InfoWorld's 2017 Technology of the Year Award winners
InfoWorld editors and reviewers pick the year's best hardware, software, development tools, and cloud services


































2017 Technology of the Year Awards
Did you notice that Google is giving away its magic sauce? Google engineers used to merely write papers about their creations, then leave it to others to come up with the software. Now we’re fortunate to get the real goods, for datacenter orchestration or deep learning or what have you, straight from the source.
Similarly, other cloud juggernauts are solving common problems and sharing the solutions through open source projects. Is it a surprise that Facebook came up with a better way to build mobile apps? Or a better way for clients to fetch data from a server? Maybe not, but you might be surprised by the clever approach Facebook has taken to endpoint security.
You’ll find these and other innovations that were born in, designed for, or inspired by the cloud among our latest Technology of the Year Award winners. Chosen by InfoWorld editors and product reviewers, these are the best tools for app dev, datacenter and cloud ops, data analytics, and information security that we encountered in the past year. Read on to meet our winners.
See also:
Technology of the Year 2017: The best hardware, software, and cloud services
[ InfoWorld's quick guide: Digital Transformation and the Agile Enterprise. | Cut to the key news in technology trends and IT breakthroughs with the InfoWorld Daily newsletter, our summary of the top tech happenings. ]
Amazon Alexa
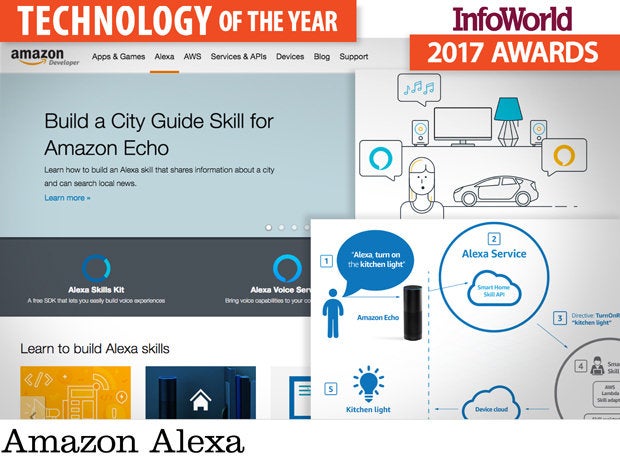
Amazon’s Echo device family has proven to be a huge hit, with both the Echo and the Echo Dot selling out in a Christmas rush. Providing a voice-driven interface to Amazon and partner services, the Echo is a powerful tool, but it’s also an intriguing example of a move to a ubiquitous computing model, using the Amazon Alexa voice recognition tools. Amazon provides a set of tools to build Alexa apps (aka "skills"), taking advantage of AWS Lambda’s serverless compute to only run apps when triggered by an Echo device.
Alexa skills can be used to connect to general-purpose web services, allowing users to access existing and new web content and services through voice commands, by linking service requests to user “utterances.” More specific APIs provide access to home automation (“Alexa, turn on the kitchen lights”) and IoT devices (“Alexa, what’s the temperature in the kid’s room?”), while still other APIs trigger the delivery of quick packets of narrated information.
Many may see Echo as another avenue for Amazon to sell products, and that’s certainly true. For developers, it also lets them deliver AWS apps to users, especially apps that can use AWS to reflect messages from Alexa to IoT devices. It’s a lot easier to say, “Alexa, turn on the office lights,” than to track down the right app for the right lights on a smartphone loaded with countless other apps. Echo and Alexa make natural user interfaces, well, natural. That’s good news for developers and IoT.
-- Simon Bisson
TensorFlow
While many large tech companies have built popular services that feature AI-based speech recognition, natural language parsing, and language translation, by most measures the leader in this field is Google. Underneath the covers, the Translate, Maps, Search, and Google Now services all depend on one machine learning and neural network library, TensorFlow. Given that TensorFlow has been open source since 2015, you can apply Google's secret sauce to your own projects once you learn how.
I'm not claiming that TensorFlow is easy to learn or use, but if you have the necessary background in Python, calculus, statistics, and deep learning and are willing to put in the effort, you'll find TensorFlow a useful, powerful, portable, and widely applicable library. The package itself can handle all sorts of neural networks, including the deep convolutional networks and long short-term memory (LSTM) recurrent models that are currently transforming the image recognition and language processing fields. The code for defining layers may be a little more detailed than is convenient, but you can fix that with any of three optional deep learning interfaces. While debugging an asynchronous network solver can be nontrivial, the TensorBoard software helps by letting you visualize the graph.
You can install TensorFlow locally or use the cloud. Perhaps the most powerful way you can use TensorFlow is to set up a Google Cloud Platform project with Cloud Machine Learning in conjunction with a local TensorFlow installation. Perhaps the easiest way to use TensorFlow is to spin up a Deep Learning AMI on Amazon Linux, which already has TensorFlow and four other deep learning libraries installed. If you're planning to train a lot of deep learning models with big data, definitely arrange for cloud instances with CUDA-compatible GPUs, which are currently available from Amazon and Azure and will soon be available from Google.
