






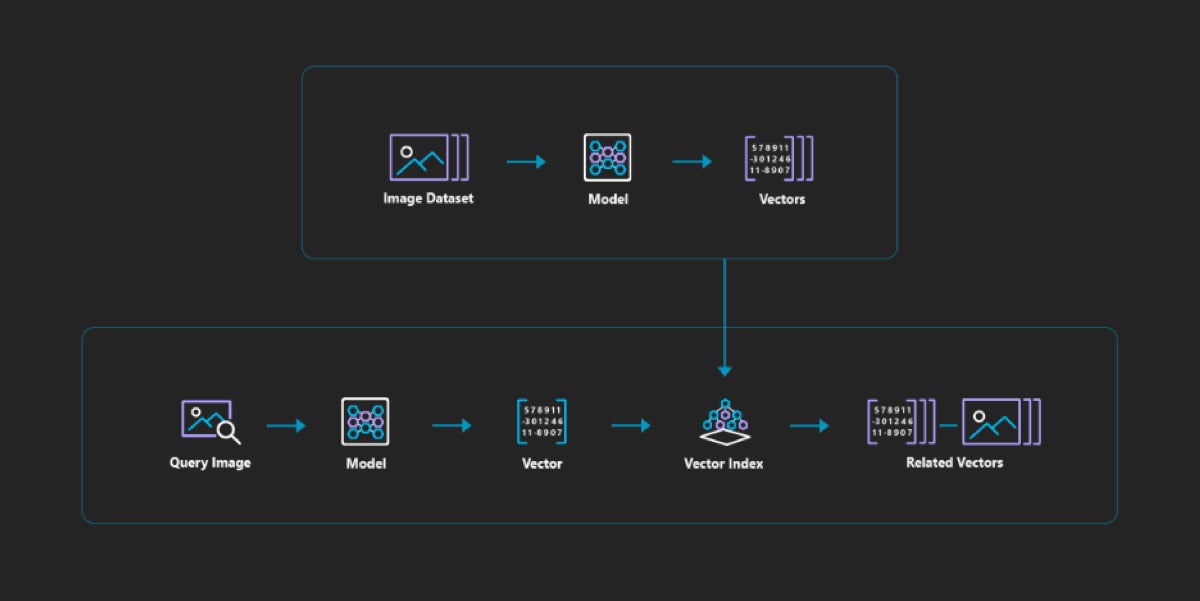
Suppose you wanted to implement a music service that would behave like Spotify, finding you songs that were similar to ones you like. How would you go about it? One way would be to classify each song by a number of characteristics, save those “vectors” in an indexed database, and search the database to find the song-description vectors “near” your favorites. In other words, you could perform a vector similarity search.
What is vector similarity search?
There are typically four components to vector similarity search: vector embeddings that capture the key characteristics of the original object, such as a song, an image, or some text; distance metrics that represent “nearness” between vectors; search algorithms; and a database that holds the vectors and supports the vector search with indexes.
What are vector embeddings?
Vector embeddings are essentially feature vectors, as understood in the context of machine learning and deep learning. They can be defined by manually performing feature engineering or by using the output of models.
For example, text strings can be turned into word embeddings (feature vectors) using neural networks, dimensionality reduction on the word co-occurrence matrix, probabilistic models, explainable knowledge-base methods, and explicit representation in terms of the context in which words appear. Common models to train and use word embeddings include word2vec (Google), GloVe (Stanford), ELMo (Allen Institute/University of Washington), BERT (Google), and fastText (Facebook).
Images are often embedded by capturing the output of convolutional neural network (CNN) models or transformer models. These models automatically reduce the dimensionality of the feature vectors by rolling together (“convolving”) patches of pixels into features, and down-sampling with pooling layers.
Product recommendations could be based on embeddings of the words and phrases in the product description, on embeddings of the product images, or both. Audio embeddings might be based on Fourier transforms of the audio (which gives you the spectrum); on descriptions of the composer, genre, artist, tempo, rhythm, and loudness; or on both the spectrum and keywords. The field is advancing quickly, so I expect there will be new embedding techniques for many application areas.
What are distance metrics?
We normally think of distance in terms of straight lines in two or three dimensions. Vector embeddings are often upwards of 10-dimensional, with 1,000 dimensions not at all unusual. The general formula for distances is named after Hermann Minkowski, who is best known (at least to physicists) for his formulation of Einstein’s special relativity as a four-dimensional space-time with time as the fourth dimension. The Minkowski metric (or distance) is a generalization of both Euclidean distances (direct straight lines) and Manhattan distances (jagged lines, like walking city blocks).
The Euclidean distance, also known as the L2 distance or L2 norm, is the most common metric used for clustering algorithms. Another metric, the cosine similarity, is often used for text processing, where the direction of the embedding vectors is important but the distance between them is not.
What algorithms can perform vector similarity search?
In general, a K-nearest neighbor (KNN) algorithm is likely to give good answers to vector search problems. The major issue with KNN is that it’s computationally expensive, both in processor and memory usage.
Alternatives to KNN include approximate nearest neighbors (ANN) search algorithms and a variation on ANN, space partition tree and graph (SPTAG). SPTAG was released to open source by Microsoft Research and Bing. A similar variation on ANN, released to open source by Facebook, is Facebook AI similarity search (Faiss). Product quantizers and the IndexIVFPQ index help to speed up Faiss and some other ANN variants. As I mentioned earlier, vector databases often build vector indexes to improve search speed.
Faiss was built to search for multimedia documents that are similar to a query document in a billion-vector database. For evaluation purposes, the developers used Deep1B, a collection of one billion images. Faiss allows you to customize your vector preprocessing, database partitioning, and vector encoding (product quantizing) so that the dataset will fit into available RAM. Faiss is implemented separately for CPUs and GPUs. On CPUs, Faiss can achieve a 40% recall score in the one-billion image dataset in 2 ms, translating to 500 queries per second per core. On a Pascal-class Nvidia GPU, Faiss searches more than 20 times faster than on a CPU.
SPTAG was built for similar purposes, albeit using slightly different methods. Bing vectorized over 150 billion pieces of data indexed by the search engine to improve the results over traditional keyword matching. The vectorized data include single words, characters, web page snippets, full queries, and other media. The authors of SPTAG built on their previous research on ANN at Microsoft Research Asia using query-driven iterated neighborhood graph search, and implemented both kd-tree (better for index building) and balanced k-means tree (better for search accuracy) algorithms. Searches start with several random seeds, then iteratively continue in the trees and the graph.
Pinecone is a fully managed vector database with an API that makes it easy to add vector search to production applications. Pinecone’s similarity search services are distributed, serverless, persistent, consistent, sharded, and replicated across many nodes. Pinecone can handle billions of vector embeddings, and you can run similarity search in Python or Java applications and notebooks.
Pinecone claims a latency of < 50 ms, even with billions of items and thousands of queries per second. It runs on hardened AWS infrastructure. Data is stored in isolated containers and encrypted in transit.
 Microsoft Research
Microsoft Research
Bing ANN vector search architecture, courtesy of Microsoft Research.
What are the applications of vector search?
In addition to the image search demonstrated by Facebook and the semantic text search implemented by Microsoft Bing, vector similarity search can serve many use cases. Examples include product recommendations, FAQ answers, personalization, audio search, deduplication, and threat detection in IT event logs.