Qubole review: Self-service big data analytics
Cloud-native data platform puts Spark, Presto, Hive, and Airflow at your fingertips, while controlling your cloud spending






Contributor, InfoWorld |

-
Qubole
Billed as a cloud-native data platform for analytics, AI, and machine learning, Qubole offers solutions for customer engagement, digital transformation, data-driven products, digital marketing, modernization, and security intelligence. It claims fast time to value, multi-cloud support, 10x administrator productivity, a 1:200 operator-to-user ratio, and lower cloud costs.
 InfoWorld
InfoWorldWhat Qubole actually does, based on my brief experience with the platform, is to integrate a number of open-source tools, and a few proprietary tools, to create a cloud-based, self-service big data experience for data analysts, data engineers, and data scientists.
Qubole takes you from ETL through exploratory data analysis and model building to deploying models at production scale. Along the way, it automates a number of cloud operations, such as provisioning and scaling resources, that can otherwise require significant amounts of administrator time. Whether that automation actually will allow a 10x increase in administrator productivity or a 1:200 operator-to-user ratio for any specific company or use case is not clear.
Qubole tends to pound on the concept of “active data.” Basically, most data lakes—which are essentially file stores filled with data from many sources, all in one place but not in one database—have a low percentage of data that is actively used for analysis. Qubole estimates that most data lakes are 10% active and 90% inactive, and predicts that it can reverse that ratio.
Competitors to Qubole include Databricks, AWS, and Cloudera. There are a number of other products that only compete with some of Qubole’s functions.
Databricks builds notebooks, dashboards, and jobs on top of a cluster manager and Spark; I found it a useful platform for data scientists when I reviewed it in 2016. Databricks recently open-sourced its Delta Lake product, which provides ACID transactions, scalable metadata handling, and unified streaming and batch data processing to data lakes to make them more reliable and to help them to feed Spark analysis.
AWS has a wide range of data products, and in fact Qubole supports integrating with many of them. Cloudera, which now includes Hortonworks, provides data warehouse and machine learning services as well as a data hub service. Qubole claims that both Databricks and Cloudera lack financial governance, but you can implement governance yourself at the single-cloud level, or by using a multi-cloud management product.
 IDG
IDG
Qubole architecture overview. Note the six open-source big data products incorporated, shown in the lower half of the blue box.
How Qubole works
Qubole integrates all its tools within a cloud-based and browser-based environment. I’ll discuss the pieces of the environment in the next section of this article; in this section I’ll concentrate on the tools.
Qubole accomplishes cost control as part of its cluster management. You can specify that clusters use a specific mix of instance types, including spot instances when available, and the minimum and maximum number of nodes for autoscaling. You can also specify the length of time any cluster will continue to run in the absence of load, to avoid “zombie” instances.
Spark
In his August InfoWorld article, “How Qubole addresses Apache Spark challenges”, Qubole CEO Ashish Thusoo discusses the benefits and pitfalls of Spark, and how Qubole remediates difficulties such as configuration, performance, cost, and resource management. Spark is a key component of Qubole for data scientists, allowing easy and fast data transformation and machine learning.
Presto
Presto is an open source distributed SQL query engine for running interactive analytic queries against data sources of all sizes, ranging from gigabytes to petabytes. Presto queries run much faster than Hive queries. At the same time, Presto can see and use Hive metadata and data schemas.
Hive
Apache Hive is a popular open-source project in the Hadoop ecosystem that facilitates reading, writing, and managing large data sets residing in distributed storage using SQL. Structure can be projected onto data already in storage. Hive query execution runs via Apache Tez, Apache Spark, or MapReduce. Hive on Qubole can do workload-aware autoscaling and direct writes; open-source Hive lacks these cloud-oriented optimizations.
The founders of Qubole were also the creators of Apache Hive. They started Hive at Facebook and open sourced it in 2008.
Quantum
Quantum is Qubole’s own serverless, autoscaling, interactive SQL query engine that supports both Hive DDL and Presto SQL. Quantum is a pay-as-you-go service that is cost-effective for sporadic query patterns that spread across long periods, and has a strict mode to prevent unexpected spending. Quantum uses Presto, and complements having Presto server clusters. Quantum queries are limited to 45 minute runtimes.
Airflow
Airflow is a Python-based platform to programmatically author, schedule, and monitor workflows. The workflows are directed acyclic graphs (DAGs) of tasks. You configure the DAGs by writing pipelines in Python code. Qubole offers Airflow as one of its services; it is often used for ETL.