-- Martin Heller
Databricks
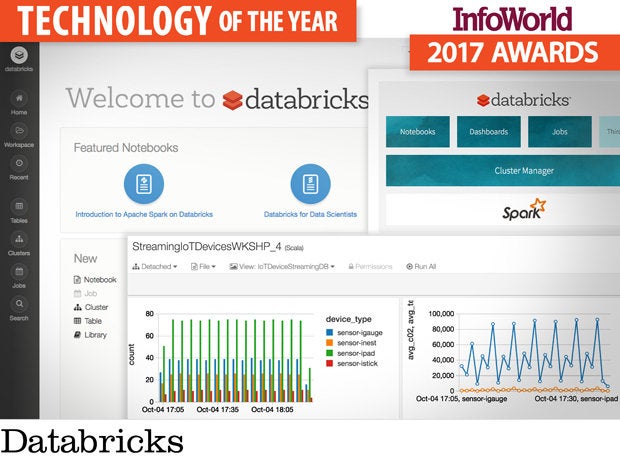
Databricks, the current home of the developers of Apache Spark, offers Spark as a service (running on top of Amazon Web Services) along with a cluster manager, a Jupyter-notebook-compatible interface, dashboards, and jobs. It has a full assortment of ingestion, feature selection, model building, and evaluation functions, plus great integration with data sources and excellent scalability.
While installing standalone Spark is relatively simple, installing Hadoop clusters is a bit more complicated and requires substantial hardware. Using Databricks eliminates any need to deal with hardware or to install Hadoop or Spark or a cluster manager.
Spark's MLlib library provides common machine learning algorithms such as classification, regression, clustering, and collaborative filtering (but not deep neural networks). There are tools for feature extraction, transformation, dimensionality reduction, and selection, as well as tools for constructing, evaluating, and tuning machine learning pipelines. Spark MLlib also includes utilities for saving and loading algorithms, models, and pipelines, for data handling, and for doing linear algebra and statistics.
MLlib has full APIs for Scala and Java, mostly full APIs for Python, and sketchy partial APIs for R. A free Databricks Community cluster gives you one node with 6GB of RAM and 0.88 core. Paid clusters can be as large as your budget allows. You can create clusters at will on Databricks using any Spark version from 1.3 to the current version (2.1.0 as of this writing).
-- Martin Heller
Apache Spark
If you are writing code that needs to distribute processing over a large cluster and want it to be fast and in-memory -- Spark is how we do that now. If you’re capturing streams of events and you want a simple API to handle them, especially if you have to do something with them as they come in -- Spark is now the industry default. All of this happened virtually overnight.
Spark is changing the big data world faster than the Hadoop vendors can redraw their platform diagrams. The project saw not one but two major releases in 2016: 1.6 and 2.0. Both brought major performance improvements and major new features across the board (SQL, streaming, machine learning, and graph processing), but particularly in streaming. If you have been waiting for Spark to be “ready for production,” you no longer have any excuses. Spark is ready for your workload, and it’s a pleasure to use.
-- Andrew C. Oliver

Nvidia CUDA
If 2016 was the year of deep learning, it was also the year of Nvidia CUDA. You're probably aware of graphical processing units (GPUs), which originally served to accelerate 3D games on personal computers. General-purpose computing on graphics processing units (GPGPU) is the use of GPUs for nongraphic programming, most often scientific computations involving large matrices and basic linear algebra.
The GPGPU field started in 2001 and started to matter in the mid-2000s. Today GPGPUs are found in most of the fastest computers in the world. Heterogeneous computing, mostly using Nvidia's graphics processing units (GPU) as co-processors to Intel or AMD CPUs, is a popular choice to reach a better performance-per-watt ratio and higher absolute performance.
While there are several open, vendor-neutral standards for high-performance GPGPU computing, such as OpenCL, OpenACC, and OpenHMPP, the dominant framework in this space is Nvidia's proprietary CUDA platform and API, which support Nvidia GPUs from the G8x series onward. CUDA -- for Compute Unified Device Architecture -- has seen wide adoption in computational biology, cryptography, and other fields, where it often provides an order of magnitude of acceleration over CPU-only calculations.
Most telling this year, CUDA support is present in all the major neural networking and deep learning packages, and all the major cloud vendors have announced or released compute instance types that include Nvidia GPUs. One Nvidia K80 board (holding two GPUs) is enough to speed many deep learning model trainings by a factor of 10, and the P100 boards about to become generally available are even faster.
-- Martin Heller

Amazon EC2 P2 instances
While traditional machine learning methods are still widely used, many have embraced deep learning techniques as a superior alternative. Deep learning chains together processing units that either transform input or extract features, where each layer of the chain takes the output of the previous layer. These chains can be arbitrarily long and in some cases the data can flow through parts or all of the chain more than once.
The nature of this computation -- executing the same program on many data elements in parallel -- happens to be the kind of processing that GPUs were designed for, which is why so many deep learning libraries support GPU optimization out of the box. To address the growing demand for this processing, Amazon released the new P2 instance type last fall.
Packed with up to 16 Nvidia Tesla GK210 GPUs, Amazon EC2 P2 instances make short work of training deep neural networks on convenient, on-demand infrastructure. If a single 16-GPU machine isn’t enough, Amazon allows you to create clusters of P2 instances, with 10 or 20 Gigabit networking between machines. Along with the P2 instance type, Amazon released a new deep learning AMI that comes prebaked with a handful of GPU-optimized libraries and frameworks so that you can jump right in. P2 instances are currently available in US East, US West, EU, and GovCloud (US).
-- Jonathan Freeman
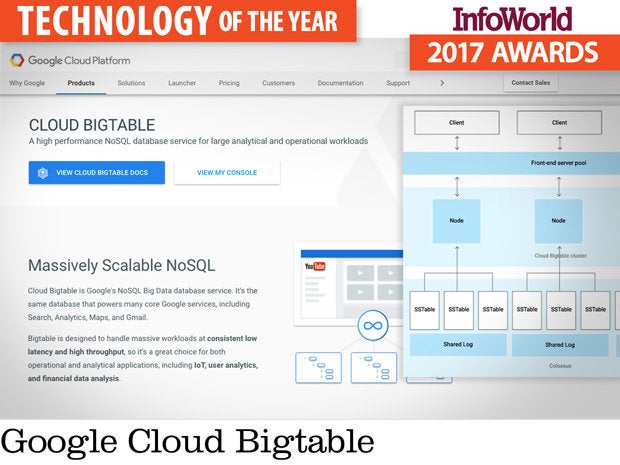
Google Cloud Bigtable
Sometimes "big data" really means big data, as in hundreds of petabytes or even exabytes. When you get to that scale, most cloud database services can't keep up.
