various system components into a single, queryable stream of JSON data.
The fact of components like these is that teams will eventually need them. They have emerged from the Kafka community and from Confluent for that very reason. It is nearly impossible to be proficient enough in each of these areas to build a solution that does not require continual attention for smooth operation.
With Confluent, you have all the tools you need to be successful with Kafka at your fingertips. You can use one platform, and everything you need is there in a seamless, integrated way, including hundreds of connectors to popular data sources.
Data security at scale is a must
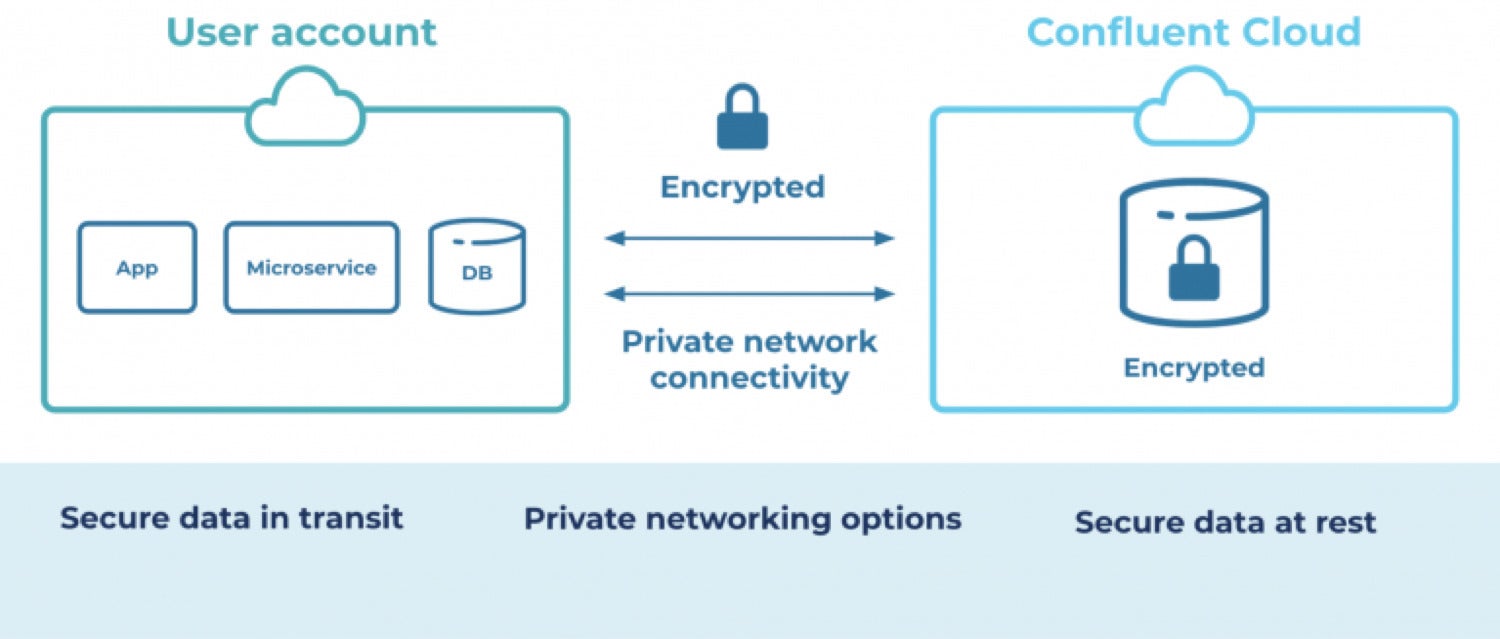
Kafka has a minimum viable security story: It offers robust encryption of data in flight and ACL-based authentication and authorization as options. Confluent expands on these features in the ways enterprises expect.
 Confluent
ConfluentFor example, all data in Confluent is encrypted at rest as well as in flight. On top of that, applications also require authentication with every call, removing the threat of accidentally having “wide open” ports.
A variety of other Confluent features help keep security simple, including SAML-based single sign-on and secure access to other cloud resources in your VPCs.
As proof of these secure capabilities, Confluent meets many industry standards and certification achievements, meeting requirements for PCI, HIPAA, and GDPR as well as SOC1, SOC2, SOC3, and ISO 27001 certifications.
It is a challenge to achieve all of these certifications while also providing many other secure and convenient features out of the box. Developers can build with confidence while leaving the heavy security lift to the managed platform.
But don’t just take my word for it. You can try our fully managed Kafka service for free through Confluent or your cloud provider of choice.
Tim Berglund is senior director of developer advocacy at Confluent.
—
New Tech Forum provides a venue to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to newtechforum@infoworld.com.