The new QuboleOperator can be used just like any other existing Airflow operator. During the execution of the operator in the workflow, it will submit a command to Qubole Data Service and wait until the command finishes. Qubole supports file and Hive table sensors that Airflow can use to programmatically monitor workflows.
To see the Airflow user interface, you first need to start an Airflow cluster, then open the cluster page to see the Airflow website.
RubiX
RubiX is Qubole’s lightweight data caching framework that can be used by a big data system that uses a Hadoop file system interface. RubiX is designed to work with cloud storage systems such as Amazon S3 and Azure Blob Storage, and to cache remote files on a local disk. Qubole has released RubiX to open source. Enabling RubiX in Qubole is a matter of checking a box.
What does Qubole do?
Qubole provides an end-to-end platform for analytics and data science. The functionality is distributed among a dozen or so modules.
The Explore module lets you view your data tables, add data stores, and set up data exchange. On AWS, you can view your data connections, your S3 buckets, and your Qubole Hive data stores.
The Analyze and Workbench modules allow you to run ad hoc queries on your data sets. Analyze is the old interface, and Workbench is the new interface, which was still in beta when I tried it. Both interfaces allow you to drag and drop data fields to your SQL queries, and to choose the engine you use to run the operations: Quantum, Hive, Presto, Spark, a database, a shell, or Hadoop.
Smart Query is a form-based SQL query builder for Hive and Presto. Templates allow you to re-use parameterized SQL queries.
Notebooks are Spark-based Zeppelin or (in beta) Jupyter notebooks for data science. Dashboards provide an interface for sharing your explorations, without allowing access to your notebooks.
Scheduler lets you run queries, workflows, data imports and exports, and commands automatically at intervals. That complements the ad-hoc queries you can run in the Analyze and Workbench modules.
The Clusters module allows you to manage your clusters of Hadoop/Hive, Spark, Presto, Airflow, and deep learning (beta) servers. Usage lets you track your cluster and query usage. The Control Panel lets you configure the platform, either for yourself, or for others if you have system administration permissions.
Qubole end-to-end walk-through
I went through a walk-through of importing a database, creating a Hive schema, and analyzing the result with Hive and Presto, and separately in a Spark notebook. I also looked at an Airflow DAG for the same process, and at a notebook for doing machine learning with Spark on an unrelated data set.
