






Today more and more companies are taking a personalized approach to content and marketing. For example, retailers are personalizing product recommendations and promotions for customers. An important step toward providing personalized recommendations is to identify a customer’s propensity to take action for a certain category. This propensity is based on a customer’s preferences and past behaviors, and it can be used to personalize marketing (e.g., more relevant email campaigns, ads, and website banners).
At Amazon, the retail systems team created a multi-label classification model in MXNet to understand customer action propensity across thousands of product categories, and we use these propensities to create a personalized experience for our customers. In this post, we will describe the key challenges we faced while building these propensity models and how we solved them at the Amazon scale with Apache Spark using the Deep Java Library (DJL). DJL is an open source library to build and deploy deep learning in Java.
Challenges
A key challenge was building a production system that can grow to Amazon-scale and is easy to maintain. We found that Apache Spark helped us scale within the desired runtime. For the machine learning (ML) framework for building our models, we found that MXNet scales to fulfill our data requirement for hundreds of millions of records and gave us better execution time and model accuracy compared to other available machine learning frameworks.
Our team consists of a mix of software development engineers and research scientists. Our engineering team wanted to build a production system using Apache Spark in Java/Scala, whereas scientists preferred to use Python frameworks. This posed another challenge while deciding between Java and Python-based systems. We looked for ways where both teams could work together in their preferred programming language and found that we could use DJL with MXNet to solve this problem. Now, scientists build models using the MXNet – Python API and share their