InfoWorld’s 2020 Technology of the Year Award winners
InfoWorld recognizes the year’s best products in software development, cloud computing, data analytics, and machine learning















InfoWorld’s 2020 Technology of the Year Award winners
Are you digitally transformed yet? If “digital transformation” means anything, it means taking advantage of the latest innovations in software development, cloud computing, data analytics, and artificial intelligence to improve your business. Yes, it’s all about the software and the data these days. Nobody won the contract and got the promotion because they bought their servers from Dell.
Today’s winners win because their software is smarter, their data is fresher, their processes are more nimble, and their analytics are deeper than the competition. Where do you find the tools that deliver this magic? A good place to start is InfoWorld’s Technology of the Year Awards, our annual celebration of the best and most innovative products in the information technology landscape.
Click on to meet our 12 winning products for 2020.

Tableau
Tableau has dramatically changed how people work with data and analytics. Tableau Software established the self-service BI category and enabled business users to ask questions, explore data sources, build dashboards, and tell stories with data. Then they added Tableau Server and a SaaS version, Tableau Online, to help users share data sources, workbooks, and dashboards across departments and organizations.
While there are other products in the self-service BI category, Tableau continued to lead and innovate in 2019 with new AI features for Tableau users. Ask Data is a feature that allows users to query published data sources with natural language and automatically generate data visualizations. Another feature, Explain, can be used to better understand data outliers by reviewing the underlying data through charts that Tableau generates. Tableau also saw upgrades to tables, sharing, and maps.
Tableau Software also made it easier for application developers to embed visualizations within their applications. They improved Tableau’s webhooks for creating automated workflows and added sandboxed extensions to speed up the development process. And they released personal access tokens to enhance security options for automation and API usage. As more organizations aspire to be data-driven, Tableau’s innovations continue to make it easier to discover and share analytics and insights.
— Isaac Sacolick
Atlassian Jira Software
Atlassian’s Jira Software has become synonymous with agile development teams. Small organizations new to agile can start quickly by using Jira’s backlog and scrum boards to manage user stories, sprints, and releases. Larger organizations can organize multiple agile teams, standardize workflows, establish key performance indicators, and integrate with other collaboration tools. Software developers can connect Jira issues to their code, and product managers can use the portfolio to track their roadmaps.
In 2019, Atlassian completed seven Jira Software 8.x releases that improved the platform’s performance, usability, and extensibility. They launched the Jira Server mobile app, which helps agile team members create and update Jira issues on the go. They made significant performance improvements to viewing boards and backlogs, searching Jira issues, and re-indexing. The product has received many usability improvements including enhancements to Scrum and Kanban boards, email notifications, user administration, and search improvements. Atlassian also made many administrative improvements needed by larger organizations such as issue archiving and templates for deploying Jira Server in a Docker container.
Agile team leaders love Jira because they can start with basic configurations and customize it when and where needed. In this way, development organizations can be iterative and agile in implementing their Jira configurations, workflows, integrations, and reports.
— Isaac Sacolick

Datadog
A cloud-based monitoring and analytics platform built for modern, distributed applications and infrastructures, Datadog goes far beyond basic traces and log file parsing, applying machine learning and statistical analysis to the data ingested from infrastructure beacons, application performance monitors, and error logs to provide a global view of system, application, and service health. Datadog has kept pace with the latest infrastructure trends, allowing you to instrument today’s modern architectures and ephemeral container-based apps.
Datadog digs into everything from bare-metal servers and virtual machines to public cloud infrastructures and serverless microservices. Alerts keep you abreast of real-time usage patterns and dependency errors before they become service disruptions. Graphical dashboards let you search and drill down on CPU metrics and code-level insights for quick root-cause analysis. Newly minted monitoring tools even extend Datadog’s reach into network data flows and user interactions, offering truly end-to-end visibility.