 IDG
IDG
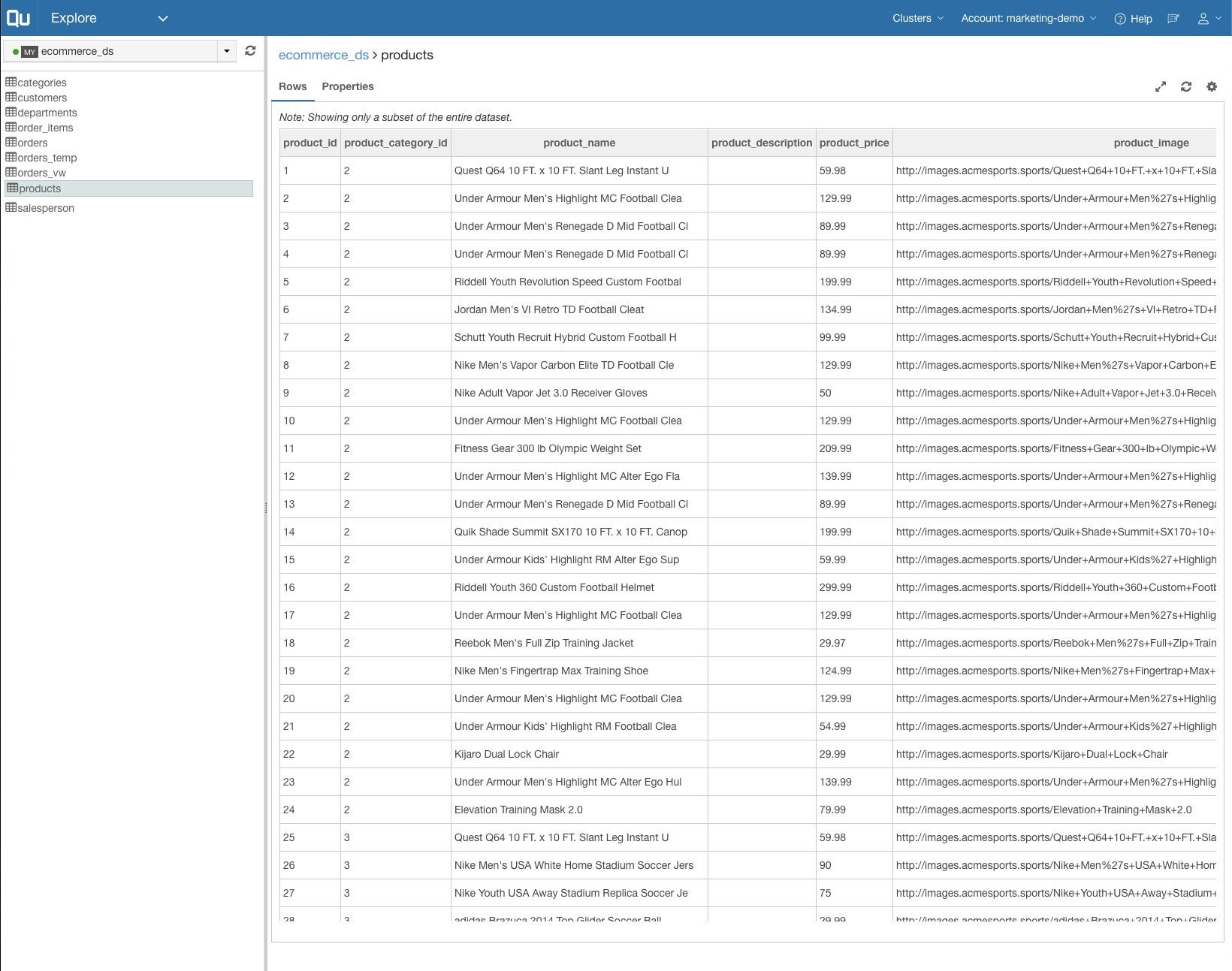
In Qubole’s Explore module you can manage and examine your data sources. Here we are looking at a few rows of a MySQL table that we will be importing for analysis.
 IDG
IDG
Before importing data into Hive, you need to create the schema.
 IDG
IDG
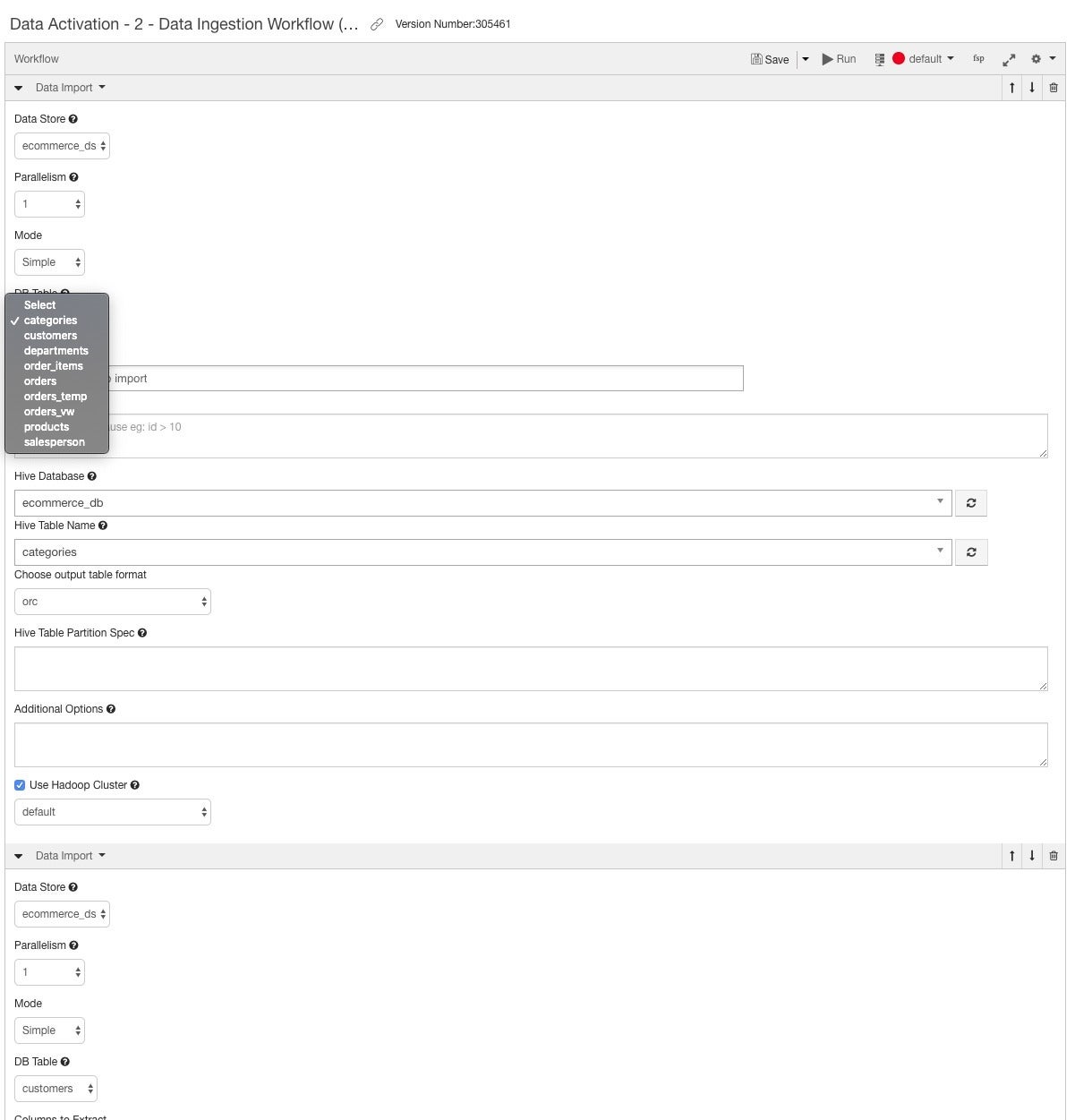
To define a data import for Hive, you set up import workflows for each table you want to load. Qubole helps by letting you browse data stores and tables. ORC format is an optimized column-oriented data storage format for Hive.
 IDG
IDG
Presto is usually a more efficient way of running ad hoc SQL queries against Hive data than Hive’s own SQL query engine. Here we are figuring out the number of views of each product by parsing the web log for references to product pages and counting them. The regular expression in line 3 reformats the web URL as brand plus product name. The access_logs table is an external table constructed by parsing the web logs into fields with another regular expression.
 IDG
IDG
In this Presto query we join the product and order items tables to construct a list of items ordered by quantity.
 IDG
IDG