model artifacts with the engineering team. The engineering team uses DJL to run inference on the model provided using Apache Spark with Scala. Since DJL is machine learning framework-agnostic, the engineering team doesn’t need to make code changes in the future if the scientists want to migrate their model to a different ML framework (e.g., PyTorch or TensorFlow).
Data
To train the classification model, we need two sets of data: features and labels.
Feature data
To build any machine learning model, one of the most important inputs is the feature data. One benefit of using multi-label classification is that we can have a single pipeline to generate feature data. This pipeline captures signals from multiple categories and uses that single dataset to find customer propensity for each category. This reduces operational overhead because we only need to maintain a single multi-label classification model rather than multiple binary classification models.
For our multi-label classification, we generated high-dimensional feature data. We created hundreds of thousands of features per customer for hundreds of millions of customers. These customer features are sparse in nature and can be represented in sparse vector representation:
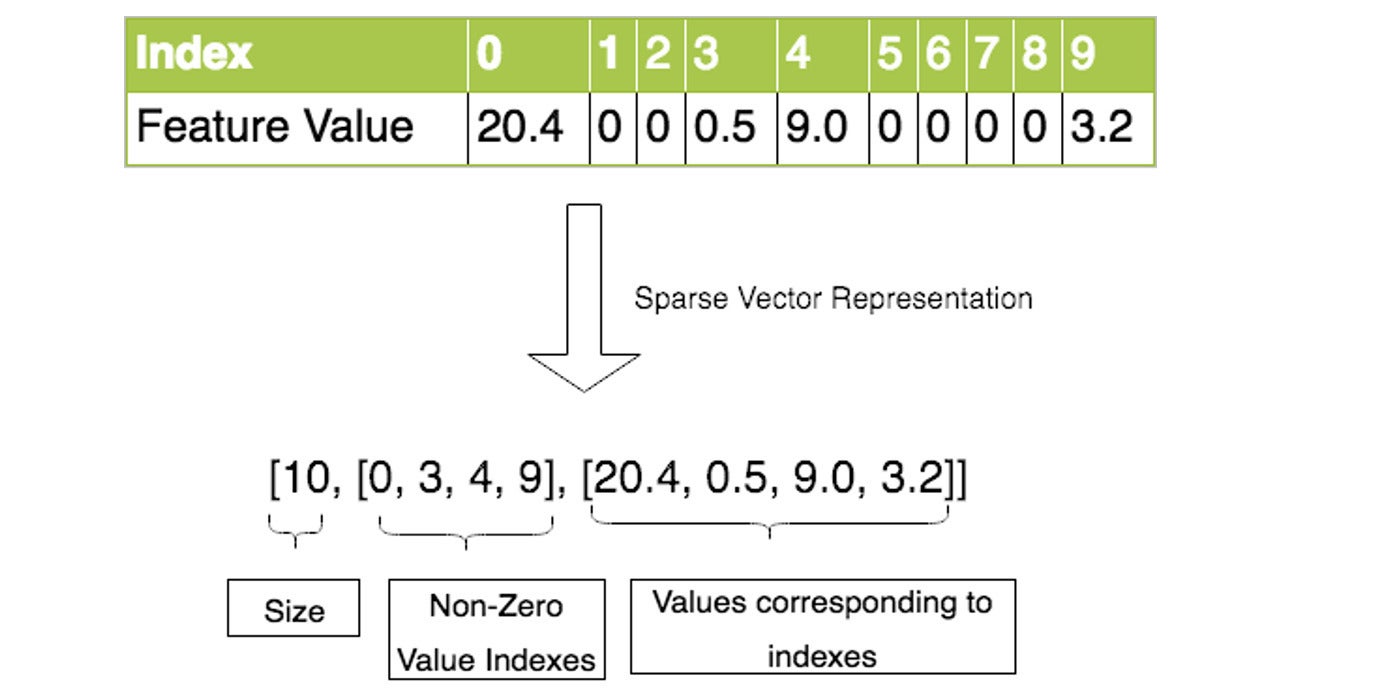 AWS
AWSLabel data
A propensity model predicts the likelihood of a given customer taking action in a particular category. For each region, we have thousands of categories that we want to generate customer propensities for. Each label has a binary value: 1 if the customer made the required action in a given category, 0 otherwise. These labels of past behavior are used to predict the propensity of a customer taking the same action in a given category in the future. The following is an example of the initial label represented as the one-hot encoding for four categories:
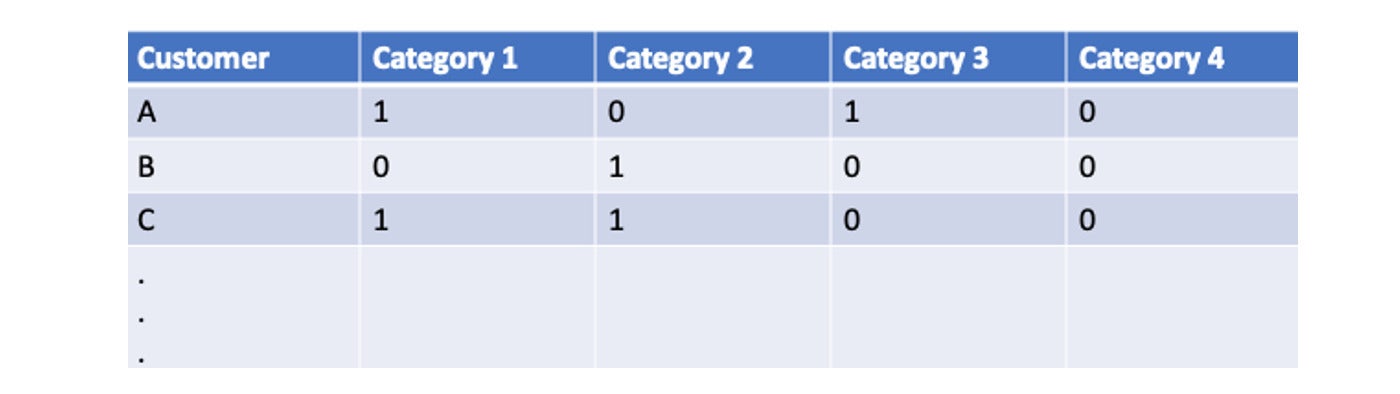 AWS
AWSIn this example, customer A only took actions in category 1 and category 3 in the past, whereas customer B only took actions in category 2.