Datadog’s open source monitoring agents support most major operating systems. And its growing library of integration services offer performance metrics for databases, messaging queues, and web frameworks. Even chat and collaboration tools, like Slack, can be added to your Datadog dashboards with drag-and-drop ease, helping to keep your team productive. Bringing visibility to complex, even hybrid apps and services in distributed compute environments, Datadog could be a devops team’s best friend.
— James R. Borck
HashiCorp Terraform
The power and promise of HashiCorp Terraform can be summed up in three words: infrastructure as code. You use configuration files to tell Terraform what you want your infrastructure to look like — the desired state. Terraform not only builds it to match your definition, but keeps it in sync with your changes and makes sure those changes don’t break your deployment.
Terraform is designed to be agnostic — it doesn’t care what you’re building or where you want to build it. Chances are Terraform already supports the public cloud or local infrastructure you’re using, or has a third-party plug-in for it. The result is a blueprint for your deployment that can be shared, versioned, and reused — and easily adapted for new deployment targets. Goodbye cloud lock-in.
Terraform definitions cover most every aspect of IT infrastructure: compute, networking, storage, connections to third-party services (PagerDuty, GitHub, Cloudflare, etc.), even other infrastructure systems like Kubernetes or OpenStack. Naturally, Terraform also integrates with HashiCorp Vault to store secrets that might be needed during the provisioning process.
— Serdar Yegulalp
PyTorch
PyTorch had a great 2019. Not only did PyTorch 1.0 arrive with a host of new features including production deployment using TorchScript and a new JIT runtime, PyTorch Mobile, and a new hub for hosting pre-trained models, but last year PyTorch became the dominant platform among researchers, as represented in papers presented at machine learning conferences around the world. Not only has Google’s TensorFlow taken many cues from the eager-evaluation approach PyTorch has popularized, but even some Google researchers have published papers based on PyTorch rather than TensorFlow.
With PyTorch support now available in the data science packages of all the major cloud providers (including the important Alibaba Cloud for research in China), and pure PyTorch in production at Facebook, Uber, Salesforce, and beyond, PyTorch has emerged as a serious challenger to TensorFlow for machine learning applications all the way from research and development to cloud-scale deployments. Expect to see more support for mobile-optimized models and other aspects of production usage throughout 2020 — including the just-released, tell-tale sign of enterprise acceptance. Yes, PyTorch 1.4 includes Java bindings! (Read InfoWorld’s PyTorch review.)
— Ian Pointer

Databricks Unified Data Analytics Platform
The Databricks Unified Data Analytics Platform is far more than a packaging of the open source Apache Spark runtime and a custom Jupyter-like notebook interface. It’s a cloud-native system that, yes, does include on-the-fly generation of clusters whenever needed, but also includes an optimized runtime that can be up to 50 times faster than standard Apache Spark cloud read/write operations; an integrated machine learning service supporting experiment tracking, model management, hyperparameter search, and deployment; and real-time collaboration in notebooks complete with full versioning and permissions.
While parts of the Databricks platform, including Apache Spark, MLflow, and Delta Lake, are indeed open source, Databricks combines them all together in an impressively integrated manner, creating a one-stop shop for data science. The Databricks platform is capable of handling all aspects of the pipeline from development to production and beyond, scaling from small teams to massive organizations with full security and auditing features that an enterprise demands, without the operational overhead that many big data solutions require. Plus, you’ll always be running on the leading edge of machine learning and Apache Spark development.
— Ian Pointer

Snowflake
A data warehouse as a service available in AWS, Microsoft Azure, and Google Cloud, Snowflake jumpstarts data analysis without the typical avalanche of requirements for technical expertise or steep up-front provisioning costs. But perhaps the best thing about Snowflake is the cloud-native architecture that separates compute from storage, allowing users to scale up and down on the fly, without delay or disruption, even while queries are running.
Snowflake’s unique cloud architecture creates virtualized warehouses — not full physical clones, but pointers and metadata based on a centralized storage layer. These virtual snapshots improve data duplication speed and eliminate per-warehouse storage charges. And because each independent warehouse has its own compute resources, queries run unthrottled and multiple analysts don’t step on each other trying to access the same underlying data source.