Presto can handle nested SQL selects with aplomb. Here the inner query excludes canceled and fraudulent orders, joins the orders and order_items tables, and sums orders to calculate revenues. The outer query joins the products table with the results of the inner query and reports revenue by product name.
 IDG
IDG
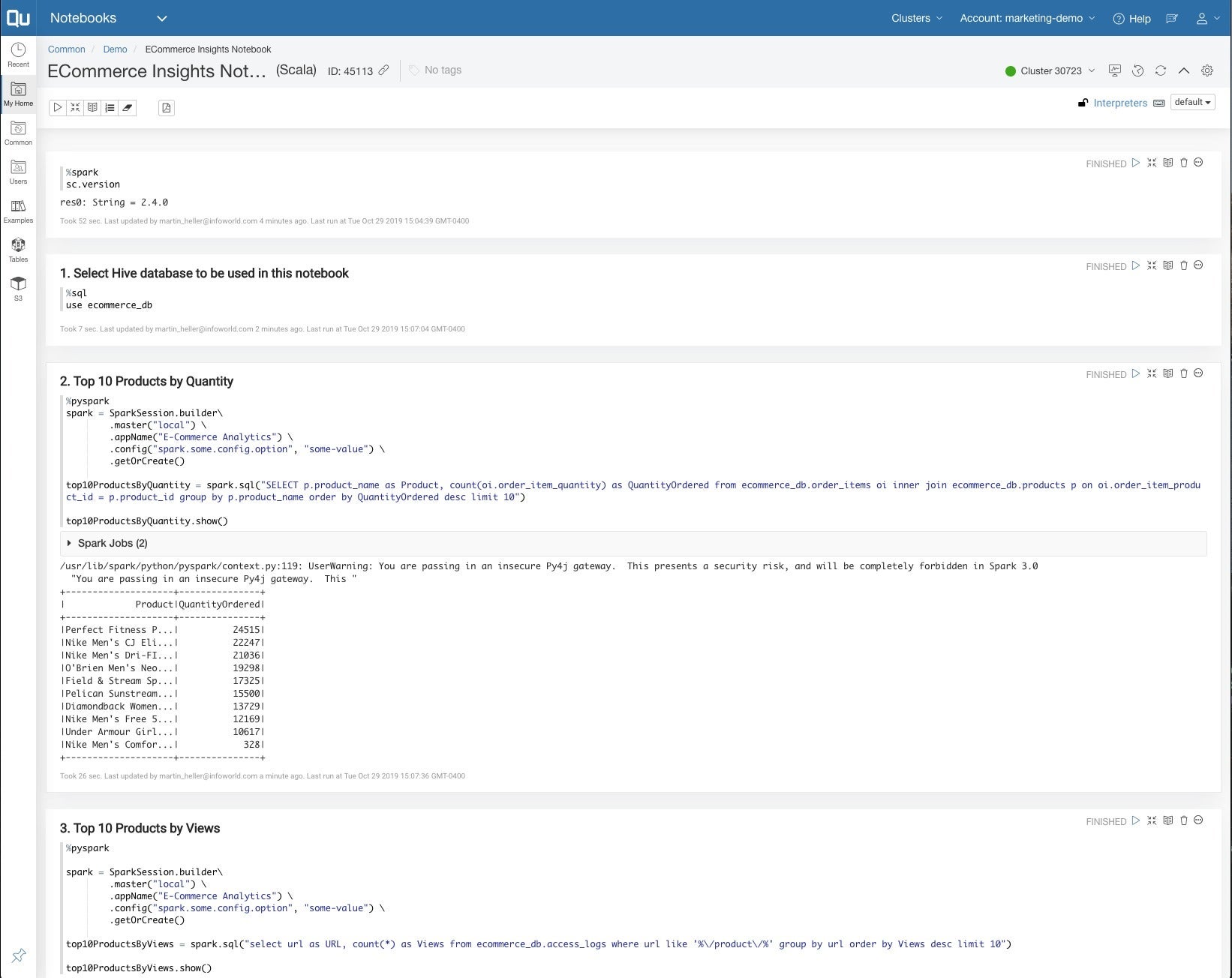
An alternative to running stand-alone Presto queries is to run the same SQL in Spark. Here we are using a Zeppelin notebook with cells in Spark, SQL, and PySpark to run some of the same queries as we tested in Presto. The message about an insecure Py4j gateway is only a warning, and doesn’t actually matter given the isolated network configuration of Qubole.
 IDG
IDG
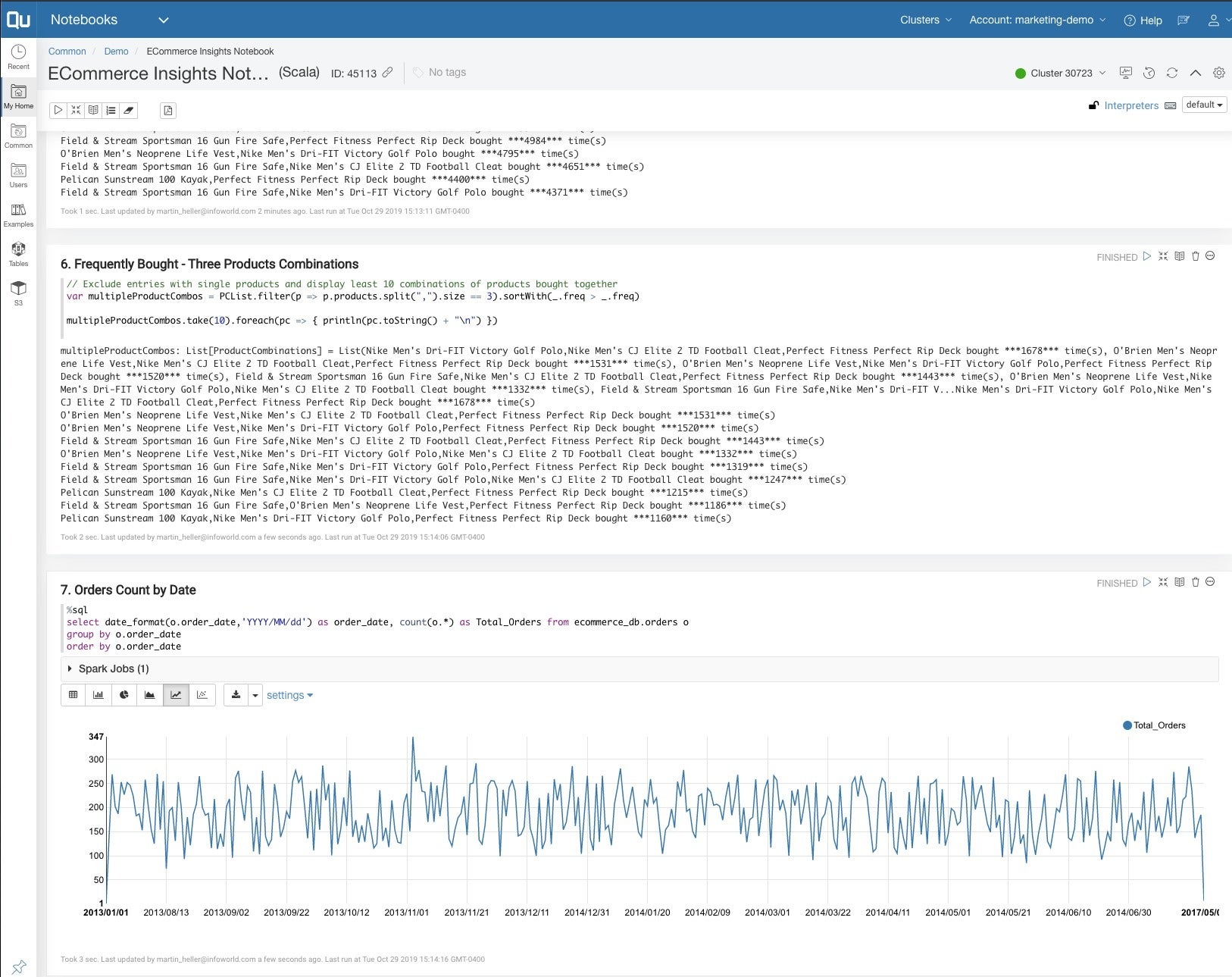
The Zeppelin notebook cell at the bottom (7) counts orders per day by running Spark SQL. The Zeppelin notebook is able to graph the results as well as display them in a table. This cell could be exported to a dashboard for the use of managers.
 IDG
IDG
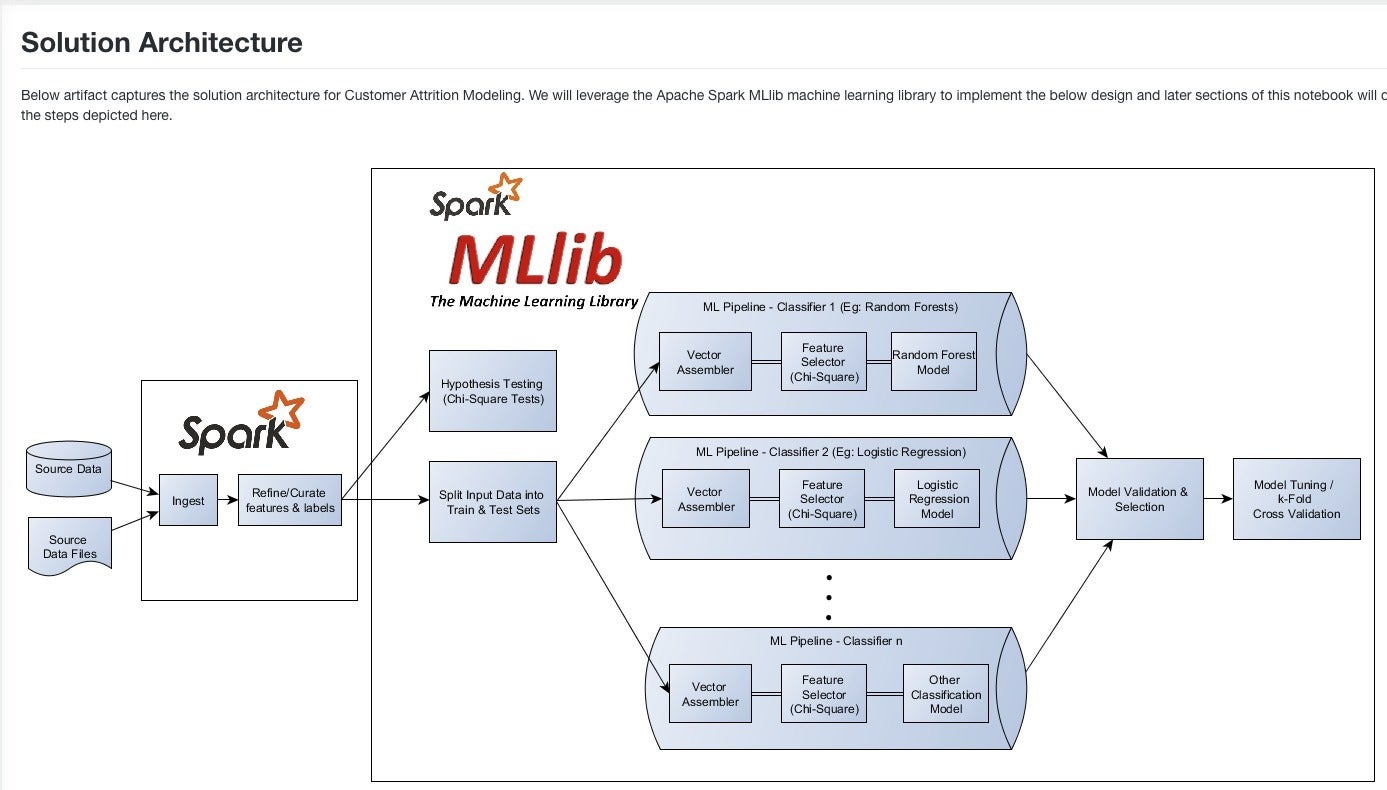
Spark notebooks are often used for machine learning with MLlib. This figure shows the end-to-end process of ingesting the data, performing feature engineering, training three machine learning models, selecting the best model, and tuning the best model. The data set used here, provided by UC Irvine, contains Telco customer attrition data, and the models are trying to predict whether a given customer will “churn.”