Amazon Aurora, one of the most scalable cloud relational databases, caps out at 64 terabytes. Amazon Redshift, the second-most scalable cloud NoSQL database, tops out at around a petabyte of compressed data and only handles that much data with hard disk storage.
To handle hundreds of petabytes or more, you either need to run your own mammoth HBase, Cassandra, or Accumulo clusters, none of which are easy or cheap to build, install, or manage; or (drumroll) use Google Cloud Bigtable.
Cloud Bigtable is a public, highly scalable, column-oriented NoSQL database as a service that uses the very same code as Google’s internal version, which Google invented in the early 2000s and published a paper about in 2006. Bigtable was and is the underlying database for many widely used Google services, including Search, Analytics, Maps, and Gmail. The Bigtable paper was the inspiration for Apache HBase, Apache Cassandra, and Apache Accumulo.
Cloud Bigtable is priced at 65 cents per node per hour (minimum three nodes), plus 17 cents per gigabyte per month (SSD), and network egress. For 30 Bigtable nodes (probably the low end for performance purposes) with SSD storage and a petabyte of data, that adds up to roughly $185,000 per month. It's cheap considering 30 nodes should give you 300,000 queries per second and 6.6GB-per-second scans at a latency of 6 milliseconds on that petabyte of data.
-- Martin Heller

DeepSQL
The fundamentals of relational database engine data structures were established in the 1970s. B-trees are more or less read-optimized, and log-structured merge-trees are more or less write-optimized. The most popular relational database, MySQL, uses as its default engine InnoDB, which relies on B-trees for its indexes. Amazon Aurora, which featured in last year's Technology of the Year awards, is an extremely well-tuned implementation of MySQL running on great infrastructure.
Now, 40 years after B-trees, Tom Hazel of Deep Information Sciences has come up with something better. Essentially, DeepSQL's continuous adapting sequential summarization of information (CASSI) uses machine learning algorithms to maintain optimized in-memory dynamic data structures and optimized resource scheduling; meanwhile, the on-disk physical database is append-only. The result is as near as you can get to the theoretical minimum disk seek costs of 0 for writes and 1 for reads.
The proof of the pudding is that DeepSQL can outperform Amazon Aurora for hybrid transactional and analytic loads by factors between two and 10 for very large databases, as demonstrated by two benchmarks I supervised. As a bonus, DeepSQL needs no hand-tuning, it can run on-premises or in any cloud, and it is free for development and test purposes.
-- Martin Heller
Redis
This open source, in-memory, disk-backed, NoSQL data store wears many hats. Redis is not only an application acceleration cache, but a versatile “data structure server” capable of supporting a vast range of possible applications. It can even add a performance boost to big data frameworks like Spark. The ability of Redis to meet the diverse needs of a broad audience of users is a big part of its appeal.
In May 2016, Redis unveiled details of a long-awaited new feature intended to make Redis even more multipurpose: Redis Modules, which allow developers to bring new data structures and functionality to Redis via an API. Although the API is still a work in progress, modules for Redis have already started showing up to provide valuable real-world functions, including full-text search, image processing, and machine learning.
Modules open up possibilities far beyond the traditional method of extending Redis, Lua scripts, which can only add functionality to Redis’ existing data types. And because modules are written in C, they run at true Redis speed.
-- Serdar Yegulalp
Visual Studio Code
The last couple of years have been something of a renaissance for the classic programmer’s editor. Built on GitHub’s Electron HTML5 framework, Microsoft’s Visual Studio Code was fast, lightweight, and cross-platform from the start, and it quickly became a popular tool for JavaScript and TypeScript development. Then in 2016 Microsoft added an extensibility framework that allows developers to bring in features and language support. The result was hundreds of extensions, supporting every major programming language, in a matter of months.
One of the most popular downloads makes VS Code a powerful tool for building applications in Google’s Go language. Other add-ons have brought in key-mapping for Emacs or Vim and debuggers for languages like Python and PHP, not to mention C, C++, and C#. There’s also the ability to link it to external tools and services, letting you build VS Code into your continuous development and continuous integration pipelines.
VS Code may not have the full GUI of the full Visual Studio IDE, but it exposes its configuration features via a built-in command line palette, as well as JSON configuration files. Themes can change the look and feel, and plugins can take advantage of Microsoft’s IntelliSense code-completion tools and VS Code’s built-in code snippet support to speed up development. Using Electron’s HTML5 development environment also means that Microsoft can deliver Visual Studio Code for MacOS and Linux as well as Windows. The project is open source, with source code on GitHub, and very active, with Microsoft releasing new versions on a monthly basis.
-- Simon Bisson
Rust
The little language that could has grown into the big language that can and does. Ten years in, Rust has risen to become the credible alternative to C and C++ it was always meant to be, a language for writing low-level, performant code that's also safe by default. Rust popped out a slew of new releases over 2016 that did everything from speed up compilation and runtimes and provide better error messages to stabilize the core libraries of the language.
But what happened around the language was even more important. Fedora added Rust as a supported language in that distribution, and Rust originators Mozilla stepped up to help out with a project that helps devs port C code to Rust. This last is regarded as a crucial step in rewriting legacy infrastructure code in Rust for security and stability. That won't happen overnight -- legacy software projects are notoriously hidebound -- but the momentum behind Rust seems to overcome any challenge.