Beneath the covers, Snowflake simplifies life for the data engineer, transparently managing all data structures, indexes, partitions, caches, and performance tuning. Your data is always available and ready for exploration. Snowflake’s additional management layer makes data sharing easy and safe, with automatic encryption and solid tools for authentication and access control.
In all, Snowflake offers a fast and easy path to large-scale data analysis, with the performance you need exactly when you need it, and you only pay for the compute you use. (Read InfoWorld’s Snowflake review.)
— James R. Borck
Kinetica Active Analytics Platform
Kinetica Active Analytics Platform combines a distributed, in-memory, GPU-accelerated database with streaming analytics, location intelligence, and machine learning. The database — vectorized, columnar, memory-first, and designed for analytical (OLAP) workloads — automatically distributes any workload across CPUs and GPUs. It uses SQL-92 for a query language, much like PostgreSQL and MySQL, and supports an extended range of capabilities, including text search, time series analysis, location intelligence, and graph analytics.
Kinetica can operate on the entire data corpus by intelligently managing data across GPU memory, system memory, disk, SSD, HDFS, and cloud storage such as Amazon S3. With distributed parallel ingest capabilities, Kinetica can perform high-speed ingestion of streaming data sets (with Kafka) and complex analytics on streaming and historical data simultaneously. You can train TensorFlow models against data directly in Kinetica or import pre-trained TensorFlow or “black box” models to execute inferences.
Kinetica also has a GPU-accelerated library of geospatial functions to perform on-demand filtering, aggregation, time-series, geo-join, and geofence analysis. And it can display unlimited geometry, heatmaps, and contours, using server-side rendering technology (since client-side rendering of large data sets is extremely time-consuming). (Read InfoWorld’s Kinetica review.)
— Martin Heller

Scylla Enterprise
Imagine rewriting Cassandra from Java to C++, eliminating the scaling and memory-management limitations of the Java virtual machine. Now imagine making every significant I/O operation in the new database asynchronous, to eliminate waits and spin locks. While you’re worrying about I/O, give the database its own I/O scheduler, load balancer, and cache. Finally, introduce a shard-per-core architecture and auto-tuning. Now you’ve got Scylla.
Scylla has additional capabilities beyond Cassandra: materialized views, global and local secondary indexes, workload prioritization, and a DynamoDB-compatible API. The DynamoDB API is in addition to CQL (Cassandra Query Language) and a Cassandra-compatible API.
Scylla boasts single-digit millisecond p99 latencies and millions of operations per second per node. Those two characteristics translate to needing fewer nodes (by a significant factor) than Cassandra. The shard-per-core architecture means that Scylla can take full advantage of multi-core CPUs and multi-CPU servers, allowing Scylla to run well on Amazon i3 and i3en high-I/O bare metal instances (36 cores), while Cassandra does better on smaller 4xlarge instances (8 cores). (Read InfoWorld’s Scylla review.)