Model architecture
The propensity model is implemented in MXNet using the Python API, is a feed-forward network consisting of a sparse input layer, hidden layers, and N output layers where N is the number of categories we are interested in. Although the output layers can be easily represented by logistics regression output, we chose to implement the network using softmax output to allow flexibility in training models with more than two classes. The following is a high-level diagram of a network with four target output:
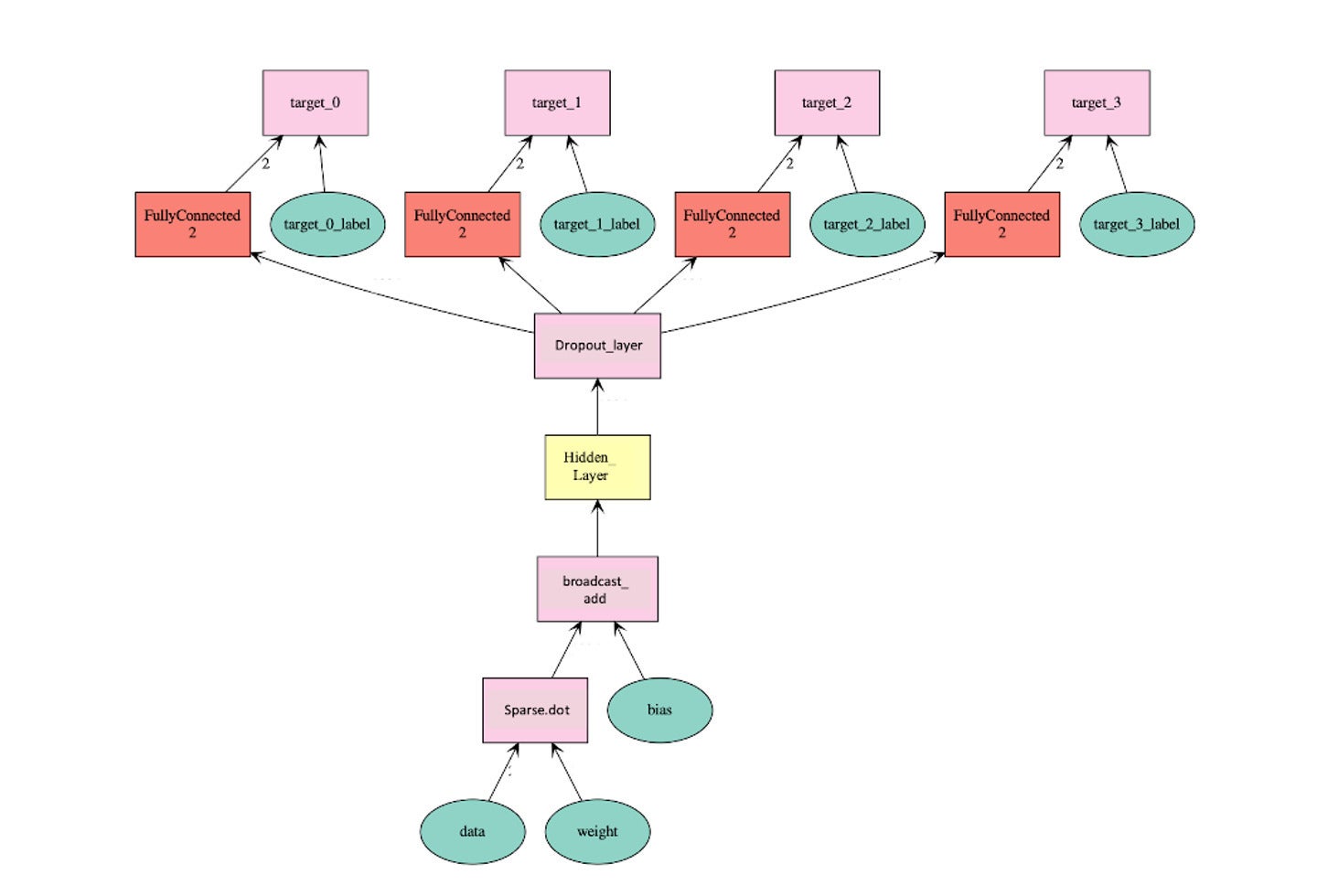 AWS
AWSBelow is the pseudocode for the network architecture:
 AWS
AWSModel training
To train the model, we wrote a custom iterator to process the sparse data and convert it to MXNet arrays. In each iteration, we read in a batch of data consisting of customerIds, labels, and sparse features. We then constructed a sparse MXNet CSR matrix to encode the features by specifying the non-zero values, non-zero indices, index pointers as well as the shape of the CSR matrix. In the following example, we construct the sparse MXNet CSR matrix with batch size = 3 and feature size = 5.