-- Serdar Yegulalp

React Native
The challenges of native mobile development are well known: Programmers are expensive, apps take longer to build, cross-platform errors are legion, and maintenance is costly. But you’ll be hard pressed to achieve smooth 60fps animations or anything like a native feel using Apache Cordova’s WebViews. If you really want to cure the mobile UI blues, try Facebook’s open source framework, React Native.
With React Native, you build declarative UIs using JavaScript and React, the web UI library also from Facebook. React Native bridges JavaScript and underlying platform APIs with direct Java or Objective-C calls that spawn native iOS or Android UI components on the device. The resulting views look native and feel native because they are native. Plus, the framework exposes interfaces to communicate directly with device peripherals such as a camera and geolocation services.
React Native supports hot reloading, so code updates are available without recompiling the whole application. You can still use native modules too; React Native works side by side with your own Java, Objective-C, and Swift components.
The past year brought maturity to merge conflict resolution during framework updates, thanks to Git. And the new Yarn package manager simplifies app dependency tracking.
React Native reduces the layers of complexity in mobile development to deliver fluid, native experiences without the dependency overhead and expense of platform-native development.
-- James R. Borck
GraphQL
For web app developers, efficient data management is the best defense against application latency. GraphQL is a new query language for fetching data that outpaces existing paradigms.
With GraphQL, you combine multiple data sources and embedded dependencies into a unified JSON graph object, which is fetched from a single API endpoint. You get only the data you need, in exactly the format you need, to satisfy a particular view. The result is a scalable data-fetching mechanism that simplifies development, conserves bandwidth, and delivers all-around more efficiency than the REST approach of assembling responses from multiple endpoints.
Open-sourced from Facebook, GraphQL has fast become a go-to tool for app developers due to its robust type validation, metadata introspection for query development, and agnostic stance toward back-end data sources. There’s growing community support, too -- including third-party tools like GraphCool for AWS Lambda and the GraphQL clients and server development tools from Apollo Data.
With GraphQL, much of the complexity of developing data-driven applications gets resolved server-side, where schema relationships between data sources are premapped. The good news is that standing up a GraphQL endpoint is far from laborious. Given the clear performance advantages and predictable schema responses GraphQL yields, it’s easily worth the effort.
-- James R. Borck
MongoDB Atlas
After years of building up the database and ancillary tooling, MongoDB Inc. has finally stepped into the world of database as a service with MongoDB Atlas. Released last summer, MongoDB Atlas brings an entirely managed platform to users through a simple web interface. In a matter of minutes, anyone can provision a highly available sharded replica set on AWS infrastructure, complete with configurable instance sizing and storage volume encryption.
Given a selection from the current list of four AWS regions, Atlas will distribute your replicas (three, five, or seven) across three availability zones to maximize uptime. Once the cluster is provisioned, you can take advantage of the monitoring and alerting tools available through Atlas. Alerts look for user-specified conditions on a plethora of metrics available. When those conditions are met, Atlas can send an email or SMS directly, or it can send messages through other integrations like Slack or PagerDuty.
The UI for MongoDB Atlas is simple and elegant, making it leaps and bounds more friendly than provisioning AWS infrastructure yourself, not to mention all the configuration and clustering best practices built into the service. While the service is still young and growing, it’s definitely worth a look when you consider it’s maintained by the creators of the database and generally costs between half and a quarter of what competitors charge for comparable clusters.
-- Jonathan Freeman

Docker
Docker lets you easily package, ship, and run lightweight “virtual machines” called containers. Did you catch those quotes around “virtual machines”? Yes, something is very different here. Unlike “traditional” virtualization technologies like VMware, Docker doesn’t emulate hardware or encapsulate a whole machine, but relies instead on OS-level virtualization. The difference in terms of portability and overhead is like feathers versus 35-pound dumbbells.
Docker is three powerful old concepts wrapped into one. First is the concept of container virtualization that we know from BSD Jails and Solaris Zones. Second is basic packaging with a kind of inheritance. Third is the concept of repositories. None of these is new, but Docker put them together in a powerful synergy. And it didn’t stop there.
One might prefer Linux, but to totally run the market Docker had to support Windows. It did that. OS-level virtualization is great, but to run real infrastructure you need some kind of clustering support. Enter Docker’s Swarm feature. Most of all, unlike most virtualization technologies, Docker doesn’t make developers want to throw their laptops across the room. Developers actually like Docker. In the end that may matter most of all.
-- Andrew C. Oliver
Kubernetes
Kubernetes has had a great year. The open source container cluster manager has seen considerable development in the past 12 months, improving its support for Amazon Web Services, Microsoft Azure, and other cloud platforms. But the real story of Kubernetes in 2016 was its impressive momentum toward becoming the cluster manager of choice for startups and, increasingly, the enterprise.
As we enter 2017, the Google-backed project now has support for stateful applications, hybrid cloud deployments, and alternative container technologies such as CoreOS Rkt (though Docker support, of course, is still king). The project also gained the support of a growing number of software vendors and cloud operators, which have embraced Kubernetes as a key component of their management systems.
Ebay rolled its own Kubernetes tool, TessMaster, to manage containers inside OpenStack. Mirantis adopted Kubernetes to manage OpenStack as a slew of containers. CoreOS unveiled Operators, a system for general app management with Kubernetes. VMware integrated Kubernetes into its Photon Platform, and Kubernetes forms the core of Red Hat’s OpenShift platform. Kubernetes is integrated into VMware's Photon Platform, and it forms the core of Red Hat's OpenShift PaaS. Kubernetes has even added Windows support, with the ability to orchestrate both Hyper-V Containers and Windows Server Containers.
Expect 2017 to see Kubernetes go from strength to strength, likely starting to encroach on OpenStack installations across the world. If you're a sys admin or a devops engineer and you haven't dived in yet, you better do so now. Last year's "what's that?" technology is this year's "why aren't you?" tech. You don't want to get left behind!
