Building on the rampant popularity of Python was always going to be a good idea for the Facebook-born PyTorch, an open source machine learning framework. Just how good of an idea, however, few could have guessed. That’s because no matter how many things you get right when launching an open source project (great docs, solid technical foundation, etc.), there is always an element of luck to a project’s success.
Well, consider PyTorch lucky, then. Or blessed. Or something. Because it’s booming and, if analyst Thomas Dinsmore is to be believed, “By the end of [2020] PyTorch will have more active contributors than TensorFlow.” More contributors and more adoption? That’s a big jump for a rival to TensorFlow, long considered the industry default since its public release in 2015.
Wild and crazy adoption
As detailed in OpenHub, TensorFlow and PyTorch are running neck-and-neck in terms of 12-month contributor totals: TensorFlow (906) and PyTorch (900). This represents huge progress by the PyTorch community, given TensorFlow’s head start, and is reflected in the growth in PyTorch’s user community, as reflected in Jeff Hale’s analysis of job posting sites for data scientist roles:
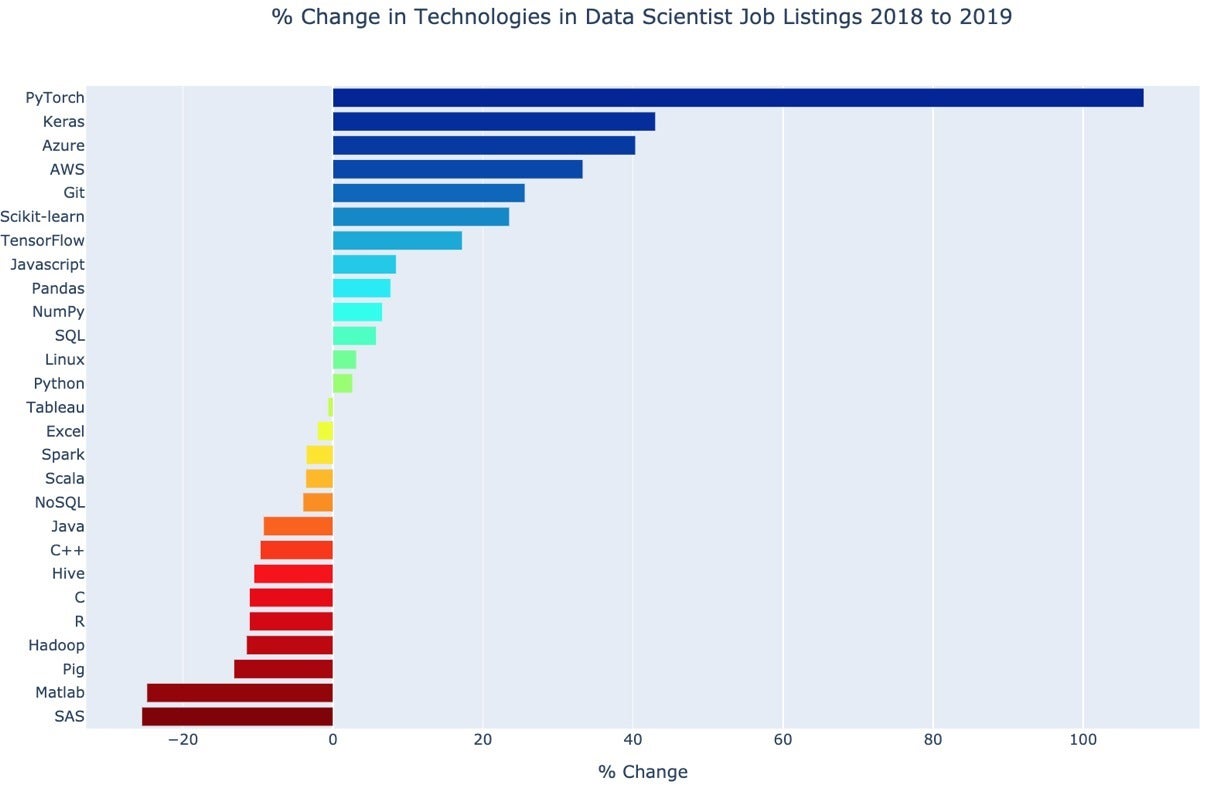{kind=link}
To be clear, this analysis reflects relative growth or decline over the past year. The TensorFlow user community is still much larger than PyTorch’s, though in academics PyTorch has gone from distant minority to overwhelming majority almost overnight. All things considered, it’s not hard to see PyTorch quickly bridging the gap at this pace.
Particularly given PyTorch’s comparative advantages. Did I mention Python?
Lowering the bar to data science
As Serdar Yegulalp wrote back in 2017 at the launch of PyTorch, “A chief advantage to PyTorch is that it lives in and allows the developer to plug into the vast ecosystem of Python libraries and software. Python programmers are also encouraged to use the styles they’re familiar with, rather than write code specifically meant to be a wrapper for an external C/C++ library.” This means that PyTorch has always had the advantage of approachability. The documentation is excellent and there’s a healthy community of developers happy to help out.
This advantage is further accentuated by PyTorch’s computational graph setup. As Savan Visalpara explains:
TensorFlow is ‘Define-and-Run,’ whereas PyTorch is ‘Define-by-Run.’ In [a] Define-and-Run framework, one would define conditions and iterations in the graph structure then run it. In [a] Define-by-Run [framework, the] graph structure is defined on-the-fly during forward computation, [which is a more] natural way of coding.
Dhiraj Kumar concurs, arguing that such a dynamic model allows data scientists to “fully see each and every computation and know exactly what is going on.”
To be sure, with the release of TensorFlow 2.0, Google has made TensorFlow “eager by default.” As Martin Heller explains, “Eager execution means that TensorFlow code runs when it is defined, as opposed to adding nodes and edges to a graph to be run in a session later, which was TensorFlow’s original mode.”
While this sounds great for TensorFlow because it helps the framework compete better with PyTorch in terms of ease of use, “In enabling Eager mode by default, TensorFlow forces a choice onto their users — use eager execution for ease of use and require a rewrite for deployment, or don’t use eager execution at all.
While this is the same situation that PyTorch is in, the opt-in nature of PyTorch’s TorchScript is likely to be more palatable than TensorFlow’s ‘Eager by default,’” warns Horace He. TensorFlow Eager mode also suffers from performance issues, though we’d expect these to improve over time.
In sum, while the market still leans heavily on TensorFlow, PyTorch’s easy-to-learn, straightforward-to-use approach that ties into the world’s most popular programming language for data science is proving a winner. Although academia has been fastest to embrace PyTorch, we should expect to see ever-increasing adoption with the enterprise set, too.