






Log4j was the bucket of cold water that woke up most developers to their software supply chain security problem.
We’ve spent decades in software building things and obsessing over our production environment. But we’re building on unpatched Jenkins boxes sitting under someone’s desk. We spend all this time protecting our runtimes, then deploy to them using amateur tooling.
Our build environments aren’t nearly as secure as our production environments.
That’s what led to a whole lot of high-profile attacks in the last 12 months, from SolarWinds, to the Codecov attack, to the Travis CI secrets leak. We’ve gotten so good at protecting our infrastructure that attackers looked for an easier way in, and found it in the doorways we’ve left open in the supply chain.
Can’t get in through the perimeter security? Just find an open source dependency, or a library, and get in that way. Then pivot to all of the customers. This is the modern software supply chain hack.
We need roots of trust for software
We have roots of trust for people today. We have two-factor authentication, we have identification systems. These are things to vouch for a person’s identity. And hardware has the same thing. We have encryption keys. We have hardware we can trust hasn’t been tampered with when it boots up.
Even as internet users we have roots of trust. We have URIs, URNs, and URLs—effectively the namespaces on the internet that connect the identities, names, and locations of sites we are browsing. SSL certificates tell our browsers that sites are secure. DNS firewalls sit between the user’s recursive resolvers to make sure our cache isn’t being loaded with bad requests. All of this is happening behind the scenes, and has been incredibly effective in supporting billions of internet users for decades.
But we don’t have this for software artifacts today.
Developers trust too much implicitly
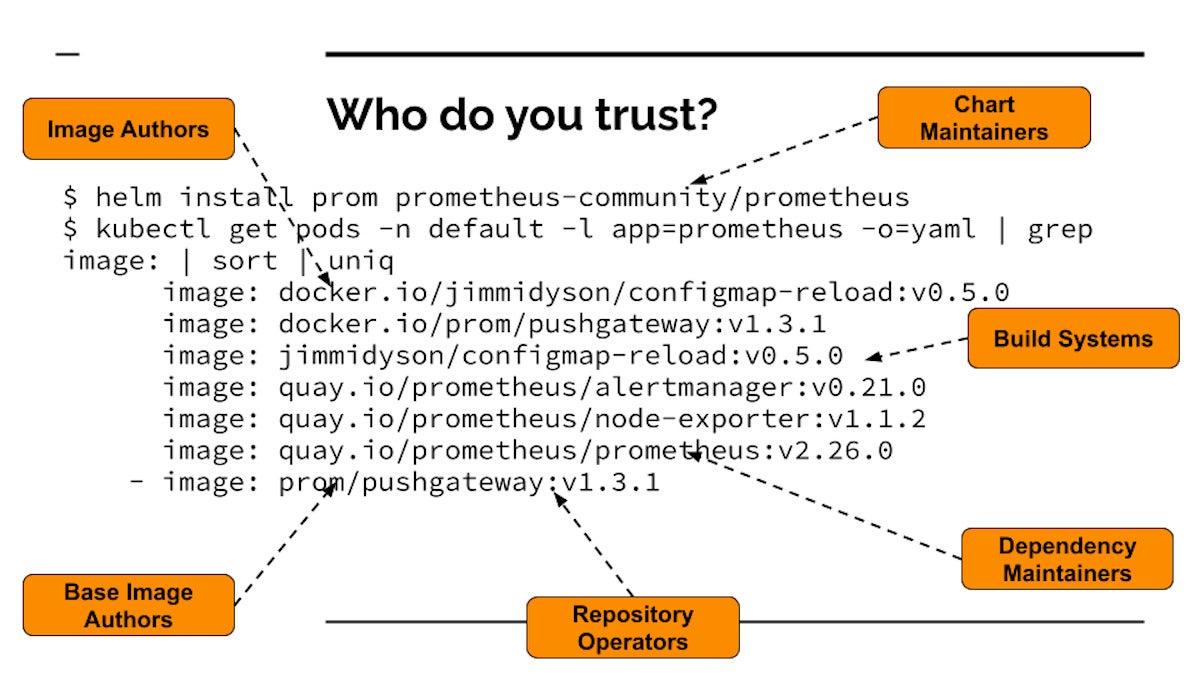
Take an event as commonplace as installing Prometheus (a popular open source observability project) from the Cloud Native Computing Foundation (CNCF) artifact hub. If you do your Helm install and then look at all the images that get pulled and start running your cluster, you see many container images that end up running from a simple installation. Developers are entrusting a whole bunch of things to a whole bunch of different people and systems. Every single one of these could be tampered with or attacked, or could be malicious.
