The best open source software for machine learning
InfoWorld’s 2018 Best of Open Source Software Award winners in machine learning and deep learning














The best open source software for machine learning
Amazon, Google, Microsoft, Facebook—these companies and many others are vying to create the richest and easiest libraries for machine learning and deep learning. Competition is good! Our 2018 Bossie winners in machine learning include the most advanced frameworks, other cutting-edge tools for building and training models, and platforms for distributing deep learning across a cluster.
[ InfoWorld presents the Best of Open Source Software Awards 2018: The best open source software for software development. | The best open source software for cloud computing. | The best open source software for data storage and analytics. | The best open source software for machine learning. ]

TensorFlow
Since I reviewed the widely adopted deep neural network framework in January 2018, TensorFlow has received another five version upgrades and become easier and even more powerful. Major new features and improvements include integration with Google Cloud Bigtable as a data source, a better tf.keras module, better generation of optimized models for mobile devices, improved data loading and text processing, new data prefetching to GPU memory, improved performance with Google Cloud TPUs, and elevation of eager execution mode to fully supported status. As you may recall, eager execution provides an imperative programming style (à la NumPy) that is easier to understand than building and then executing graphs.
— Martin Heller

Keras
Keras is about as simple as a deep neural network framework could be—one line of Python code per layer, and one call each for compiling and training a model, using sequential models. Keras also offers support of arbitrary topologies through its functional API. Keras uses TensorFlow, Theano, and CNTK 2 as back ends, and gains good support for GPUs from them (and TPUs on Google Cloud with TensorFlow). Training on Keras uses Numpy arrays as input, although it can support other formats through a Python generator interface. Keras has a good assortment of deployment options that range from Cloud services to mobile devices.
— Martin Heller
PyTorch
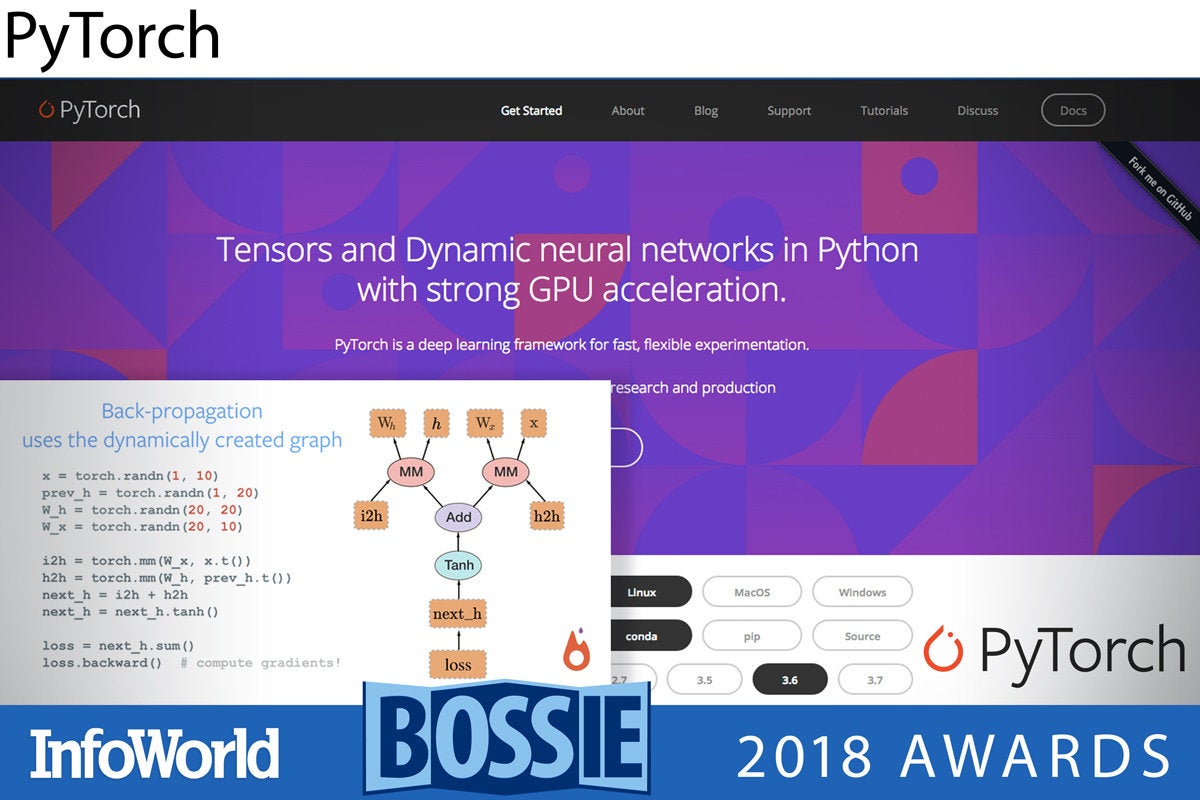
PyTorch is a high-level deep neural network that uses Python as its scripting language, and uses an evolved Torch C/CUDA back end. The production features of Caffe2 are also being incorporated into the PyTorch project. PyTorch features dynamic neural networks, meaning that the network topology itself can change from iteration to iteration during training.
To allow for dynamic networks, which are both easier to debug and faster to iterate than static networks, PyTorch programs create a graph on the fly. Then backpropagation uses the dynamically created graph, automatically calculating the gradients from the saved tensor states. Given that PyTorch builds on the mature Torch framework, it already has a strong collection of neural network layers, optimization algorithms, and loss functions.
— Martin Heller
Fast.ai
Fast.ai is not just a deep learning MOOC; it’s also a deep learning library that builds on top of PyTorch. The Fast.ai framework not only provides a set of consistent and opinionated wrappers for building and training models, but also incorporates some cutting-edge techniques for training deep learning models (e.g. Cyclic Learning Rates and transfer learning techniques for NLP problem domains). In other words, Fast.ai will help you build models for both Kaggle competitions and actual production applications. On top of all of that, it’s probably the easiest way to dip into the world of deep learning!
— Ian Pointer