-- Ian Pointer and Serdar Yegulalp
Nano Server
Building applications for the cloud requires a different mode of thinking, focusing on scalable microservices and new avenues of deploying those services. One of the key technologies driving this shift is containerization, which combines the virtualization of userland with a method of wrapping up applications and services for quick, easy deployment. In order to get the biggest benefit from containers, you’ll need a lightweight operating system with a minimal set of services.
That’s where Windows Server 2016 Nano Server comes into play. This new Windows Server installation option provides a much thinner, easier-to-maintain OS you can use to host Windows Server containers, Hyper-V Containers, or apps built on the open source .Net Core. There’s no GUI and no local logon. Management is done only via APIs and a Nano Server-specific version of PowerShell, with gigabytes of the familiar Windows Server comforts removed to support working at scale with automated server deployments.
The result is a server that boots almost instantaneously, deploys nearly as fast, and reduces storage requirements, attack surface, and maintenance footprint dramatically. Further, Nano Server can be used as the core for both virtual infrastructure and for containers. It may not quite be a unikernel OS, but it’s likely to be a lot more flexible and much more closely related to Windows Server.
-- Simon Bisson
HashiCorp Consul
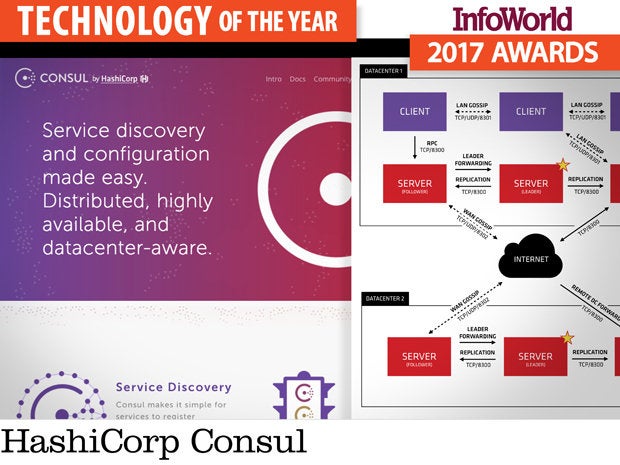
Consul is a tool for service discovery, monitoring, and configuration. These systems have been around since the 1980s (anyone remember Genera’s namespaces?), but they are even more important today with the rise of distributed systems, where processes need to coordinate with one another.
ZooKeeper was the first attempt to create a coordination service for distributed applications, and Consul and ZooKeeper share a similar architecture of server nodes that require a quorum of nodes to operate. ZooKeeper works perfectly well, but exposes only key-value semantics, so each distributed application needs to build its own service discovery and coordination layer on top of ZooKeeper. For developers, that’s one more element they would rather not have to worry about.
By contrast, Consul supports many common patterns out of the box. For example, native support for multiple datacenters, integrated health checks, and access control are all built in. Registered services and nodes can be queried using both a DNS interface and HTTP, reducing development time for the coordination parts of distributed applications.
Consul is open source and comes with surprisingly good documentation for an open source project. Support is available from HashiCorp.
-- Steven Nunez

HashiCorp Vault
The internet is not a safe place for storing sensitive information. Most software was written without security in mind, and building in robust security after the fact is not easy. Vault helps developers write more secure applications by providing a tool for securely accessing sensitive information.
Vault protects sensitive information in transit and at rest, and it provides multiple authentication and audit logging mechanisms. Dynamic secret generation allows Vault to avoid providing clients with root privileges to underlying systems and makes it possible to do key rolling and revocation. Vault can also encrypt data without storing it, so security teams can hold the keys and developers can store encrypted data any way they like.
There is much overlap in security solutions today. Some solutions, like Kerberos, are mature and well proven, but have high implementation overhead. Other solutions, like AWS Identity and Access Management, offer a piece of the puzzle by protecting scripts, but not much else. Vault combines a bit of everything an enterprise might need in a high-quality solution that is simple to implement. It is a generally practical approach to giving developers what they need to build more secure applications.
-- Steven Nunez
SourceClear
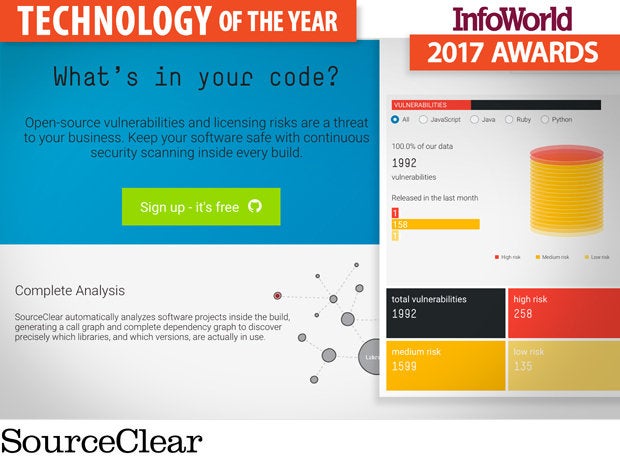
For all of us to get better, safer applications, developers must get security tools that fit into the application development workflow and integrate with the tools they are already using. Developers don’t always realize exactly how many libraries get pulled into a given software project or even how those components were included. For example, a Node.js application might easily have more than 350 dependencies, most of which aren’t explicitly included, so it's all but impossible for the developers to stay on top of the latest vulnerability announcements and version updates.
SourceClear tackles the app dev security challenge with a cloud platform that scans software projects and details which open source libraries and frameworks are in use, how they're used, whether those components include vulnerable code, and the kinds of vulnerabilities they include. The company released a community edition of its platform in May 2016, called SourceClear Open, and added major integrations with JIRA, Bitbucket, and GitHub, so it's easier for developers to track security issues in their code. SourceClear’s Dependency Visualizer helps developers discover which open source libraries are in use, which have vulnerabilities, and which are available in safer versions. Developers can also see potential licensing conflicts.