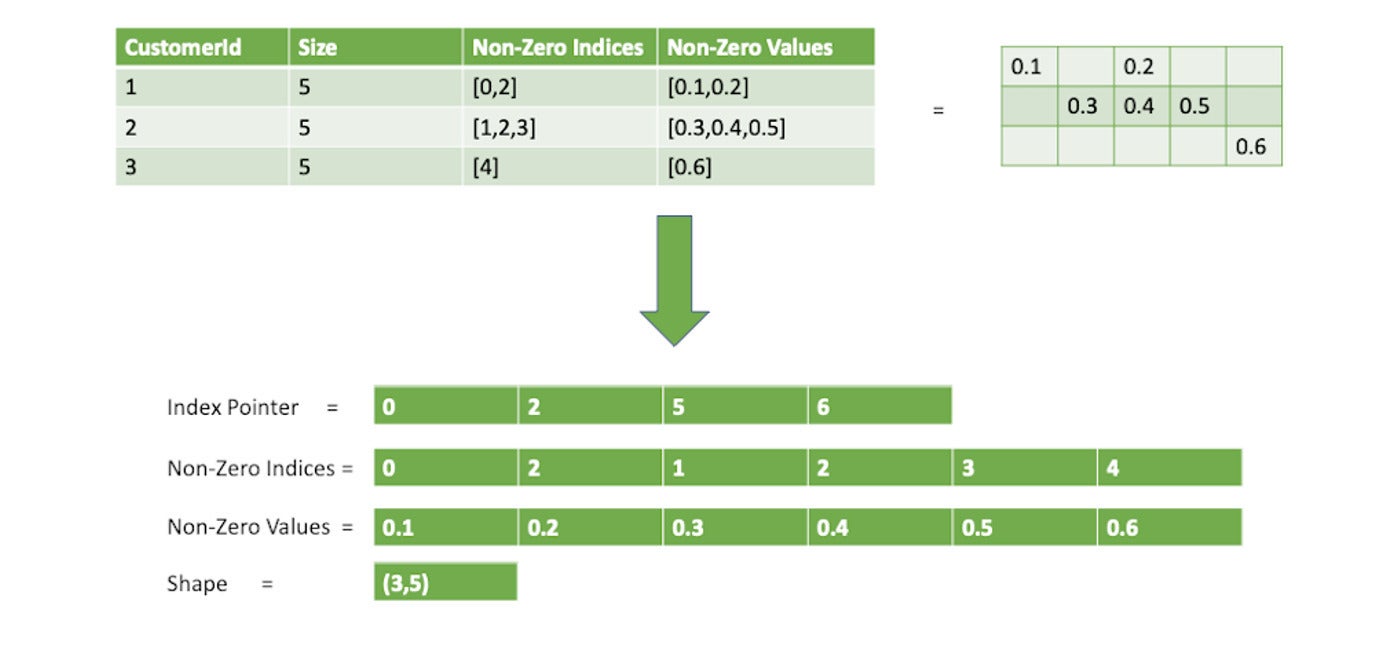 AWS
AWSThe label feeding into the MXNet module is a list of MXNet NDArray. Each element in the list represents a target category. Thus the i’th element in the label list represents the training labels of the batch for category i. This is a 2-D array where the first dimension is the label for product category i and the second dimension is the complement of that label. The following is an example with batch size = 3 and number of categories = 4.
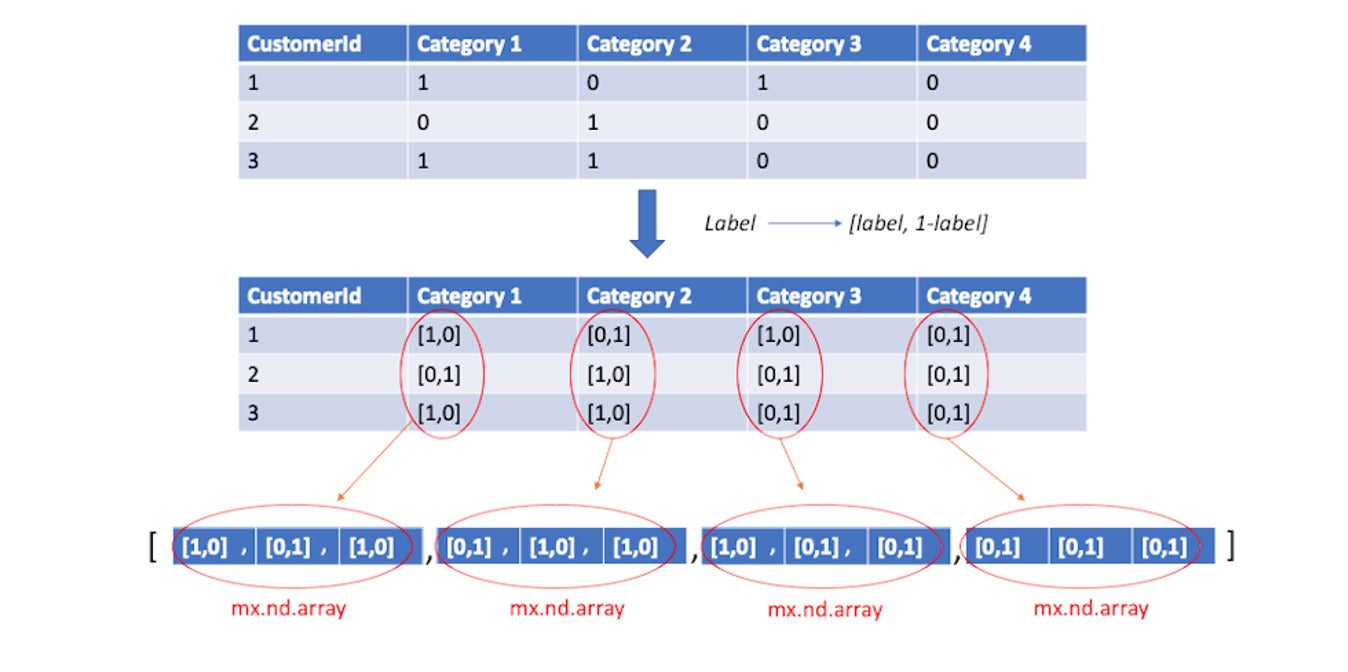 AWS
AWSWe then passed the features and labels as an MXNet DataBatch to be used in training. We used the multi-label log-loss metric to train the neural network.
Inference and performance
As mentioned previously, model training was done using Apache MXNet Python APIs while inference is done in Apache Spark with Scala as the programming language. Because DJL provides Java APIs, it can be easily integrated into a Scala application.
Setup
To include DJL libraries into the project, we included below DJL dependencies.
 AWS
AWSInference
DJL internally works on NDList and provides a Translator interface to convert the custom input data type to NDList; it also converts output NDList to the custom output data type. DJL supports sparse data in the form of CSR data and allows scoring a batch of data.
First, we loaded the model artifacts.
 AWS
AWSWe defined Translator to convert the input feature vector to NDList containing CSR data and convert output predictions of type NDList to Array[Array[Float]].
 AWS
AWSAbove Translator is used to define Predictor object, which is used to generate predictions.
 AWS
AWSFinal data was generated by combining the above predictions with the category names and customerId.
 AWS
AWSPerformance