— Martin Heller
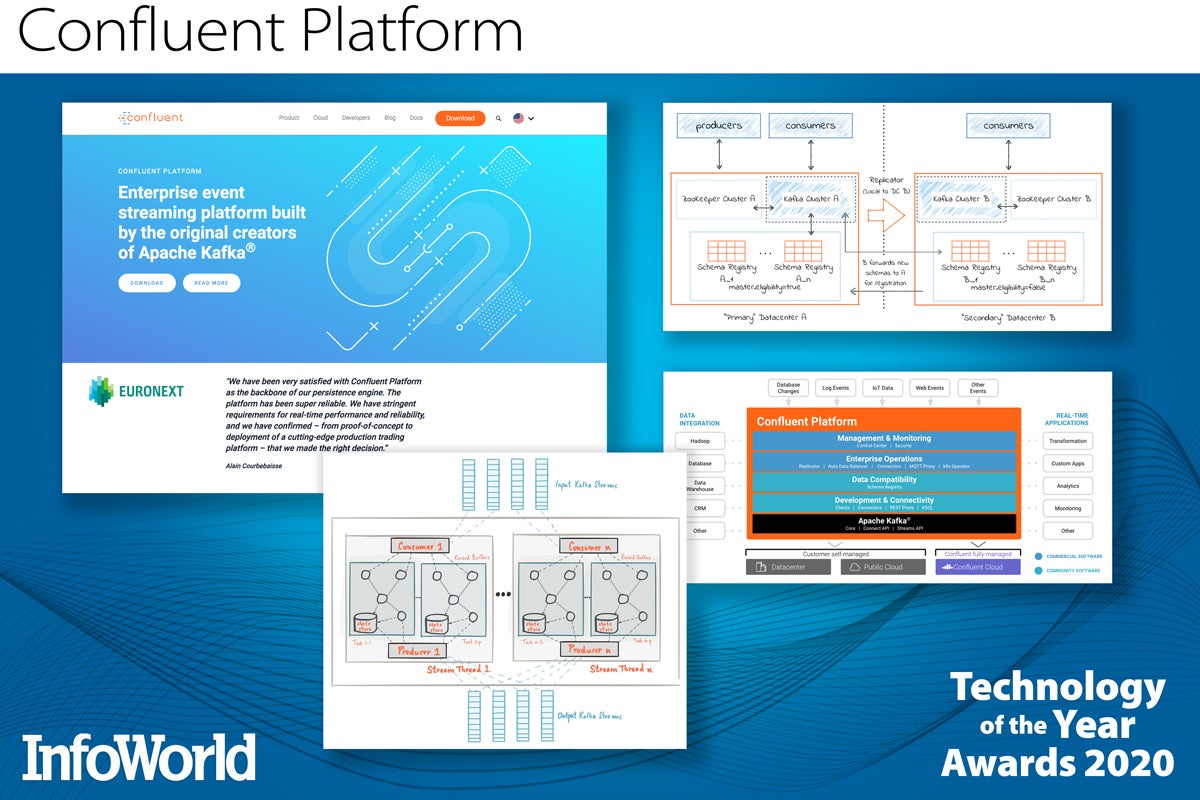
Confluent Platform
Apache Kafka gave the world a common metaphor for handling streaming data and events. The Confluent Platform — from the developers who created Kafka — bolsters the open source distributed streaming platform with enterprise-grade features and commercial support. For example, Confluent’s KSQL lets you query Kafka streams as if they were databases, and Confluent’s Schema Registry helps you identify schema changes that might break your app.
Confluent Platform also adds centralized, GUI-based management, JMS clients and MQTT proxies, connectors to dozens of data sources and sinks, cross-site replication, and deeply integrated role-based access controls. Throw in data balancing and topic replication across nodes, multi-region clusters, and even “tiered storage” (in preview), and Confluent Platform makes deploying, running, and maintaining large Kafka clusters easier than you ever thought possible.