It’s one matter to rail about insecure code. Until developers have practical solutions, application security will remain literally an afterthought. SourceClear is providing tools to help developers detect security issues in the libraries they’re using and fix them before they become security catastrophes.
-- Fahmida Y. Rashid
OSquery
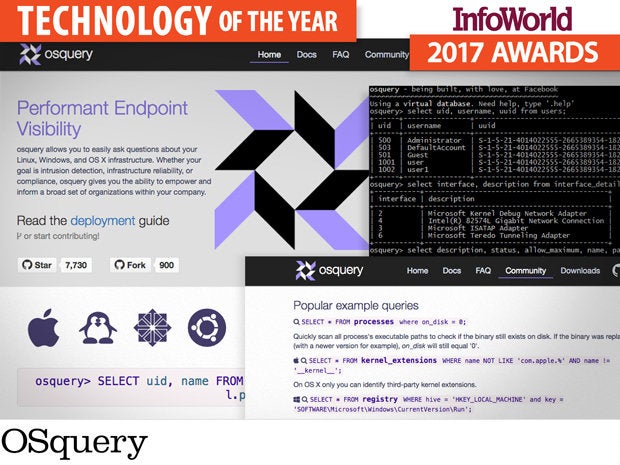
Imagine if the files, processes, and events in your entire network of Windows, MacOS, and Linux endpoints were recorded in a database in real time. Finding malicious processes, software vulnerabilities, and other evil artifacts would be as easy as asking the database. That’s the power of OSquery, a Facebook open source project that makes sifting through system and process information to uncover security issues as simple as writing a SQL query.
Facebook ported OSquery to Windows in 2016, finally letting administrators use the powerful open source endpoint security tool on all three major platforms. On each Linux, MacOS, and Windows system, OSquery creates various tables containing operating system information such as running processes, loaded kernel modules, open network connections, browser plugins, hardware events, and file hashes. When administrators need answers, they can ask the infrastructure.
The query language is SQL-like. For example, the following query will return malicious processes kicked off by malware that has deleted itself from disk:
SELECT name, path, pid FROM processes WHERE on_disk = 0;
This ability has been available to Linux and MacOS administrators since 2014 —Windows administrators are only now coming to the table.
Porting OSquery from Linux to Windows was no easy feat. Some creative engineering was needed to overcome certain technical challenges, such as reimplementing the processes table so that existing Windows Management Instrumentation (WMI) functionality could be used to retrieve the list of running processes. (Trail of Bits, a security consultancy that worked on the project, shares the details in its blog.)
Administrators don’t need to rely on complicated manual steps to perform incident response, diagnose systems operations problems, and handle security maintenance for Windows systems. With OSquery, it’s all in the database.
-- Fahmida Y. Rashid

MazeRunner
Cymmetria’s cyberdeception platform MazeRunner acknowledges the harsh reality faced by many security professionals: If the attackers want to get in, they will. Cyberdeception accepts intrusion as a fact and neutralizes attackers by peppering the network with “bread crumbs” of credentials, as well as other juicy tidbits of information to deter attackers from real assets and lead them into decoy virtual machines, where they are isolated and profiled.
These decoy machines run real operating systems and real services, but allow you to study your attacker, learn their tools and techniques, and use that information to detect and prevent future attacks. The approach is similar to, but more intensive than, running honeypots.
The goal is to make it more time-consuming and costlier for attackers to move around the network, but easier for defenders to identify and analyze threats. After all, with decoys, there’s no such thing as a false positive. If an attacker reaches the deception host, the attack is fingerprinted and the signatures of the attack generated and distributed to defenders.
Bad guys will find a way into networks no matter how many firewalls or antimalware tools you deploy, so why not lure them astray? If attackers learn to fear that the next tool or command they try to run may lead to a host designed to trap them, then we truly will have begun to turn the tables.
-- Fahmida Y. Rashid
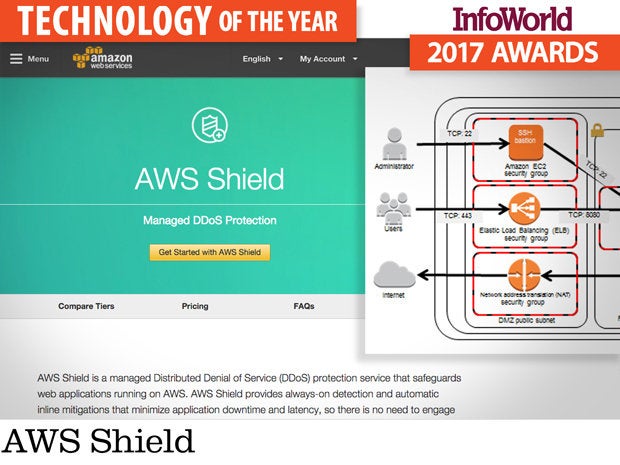
AWS Shield
Amazon could not have picked a more fortuitous time to unveil AWS Shield, a managed service aimed at helping Amazon’s customers mitigate DDoS attacks against the Amazon Web Services infrastructure. Coming mere days after a massive DDoS attack against DNS provider Dyn rendered portions of the internet inaccessible, the arrival of AWS Shield addressed the question staring IT teams in the face: How to bridge the security gap with cloud providers?
Until AWS Shield, the only practical way to mitigate DDoS attacks against AWS infrastructure was to put some other platform in front of AWS, such as Cloudflare, to detect and filter out malicious traffic. While it’s possible to autoscale servers to absorb the attack traffic, that will result in an astronomical bill at the end of the month, and failing over to a different server or provider adds complexity to the overall infrastructure.