Before DJL, running predictions with this model and such high-dimensional data used to take around 24 hours and had multiple memory issues. DJL reduced the prediction time on this model by 85%, from around one day to a couple of hours. DJL worked out of the box without spending any time on engineering tasks, such as memory tuning. In contrast, prior to DJL, we spent more than two weeks in memory tuning.
More about DJL
Deep Java Library (DJL) is an open source library to build and deploy deep learning in Java. This project launched in December 2019 and is widely used among teams at Amazon. This effort was inspired by other DL frameworks, but was developed from the ground up to better suit Java development practices. DJL is framework agnostic, with support for Apache MXNet, PyTorch, TensorFlow 2.x (experimental), and fastText (experimental). Additionally, DJL offers a repository of pre-trained models in our ModelZoo that simplifies implementation and streamlines model sharing across projects.
Key advantages of using DJL
Ease of integration and deployment. With DJL, you integrate ML in your applications natively in Java. Because DJL runs in the same JVM process as other Java applications, you don’t need to manage (or pay for) a separate model serving service or container. We have customers who have integrated DJL easily into existing Spark applications written in Scala, eliminating the need to write an additional Scala wrapper on top of a deep learning framework.
Highly performant. DJL offers microseconds of latency by eliminating the need for a gPRC or web service calls. DJL also leverages multi-threading in inference to further improve latency and throughput. Users can leverage DJL with Spark for large scale DL applications.
Framework Agnostic. DJL provides unified and Java-friendly API regardless of the frameworks you use—MXNet, TensorFlow, or PyTorch. True to its Java roots, you can write your code once in DJL and run it with a framework of your choice. You also have the flexibility to access low-level framework specific features.
To learn more about DJL, check the website, Github repository, and Slack channel.