 IDG
IDG
The code shown in the Spark cell fits three models to the same training data set. The models are Random Forest, Logistic Regression, and Gradient Boosted Trees (GBT). Training all three models took 40 seconds. The GBT model produced a predictor with a high false positive rate and a low true positive rate (C), so it needed to be reversed (C') to be useful, as shown in the lower cell.
 IDG
IDG
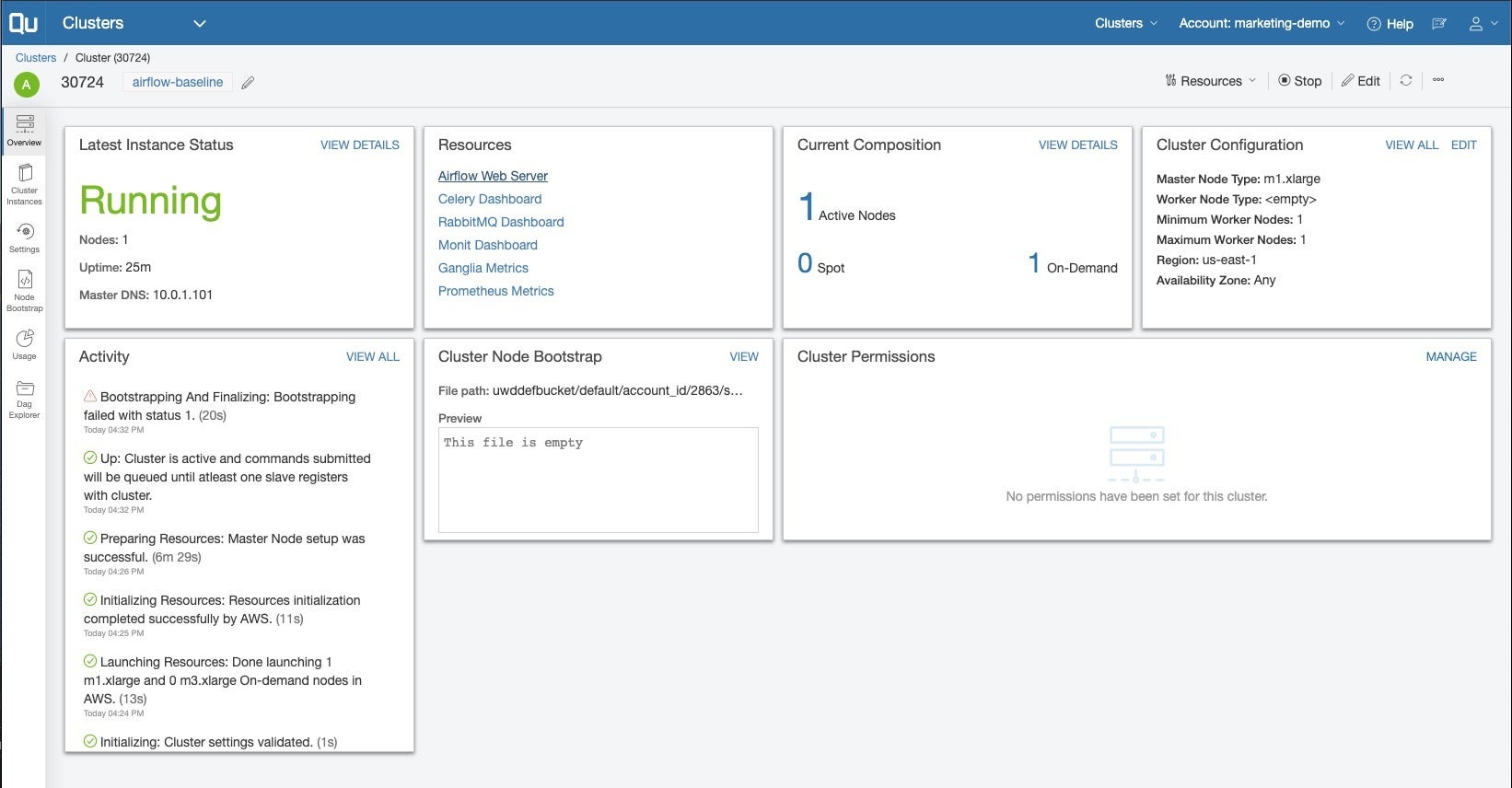
Overview page for an Airflow cluster. The user interface to Airflow can be reached through the Airflow Web Server link in the resources box. The integration of Airflow is not as tight as we’ve seen for the other components of Qubole.
 IDG
IDG
Airflow code is written in Python. This Airflow DAG reproduces the same workflow as we ran earlier in manual Hive and Presto steps, and again in Zeppelin notebooks using Spark. The configuration on line 19 schedules the DAG to run daily. Note that the guts of each action are contained in HQL scripts, and that the DAG makes heavy use of the QuboleOperator module.
 IDG
IDG
An Airflow DAG can be viewed in several representations. Here we see the e-commerce data set import and analysis in the graph view. Note the green outlines for all the cells, indicating that they ran successfully.
 IDG
IDG