Chainer
Chainer is a flexible Python framework for neural networks. Unlike frameworks that first define and fix the neural network topology, then train it, Chainer uses a define-by-run scheme. That means that the network is defined dynamically via the actual forward computation; the backpropagation computation computes the gradient array and calls the optimizer to find the updated weights.
Chainer uses CuPy as its back end for GPU computation, which in turn calls CUDA and cuDNN. In particular, the cupy.ndarray class is the GPU array implementation for Chainer. CuPy supports a subset of features of NumPy with a compatible interface. Chainer has influenced other recent neural network frameworks. PyTorch also uses dynamic neural networks, and so does the eager execution mode of TensorFlow.
— Martin Heller

H2O
When I reviewed H2O.ai’s Driverless AI late in 2017, I liked it as an automatically driven machine learning system that also does feature engineering and annotation. I explained that it is built on top of the open source H2O stack, which does all the machine learning for Driverless AI, and also features its own Auto ML and data preparation modules.
H2O is a distributed in-memory machine learning platform with linear scalability. It supports the most widely used statistical and machine learning algorithms including gradient boosted machines, generalized linear models, and deep learning. H2O supports programming in R, Python, Scala, Java, and its own interactive notebooks.
— Martin Heller

Microsoft Cognitive Toolkit
Microsoft Cognitive Toolkit—or more simply CNTK—is the deep learning toolkit that underlies the AI capabilities of Microsoft’s services including Skype, Cortana, Bing, and Xbox. It handles multidimensional dense or sparse data from Python, C++, or BrainScript, and includes a wide variety of neural network types: FeedForward (FFN), Convolutional (CNN), Recurrent/Long Short Term Memory (RNN/LSTM), batch normalization, and sequence-to-sequence with attention, for starters.
The Cognitive Toolkit supports reinforcement learning, generative adversarial networks, supervised and unsupervised learning, automatic hyperparameter tuning, and the ability to add new, user-defined, core components on the GPU from Python. It is able to do parallelism with accuracy on multiple GPUs and machines, and it can fit even the largest models into GPU memory.
— Martin Heller

