






Building a distributed database is complicated and needs to consider many factors. Previously, I discussed two important techniques, sharding and partitioning, for gaining greater throughput and performance from databases. In this post, I will discuss another important technique, deduplication, that can be used to replace transactions for eventually consistent use cases with defined primary keys.
Time series databases such as InfluxDB provide ease of use for clients and accept ingesting the same data more than once. For example, edge devices can just send their data on reconnection without having to remember which parts were successfully transmitted previously. To return correct results in such scenarios, time series databases often apply deduplication to arrive at an eventually consistent view of the data. For classic transactional systems, the deduplication technique may not be obviously applicable but it actually is. Let us step through some examples to understand how this works.
Understanding transactions
Data inserts and updates are usually performed in an atomic commit, which is an operation that applies a set of distinct changes as a single operation. The changes are either all successful or all aborted, there is no middle ground. The atomic commit in the database is called a transaction.
Implementing a transaction needs to include recovery activities that redo and/or undo changes to ensure the transaction is either completed or completely aborted in case of incidents in the middle of the transaction. A typical example of a transaction is a money transfer between two accounts, in which either money is withdrawn from one account and deposited to another account successfully or no money changes hands at all.
In a distributed database, implementing transactions is even more complicated due to the need to communicate between nodes and tolerate various communication problems. Paxos and Raft are common techniques used to implement transactions in distributed systems and are well known for their complexity.
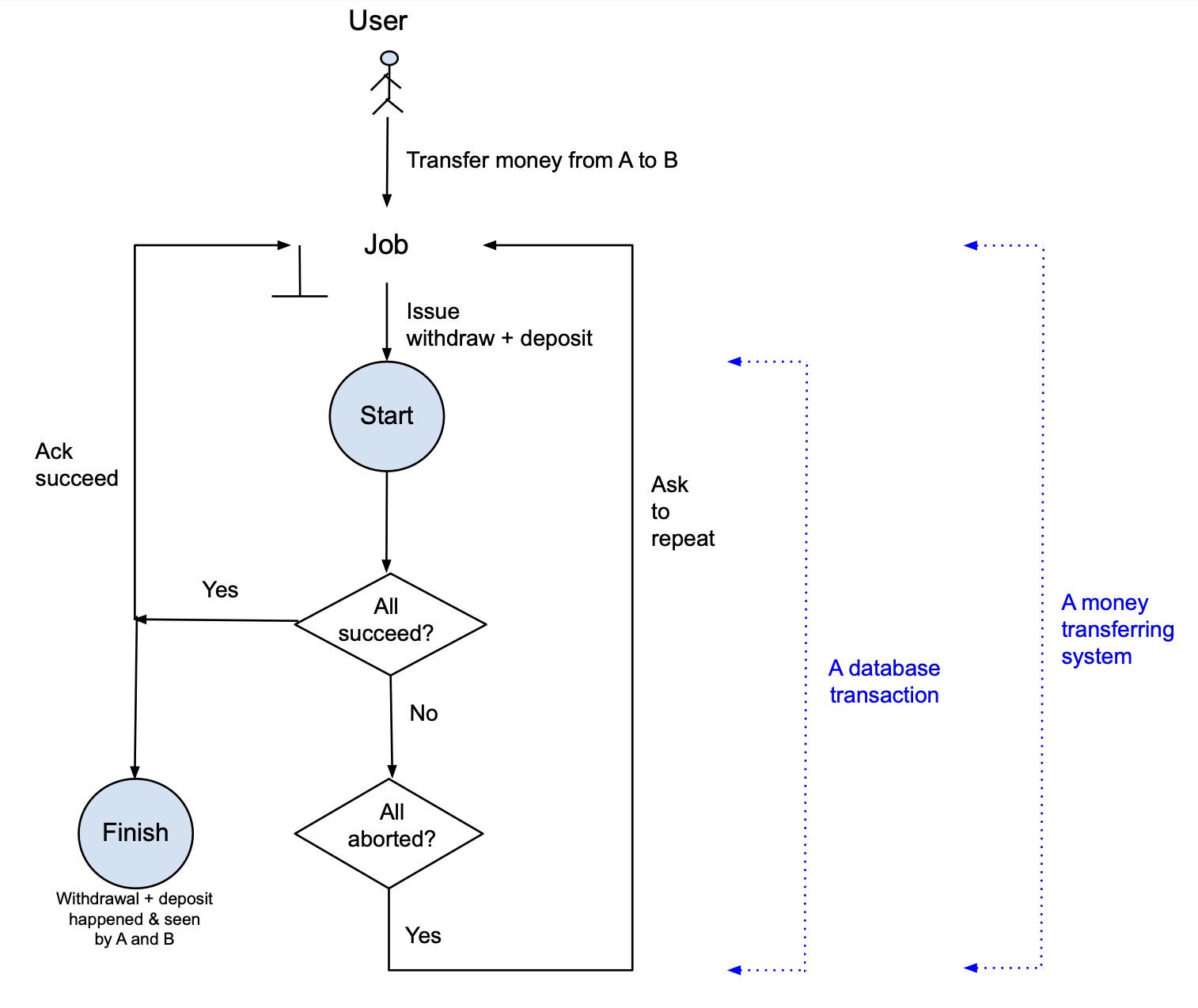
Figure 1 shows an example of a money transferring system that uses a transactional database. When a customer uses a bank system to transfer $100 from account A to account B, the bank initiates a transferring job that starts a transaction of two changes: withdraw $100 from A and deposit $100 to B. If the two changes both succeed, the process will finish and the job is done. If for some reason the withdrawal and/or deposit cannot be performed, all changes in the system will be aborted and a signal will be sent back to the job telling it to re-start the transaction. A and B only see the withdrawal and deposit respectively if the process is completed successfully. Otherwise, there will be no changes to their accounts.
 InfluxData
InfluxData
Figure 1. Transactional flow.
Non-transactional process
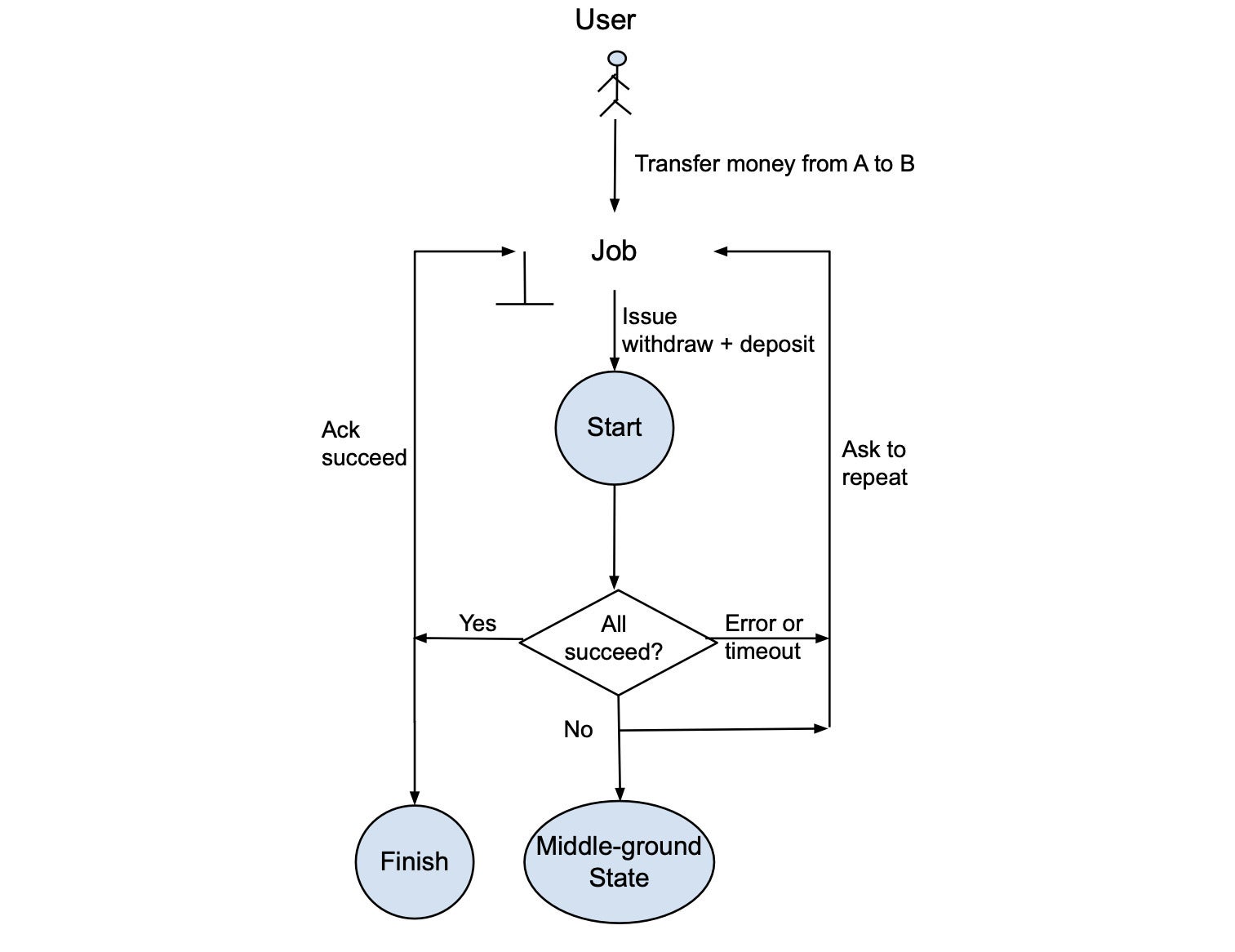
Clearly, the transactional process is complicated to build and maintain. However, the system can be simplified as illustrated in Figure 2. Here, in the “non-transactional process,” the job also issues a withdrawal and a deposit. If the two changes succeed, the job completes. If neither or only one of the two changes succeeds, or if an error or timeout happens, the data will be in a “middle ground” state and the job will be asked to repeat the withdrawal and deposit.
 InfluxData
InfluxData
Figure 2. Non-transactional flow.
The data outcomes in the “middle ground” state can be different for various restarts on the same transfer but they are acceptable to be in the system as long as the correct finish state will eventually happen. Let us go over an example to show these outcomes and explain why they are acceptable. Table 1 shows two expected changes if the transaction is successful. Each change includes four fields:
- AccountID that uniquely identifies an account.
- Activity that is either a withdrawal or a deposit.
- Amount that is the amount of money to withdraw or deposit.
- BankJobID that uniquely identifies a job in a system.
|
AccountID |
Activity |
Amount |
BankJobID |
|
A |
Withdrawal |
100 |
543 |
|
B |
Deposit |
100 |
543 |
At each repetition of issuing the withdrawal and deposit illustrated in Figure 2, there are four possible outcomes:
- No changes.
- Only A is withdrawn.
- Only B is deposited.
- Both A is withdrawn and B is deposited.
To continue our example, let us say it takes four tries before the job succeeds and an acknowledgement of success is sent. The first try produces “only B is deposited,” hence the system has only one change as shown in Table 2. The second try produces nothing. The third try produces “only A is withdrawn,” hence the system now has two rows as shown in Table 3. The fourth try produces “both A is withdrawn and B is deposited,” hence the data in the finished state looks like that shown in Table 4.
|
AccountID |
Activity |
Amount |
BankJobID |
|
B |
Deposit |
100 |
543 |
–
|
AccountID |
Activity |
Amount |
BankJobID |
|
B |
Deposit |
100 |
543 |
|
A |
Withdrawal |
100 |
543 |
–
|
AccountID |
Activity |
Amount |
BankJobID |
|
B |
Deposit |
100 |
543 |
|
A |
Withdrawal |
100 |
543 |
|
A |
Withdrawal |
100 |
543 |
|
B |
Deposit |
100 |
543 |
Data deduplication for eventual consistency
The four-try example above creates three different data sets in the system, as shown in Tables 2, 3, and 4. Why do we say this is acceptable? The answer is that data in the system is allowed to be redundant as long as we can manage it effectively. If we can identify the redundant data and eliminate that data at read time, we will be able to produce the expected result.