— Serdar Yegulalp
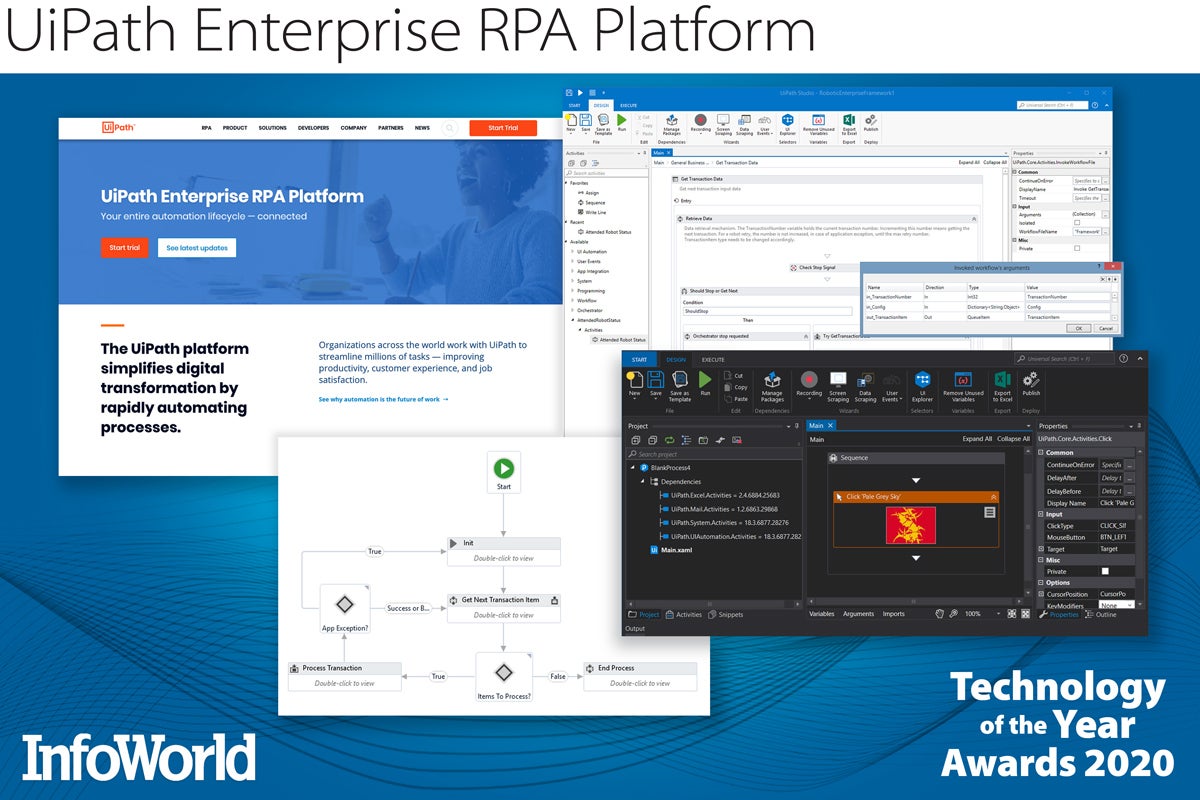
UiPath Enterprise RPA Platform
The UiPath Enterprise RPA Platform represents the best in robotic process automation, the go-to toolkit for automating away the tedium, delays, and errors that plague repetitive front-office tasks. UiPath’s robot agents mimic user actions — keyboard presses and mouse clicks — to process an application form, check a credit limit, or copy data from a PDF into a database.
Real humans can be pulled into the mix when necessary — say, for approvals or in-process exception handling — and multiple automations can be chained together into BPM-style activity flows. Best of all, UiPath accomplishes all of this without disrupting your existing systems and applications. Robots are deployed as browser plug-ins or desktop or server-side agents, and controlled from the UiPath Studio or the UiPath Orchestrator, a web-based central management system for larger deployments.
UiPath gives you all the tools needed to direct Robots to open and close applications, enter keystrokes, and extract data from tables completely unattended. The company recently introduced debugging improvements, a new HA cloud option, and a simpler development environment for less technical users. Using StudioX, business users can quickly build their own bots from a pallet of pre-built activities and actions, without getting bogged down in the underpinnings of automation. (Read InfoWorld’s UiPath review.)
— James R. Borck

Anaconda Enterprise
Anaconda rolls the Python programming language and all of its great math, stats, and machine learning libraries into a single free, open source distribution. Anaconda Enterprise offers everything the Anaconda distribution does, while adding tools for deploying data science projects and their derived insights to Kubernetes infrastructure, either on local hardware or in common cloud environments.
Anaconda Enterprise provides pre-built templates for creating Python, R, Spark/Hadoop, or SAS projects, plus tools for managing those projects and making them redistributable, deploying them as APIs, and handling machine learning models through each phase of the lifecycle (develop, train, deploy, refine). Support is included for the latest generation of the Nvidia CUDA toolkit, allowing projects to take full advantage of GPU acceleration.
— Serdar Yegulalp
Copyright © 2020 IDG Communications, Inc.