MXNet
When this deep learning framework arrived on the scene in 2016, it was interesting for two reasons: It scaled well on large numbers of networked instances with multiple GPUs, and it was Amazon’s preferred deep neural networking framework. But as I said in my review at the time, MXNet was rough around the edges.
MXNet moved under the Apache Software Foundation umbrella early in 2017, and is still considered “incubating” at v1.2.1. It’s no longer rough around the edges, however.
MXNet boasts good control over data structure placement on devices, multi-GPU training, automatic differentiation, and optimized predefined neural network layers. It has in Gluon an easy-to-use interface that can also train quickly. Prior to Gluon, you could either write easy imperative code or fast symbolic code in MXNet, but not both at once.
— Martin Heller
Featuretools
Featuretools is an open source Python library for automated feature engineering. If you’ve ever done any serious data science, you know how tricky and time-consuming it can be to manually transform your raw data into meaningful, normalized features. The proprietary Driverless AI from H2O.ai demonstrated automating feature engineering to almost the level achieved by a Kaggle grandmaster.
Featuretools implements deep feature synthesis. You can combine your raw data with what you know about your data to build meaningful features for machine learning and predictive modeling. Featuretools provides APIs to ensure that only valid data is used for calculations, keeping your feature vectors safe from common label leakage problems.