 Dan Lorenc
Dan LorencThis is the opposite of Zero Trust—we’re trusting dozens of systems that we don’t know anything about. We don’t know the authors, we don’t know if the code is malicious, and because each image has its own artifacts, the whole supply chain is recursive. So we’re not only trusting the artifacts, but also the people who trusted the dependencies of these artifacts.
We’re also trusting the people who operate the repositories. So if the repository operators get compromised, now the compromisers are part of your trust circle. Anybody controlling one of these repositories could change something and attack you.
Then there’s the build systems. Build systems can get attacked and insert malicious code. That’s exactly what happened with SolarWinds. Even if you know and trust the operators of the images, and the people operating the systems that host the images, if these are built insecurely, then some malware can get inserted. And again it’s recursive all the way down. The dependency maintainers, the build systems they use, the artifact managers that they are hosted on—they’re all undermined.
So when developers install software packages, there are a lot of things they are trusting implicitly, whether they mean to trust them or not.
Software supply chain security gotchas
The worst strategy you can have in software supply chain security is to do nothing, which is what a lot of developers are doing today. They are allowing anything to run on production environments. If you have no security around what artifacts can run, then you have no idea where they came from. This is the worst of the worst. This is not paying attention at all.
Allow-listing specific tags is the next level up. If you go through some of the tutorials around best practices with Kubernetes, this is pretty easy to set up. If you push all your images to a single location, you can at least restrict things to that location. That’s way better than doing nothing, but it’s still not great, because then anything that gets pushed there is now inside your trust circle, inside that barbed wire fence, and that’s not really Zero Trust. Allow-listing specific repositories has all the same limitations of allow-listing specific tags.
Even the signing schemas in supply chain security are papering over the same problem. Anything that gets signed now gets to run, regardless of where it came from, which leads to tons of attacks tied to tricking someone to sign the wrong thing, or being unable to revoke a certificate.
Time to start asking the right questions
Let’s say you’re walking down the sidewalk outside of your office, and you find a USB thumb drive sitting on the ground. I hope everyone knows that you should absolutely not take that drive inside your office and plug it into your workstation. Everyone in software should (rightly) be screaming, “No!” Real attacks have happened this way, and security orgs across the world hammer this warning into all employees as part of training.
But for some reason, we don’t even pause to think twice before running docker pull or npm install, even though these are arguably worse than plugging in a random USB stick. Both situations involve taking code from someone you do not trust and running it, but the Docker container or NPM package will eventually make it all the way into your production environment!
The essence of this supply chain security evolution is that as an industry we’re moving away from trusting where the software artifacts come from, and spending much more time figuring out roots of trust for what the artifact is.
Who published this binary? How was it built? What version of the tool was used? What source was it built from? Who signed off on this code? Was anything tampered with? These are the right questions to be asking.
Next week, we’ll look at the fast-evolving open source landscape that is forming a new security stack for supply chain security, and unpack essential concepts developers need to understand—from roots of trust, to provenance, to TPM (Trusted Platform Module) attestation.
Dan Lorenc is CEO and co-founder of Chainguard. Previously he was staff software engineer and lead for Google’s Open Source Security Team (GOSST). He has founded projects like Minikube, Skaffold, TektonCD, and Sigstore.
—
New Tech Forum provides a venue to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to newtechforum@infoworld.com.