In this example, we say that the combination of AccountID, Activity, and BankJobID uniquely identifies a change and is called a key. If there are many changes associated with the same key, then only one of them is returned during read time. The process to eliminate redundant information is called deduplication. Therefore, when we read and deduplicate data from Tables 3 and 4, we will get the same returned values that comprise the expected outcome shown in Table 1.
In the case of Table 2, which includes only one change, the returned value will be only a part of the expected outcome of Table 1. This means we do not get strong transactional guarantees, but if we are willing to wait to reconcile the accounts, we will eventually get the expected outcome. In real life, banks do not release transferred money for us to use immediately even if we see it in our account. In other words, the partial change represented by Table 2 is acceptable if the bank makes the transferred money available to use only after a day or two. Because the process of our transaction is repeated until it is successful, a day is more than enough time for the accounts to be reconciled.
The combination of the non-transactional insert process shown in Figure 2 and data deduplication at read time does not provide the expected results immediately but eventually the results will be the same as expected. This is called an eventually consistent system. By contrast, the transactional system illustrated in Figure 1 always produces consistent results. However, due to the complicated communications requited to guarantee that consistency, a transaction does take time to finish and the number of transactions per second will consequently be limited.
Deduplication in practice
Nowadays, most databases implement an update as a delete and then an insert to avoid the expensive in-place data modification. However, if the system supports deduplication, the update can just be done as an insert if we add a “Sequence” field in the table to identify the order in which the data has entered the system.
For example, after making the money transfer successfully as shown in Table 5, let’s say we found the amount should be $200 instead. This could be fixed by making a new transfer with the same BankJobID but a higher Sequence number as shown in Table 6. At read time, the deduplication would return only the rows with the highest sequence number. Thus, the rows with amount $100 would never be returned.
|
AccountID |
Activity |
Amount |
BankJobID |
Sequence |
|
B |
Deposit |
100 |
543 |
1 |
|
A |
Withdrawal |
100 |
543 |
1 |
–
|
AccountID |
Activity |
Amount |
BankJobID |
Sequence |
|
B |
Deposit |
100 |
543 |
1 |
|
A |
Withdrawal |
100 |
543 |
1 |
|
A |
Withdrawal |
200 |
543 |
2 |
|
B |
Deposit |
200 |
543 |
2 |
–
Because deduplication must compare data to look for rows with the same key, organizing data properly and implementing the right deduplication algorithms are critical. The common technique is sorting data inserts on their keys and using a merge algorithm to find duplicates and deduplicate them. The details of how data is organized and merged will depend on the nature of the data, their size, and the available memory in the system. For example, Apache Arrow implements a multi-column sort merge that is critical to perform effective deduplication.
Performing deduplication during read time will increase the time needed to query data. To improve query performance, deduplication can be done as a background task to remove redundant data ahead of time. Most systems already run background jobs to reorganize data, such as removing data that was previously marked to be deleted. Deduplication fits very well in that model that reads data, deduplicates or removes redundant data, and writes the result back.
In order to avoid sharing CPU and memory resources with data loading and reading, these background jobs are usually performed in a separate server called a compactor, which is another large topic that deserves its own post.
Nga Tran is a staff software engineer at InfluxData and a member of the company’s IOx team, which is building the next-generation time series storage engine for InfluxDB. Before InfluxData, Nga worked at Vertica Systems where she was one of the key engineers who built the query optimizer for Vertica and later ran Vertica’s engineering team. In her spare time, Nga enjoys writing and posting materials for building distributed databases on her blog.
—
New Tech Forum provides a venue to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to newtechforum@infoworld.com.