— Martin Heller
Horovod
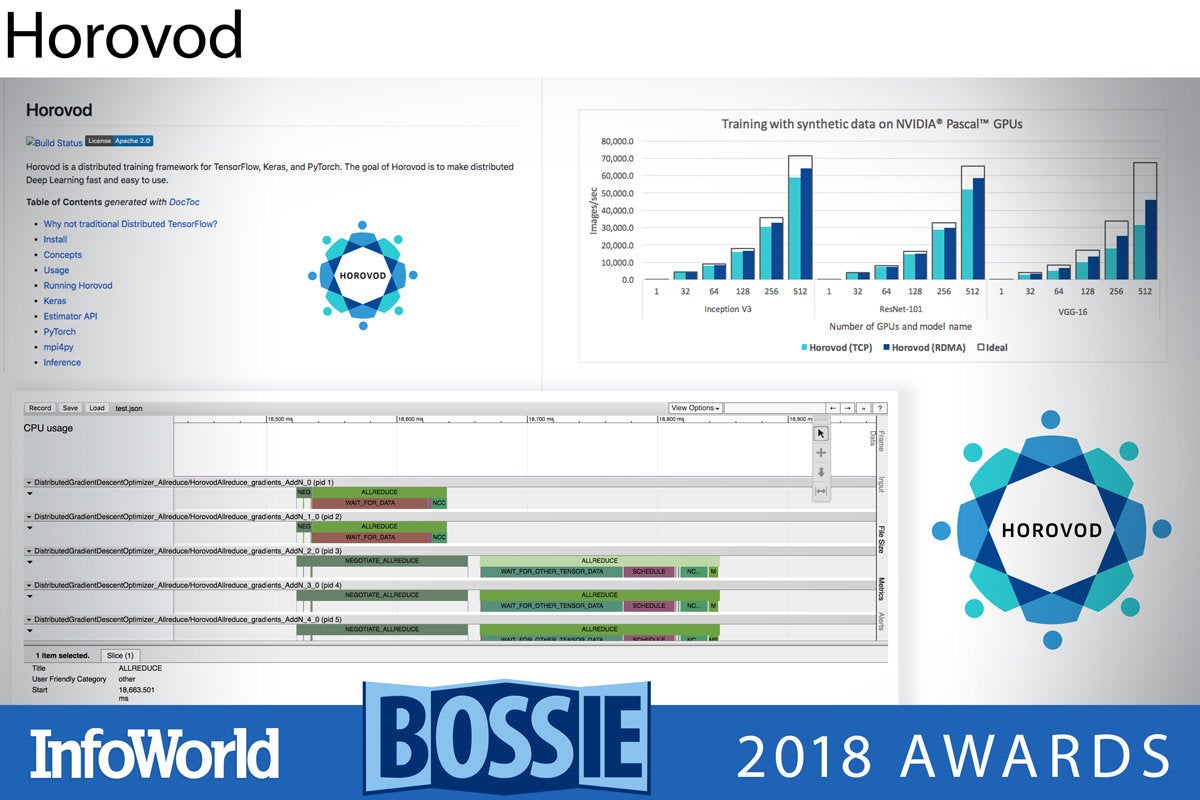
Created at Uber, Horovod is a distributed training framework for TensorFlow, Keras, and PyTorch. The goal of Horovod is to make distributed deep learning fast and easy to use. Horovod borrows ideas from Baidu’s draft implementation of the TensorFlow ring-allreduce algorithm and builds upon it.
Horovod uses Open MPI (or another MPI implementation) for message passing among nodes, and the Nvidia Collective Communications Library (NCCL) for its highly optimized version of ring-allreduce. Horovod achieves 90 percent scaling efficiency for both Inception V3 and ResNet-101, and 68 percent scaling efficiency for VGG-16, using as many as 512 Nvidia Pascal GPUs.
— Martin Heller
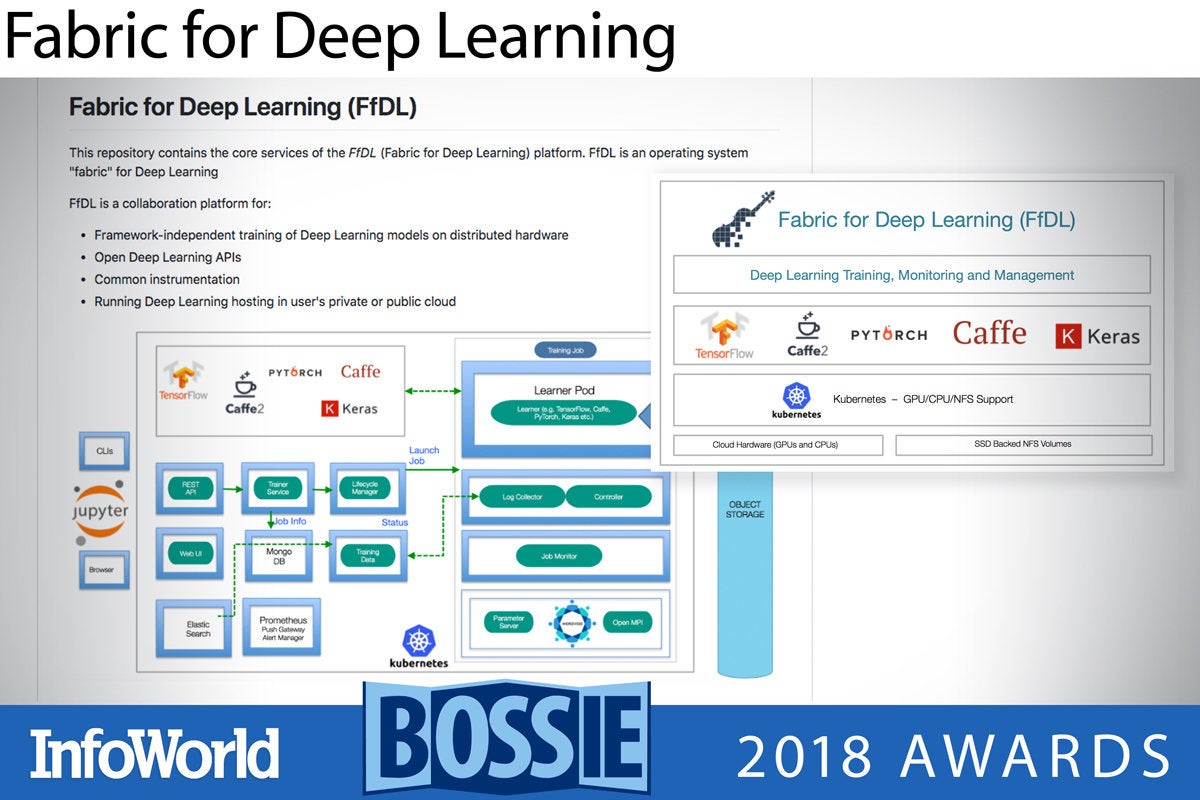
Fabric for Deep Learning
Fabric for Deep Learning—or FfDL, pronounced fiddle—is a deep learning platform offering TensorFlow, Caffe, PyTorch, Keras, and H2O as a service on Kubernetes. FfDL was originally developed for the IBM Cloud, but can also run in other clouds that support Kubernetes clusters, and locally on Docker via Kubeadm-DIND. FfDL will support GPUs if you use device plug-ins in Kubernetes and you choose GPU-enabled builds of the deep learning frameworks. FfDL has only been tested under MacOS and Linux.
— Martin Heller
Copyright © 2018 IDG Communications, Inc.