AWS Shield works in conjunction with Elastic Load Balancers, Amazon CloudFront, and Amazon Route 53 to make systems running in AWS more resilient against DDoS attacks. Available to all customers, the service protects web applications against volumetric attacks, reflection attacks, state-exhaustion attacks, and application layer attacks. The “pro” version, AWS Shield Advanced, provides additional mitigation capabilities and attack detection intelligence.
Considering that DDoS attacks have been increasing exponentially in size, it’s surprising that all cloud providers don’t offer native DDoS mitigation tools. Your turn, Google and Microsoft.
-- Fahmida Y. Rashid

Apache Spot
Apache Hadoop solved the problem of collecting large volumes of data from a variety of sources, and Apache Spark provided an in-memory data analytics framework, but for information security analysts, there was still a piece missing from the big data puzzle: a way to process the massive volumes of machine data that represent network traffic flows and separate the good traffic from the bad. That’s where Apache Spot comes in.
Instead of relying on backward-looking rules and signatures to identify security threats, Spot applies advanced analytics techniques to detect anomalous network traffic and zero in on new and complex attacks. For example, Spot can use machine learning as a filter to distinguish bad traffic from benign, as well as to characterize network traffic behavior. Spot can also use context enrichment, noise filtering, white listing, and heuristics to generate a shortlist of likely security threats.
Apache Spot is based on Intel and Cloudera’s earlier Open Network Insight project but has been extended to include additional capabilities such as support for DNS and proxy server logs (NetFlow was already supported). The common open data models for network, endpoint, and user data provide standard formats for enriched event data that make it easier to integrate cross-application data. The data model also makes it easier for organizations to share analytics, as well as encourages application developers to contribute new security analytics capabilities so that everyone else can benefit.
-- Fahmida Y. Rashid

Confluent Platform
Messaging systems are new again, except now our real-time data streams are more aptly described as real-time firehoses. Apache Kafka offers a high-throughput, low-latency messaging backbone, but its lack of enterprise features can make for heavy lifting.
The Confluent Platform -- built on Kafka and available in free open source and enterprise editions -- fills in the gaps, providing a more complete framework and tools for taming Kafka data streams.
No-code configuration lets you wizard your way to wiring up stream sources and incorporate essential enterprise features like high-capacity fault tolerance. Built-in analytics, monitoring, and alerts make quick work of surfacing meaningful insights with verifiable audit trails.
To Kafka’s Java client, Confluent brings additional Python and C/C++ support, prebuilt connectors for HDFS and JDBC, its own REST proxy, and a schema registry that incorporates version control and metadata introspection capabilities.
Most impressive, the Confluent Control Center replaces Kafka’s basic throughput monitoring with deep performance metrics and messaging state feedback via its browser-based dashboard. And unlike native Kafka, Confluent transparently realigns asynchronous operations and missequenced timestamps to reveal delivery failures and latency problems anywhere along the pipeline.
Even more bells and whistles are available from the Confluent Enterprise edition, including load rebalancing, cluster management, and tech support.
Kafka is good for simple messaging. More advanced operations like stream joins and aggregations demand something more. For debugging, monitoring, and performance optimization over real-time streams, Confluent Platform provides that something more.
-- James R. Borck

Lucidworks Fusion
Apache Solr is something of a hidden gem in the big data ecosystem, but has developed a reputation for being difficult to set up and operate. Enter Lucidworks Fusion. Fusion not only makes administering your Solr clusters a breeze, but includes connectors to a vast myriad of data sources. Throw in out-of-the-box connectivity with Apache Spark and the ability to build data ingestion and query pipelines, and you have a great option of extending search to all areas of your enterprise.
The past year has brought many improvements to Fusion, including connectors for IBM's Watson AI service, deeper integration of Apache Spark into the platform, and improved handling of time-series data, along with oft-required enterprise features like pluggable SAML authentication.
While Apache Solr's ornery side may be a little overstated these days, Lucidworks Fusion effortlessly brings out the potential of an existing or new Solr installation, allowing you to reap the benefits of Solr's ability to query billions of documents in less than a second with fewer operational hassles.
-- Ian Pointer
Elastic Stack
Log analytics is big. Day and night, servers churn out gigabyte upon gigabyte of unstructured text, and companies now keep everything that would have gone to /dev/null only a few years ago. The challenge: How do you find the needle in these large and ever growing haystacks?
The Elastic Stack -- Elasticsearch, Logstash, and Kibana -- is the immensely popular open source stack designed to do exactly that. Highly scalable, with excellent search capabilities, the Elastic Stack is how large-scale operators like Netflix, Verizon, and Salesforce do log analytics.
Although log analytics tools have long been popular in the information security domain for years, they are rapidly being adopted elsewhere, especially in cloud ops and IoT. With the ability to capture and search data from thousands of sources, Elastic is the perfect toolkit for analyzing large clouds of systems or devices. And the steady accumulation of connectors (for system-level statistics, network traffic data, Windows events) and plugins (for monitoring, alerting, reporting, user management) is making Elastic an easier fit in the enterprise.
Elastic and Splunk are the biggest enterprise grade solutions in this space. Three years ago, Elastic wasn’t even on the map; today, many companies are migrating, largely because of the pay-per-byte model of Splunk. There is no denying that Splunk is more polished and richer in features, but Elastic has most of what a typical user needs. If you are willing to invest a bit of time in tailoring it to your needs, Elastic may be the right solution.
-- Steven Nunez
MapR-FS
If you’ve deployed anything substantive on HDFS, you know it's a bit of an oddball technology: A distributed filesystem written in Java that bottlenecks everything through a few “Namenodes.” Although the raw block performance isn’t bad after you’ve tuned the hell out of HDFS and the VMs that run it, the Namenode never seems to get out of the way. Oh, and if you have a fault ... well, recovering HDFS isn’t like recovering most filesystems.