The tree view is an alternative way to view an Airflow DAG. Note that in this view the flow runs more or less from right to left and bottom to top, and the status colors are applied to the boxes on the right. This particular DAG starts at the start circle on line 9, moves up and to the left, but splits down and out for the two join steps.
Deep learning in Qubole
We’ve seen data science in Qubole up to the level of classical machine learning, but what about deep learning? One way to accomplish deep learning in Qubole is to insert Python steps in your notebooks that import deep learning frameworks such as TensorFlow and use them on the data sets already engineered with Spark. Another is to call out to Amazon SageMaker from notebooks or Airflow, assuming that your Qubole installation runs on AWS.
Most of what you do in Qubole doesn’t require running on GPUs, but deep learning often does need GPUs to allow training to complete in a reasonable amount of time. Amazon SageMaker takes care of that by running the deep learning steps in separate clusters, which you can configure with as many nodes and GPUs as needed. Qubole also offers Machine Learning clusters (in beta); on AWS these allow for accelerated g-type and p-type worker nodes with Nvidia GPUs, and on Google Cloud Platform and Microsoft Azure they allow for equivalent accelerated worker nodes.
Big data toolkit in the cloud
Qubole, a cloud-native data platform for analytics and machine learning, helps you to import data sets into a data lake, build schemas with Hive, and query the data with Hive, Presto, Quantum, and Spark. It uses both notebooks and Airflow to construct workflows. It can also call out to other services and use other libraries, for example the Amazon SageMaker service and the TensorFlow Python library for deep learning.
Qubole helps you to manage your cloud spending by controlling the mix of instances in a cluster, starting and autoscaling clusters on demand, and shutting clusters down automatically when they are not in use. It runs on AWS, Microsoft Azure, Google Cloud Platform, and Oracle Cloud.
Overall, Qubole is a very good way to take advantage of (or “activate”) your data lake, isolated databases, and big data. You can test drive Qubole free for 14 days on your choice of AWS, Azure, or GCP with sample data. You can also arrange a free full-featured trial for up to five users and one month, using your own cloud infrastructure account and your own data.
—
Cost: Test and trial accounts, free. Enterprise platform, $0.14 per QCU (Qubole Compute Unit) per hour.
Platform: Amazon Web Services, Google Cloud Platform, Microsoft Azure, Oracle Cloud.
Copyright © 2019 IDG Communications, Inc.