Enter MapR-FS. It isn’t open source, but it is purely native code and follows proven distributed filesystem design principles. This means less locking and better failover and recovery. MapR-FS is API compatible with HDFS, so you can use it in your existing Hadoop application.
In the end, it would be nice to see an open source distributed filesystem at the core of the new distributed computing universe. However, after so many production deployments, it is becoming pretty clear that HDFS isn’t really up to the task. If you need a better, reliable, recoverable, distributed filesystem now -- you should look at MapR-FS instead.
-- Andrew C. Oliver
Let’s Encrypt
All web traffic should be encrypted by default. Let’s Encrypt is on a mission to make that happen.
Built by the nonprofit Internet Security Research Group (ISRG, involving Mozilla Foundation and University of Michigan), Let’s Encrypt is a free certificate authority that replaces cost and complexity with open and automated mechanisms for issuing domain-validated SHA-2 certificates. If you own a domain name, you can get a trusted certificate from Let’s Encrypt absolutely free of charge.
The certificate request and renewal process is automated through Certbot, an Automated Certificate Management Environment (ACME) client from the Electronic Frontier Foundation. Other clients are available, including Bash scripts, C, Java, PHP, and Perl, as well as manual procurement -- but the 90-day expiration on Let’s Encrypt certificates strongly encourages the use of an automated tool.
Let’s Encrypt piggybacks on IdenTrust’s DST Root X3 authority, ensuring that its cross-signed certificates validate in most modern browsers. Although Let’s Encrypt has been active for little more than a year, it is already one of the largest certificate authorities around.
Let’s Encrypt doesn’t address all needs. It doesn’t provide organization validation (OV) or extended validation (EV) certs or wild card support. Further, Subject Alternative Names are limited to 100 per certificate, although this should be practical for most mainstream uses.
HTTPS offers an essential safeguard to shield traffic from nefarious snooping. Let’s Encrypt finally makes this protection an easy and affordable proposition.
-- James R. Borck

Windows 10 Anniversary Update
Face it: Most IT organizations follow Microsoft’s lead when it comes to management and deployment. So it’s a big deal that Microsoft has delivered omnidevice management in Windows 10 Anniversary Update (version 1607) and subsequent Windows Information Protection update, adopting the core approaches that Apple invented several years ago for mobile devices and bringing them to desktops, laptops, two-in-ones, tabtops, and all of the other variations of the PC that are emerging. The move will ultimately end the false dichotomy between mobile device and computer, thus giving IT more consistent, assured control and security as a result.
Windows 10’s omnidevice management is a work in progress, like all management and security tools, but the core is now in place for IT organizations to begin testing and deploying as they bring in Windows 10 devices. Even better, although Microsoft hopes you’ll use its own management tools, the new omnidevice management capabilities are largely supported in the enterprise mobile management (EMM) tools you likely already have.
Honorable mention: MobileIron Bridge, which allows the use of existing group policy objects for retaining legacy management rules in the new omnidevice approach.
-- Galen Gruman
Dashlane
"Style" isn’t a word typically associated with password management, but Dashlane is the exception. Dashlane has wrapped everything you would expect from a password manager, along with a few surprises, in a better user experience. The browser and mobile integrations are solid and clean, providing a simple UI to fill in passwords or create new ones. Passwords are stored locally and encrypted, with optional device syncing if you purchase a premium subscription for less than $40 each year.
Dashlane goes above and beyond simple recall and generation of passwords. On certain sites, it will automatically log in instead of providing an interactive prompt to fill out information, saving even more clicks. Dashlane’s security dashboard not only assesses the strength of each password, but tells you if the password is getting old or has been reused.
In addition to passwords, you can save other personal information in Dashlane to fill out forms automatically. Dashlane nicely handles online payments by saving and recalling credit cards, bank account details, and PayPal accounts. Once you have your payment methods saved in Dashlane, it will even save receipts of your payments, making it easier to track your past purchases. The free version of Dashlane is more than enough in most cases, and it means you can download and try it out before putting down any cash.
-- Jonathan Freeman

AWS Server Migration Service
As pervasive as cloud computing has become, many companies remain skeptical or stymied as to how to get started. Even for those of us who know exactly which servers we want to migrate, the road to getting there isn’t always smooth or clear.
Leave it to Amazon to pave that road. The AWS Server Migration Service, which makes use of a downloadable connector that helps streamline the server migration process, is both free and easy.
Rather than deploying agents on each running server, as you do for Azure Site Recovery, Amazon’s Server Migration Connector installs a FreeBSD appliance that functions as a gateway between your local VMware environment and the Amazon cloud.
The Server Migration Connector sniffs out existing server volumes and network topology through a fairly wizard-driven process. It captures basic server inventory and volume snapshots, then works in the background to replicate volumes as Amazon Machine Images in Amazon EC2.
Good dashboards offer insight into migration status and the health of each server as it is migrated. Once the migration is complete, you simply spin up the new volumes as EC2 instances from your AWS Management Console.
Replications of live VMs save bandwidth by pushing incremental updates, and they can be automated through an onboard scheduler. All considered, the AWS Server Migration Service not only simplifies server migration but serves as a reliable business continuity and disaster recovery model as well.
AWS Server Migration Service currently supports only the VMware hypervisor and VMotion, but expanded coverage for KVM and Hyper-V can’t be far behind. AWS Server Migration Service is a smoothly integrated approach that minimizes downtime and disruption and represents a marked improvement from the basic options currently available in the EC2 VM import function.
-- James R. Borck
Copyright © 2017 IDG Communications, Inc.
