While machine learning and deep learning models often produce good classifications and predictions, they are almost never perfect. Models almost always have some percentage of false positive and false negative predictions. That’s sometimes acceptable, but matters a lot when the stakes are high. For example, a drone weapons system that falsely identifies a school as a terrorist base could inadvertently kill innocent children and teachers unless a human operator overrides the decision to attack.
The operator needs to know why the AI classified the school as a target and the uncertainties of the decision before allowing or overriding the attack. There have certainly been cases where terrorists used schools, hospitals, and religious centers as bases for missile attacks. Was this school one of those? Is there intelligence or a recent observation that identifies the school as currently occupied by such terrorists? Are there reports or observations that establish that no students or teachers are present in the school?
If there are no such explanations, the model is essentially a black box, and that’s a huge problem. For any AI decision that has an impact — not only a life and death impact, but also a financial impact or a regulatory impact — it is important to be able to clarify what factors went into the model’s decision.
What is explainable AI?
Explainable AI (XAI), also called interpretable AI, refers to machine learning and deep learning methods that can explain their decisions in a way that humans can understand. The hope is that XAI will eventually become just as accurate as black-box models.
Explainability can be ante-hoc (directly interpretable white-box models) or post-hoc (techniques to explain a previously trained model or its prediction). Ante-hoc models include explainable neural networks (xNNs), explainable boosting machines (EBMs), supersparse linear integer models (SLIMs), reversed time attention model (RETAIN), and Bayesian deep learning (BDL).
Post-hoc explainability methods include local interpretable model-agnostic explanations (LIME) as well as local and global visualizations of model predictions such as accumulated local effect (ALE) plots, one-dimensional and two-dimensional partial dependence plots (PDPs), individual conditional expectation (ICE) plots, and decision tree surrogate models.
How explainable AI algorithms work
If you followed all the links above and read the papers, more power to you – and feel free to skip this section. The write-ups below are short summaries. The first five are ante-hoc models, and the rest are post-hoc methods.
Explainable neural networks
Explainable neural networks (xNNs) are based on additive index models, which can approximate complex functions. The elements of these models are called projection indexes and ridge functions. The xNNs are neural networks designed to learn additive index models, with subnetworks that learn the ridge functions. The first hidden layer uses linear activation functions, while the subnetworks typically consist of multiple fully-connected layers and use nonlinear activation functions.
xNNs can be used by themselves as explainable predictive models built directly from data. They can also be used as surrogate models to explain other nonparametric models, such as tree-based methods and feedforward neural networks. The 2018 paper on xNNs comes from Wells Fargo.
Explainable boosting machine
As I mentioned when I reviewed Azure AI and Machine Learning, Microsoft has released the InterpretML package as open source and has incorporated it into an Explanation dashboard in Azure Machine Learning. Among its many features, InterpretML has a “glassbox” model from Microsoft Research called the explainable boosting machine (EBM).
EBM was designed to be as accurate as random forest and boosted trees while also being easy to interpret. It’s a generalized additive model, with some refinements. EBM learns each feature function using modern machine learning techniques such as bagging and gradient boosting. The boosting procedure is restricted to train on one feature at a time in round-robin fashion using a very low learning rate so that feature order does not matter. It can also detect and include pairwise interaction terms. The implementation, in C++ and Python, is parallelizable.
Supersparse linear integer model
Supersparse linear integer model (SLIM) is an integer programming problem that optimizes direct measures of accuracy (the 0-1 loss) and sparsity (the l0-seminorm) while restricting coefficients to a small set of coprime integers. SLIM can create data-driven scoring systems, which are useful in medical screening.
Reverse time attention model
The reverse time attention (RETAIN) model is an interpretable predictive model for electronic health records (EHR) data. RETAIN achieves high accuracy while remaining clinically interpretable. It’s based on a two-level neural attention model that detects influential past visits and significant clinical variables within those visits (e.g. key diagnoses). RETAIN mimics physician practice by attending the EHR data in a reverse time order so that recent clinical visits are likely to receive higher attention. The test data discussed in the RETAIN paper predicted heart failure based on diagnoses and medications over time.
Bayesian deep learning
Bayesian deep learning (BDL) offers principled uncertainty estimates from deep learning architectures. Basically, BDL helps to remedy the issue that most deep learning models can’t model their uncertainty by modeling an ensemble of networks with weights drawn from a learned probability distribution. BDL typically only doubles the number of parameters.
Local interpretable model-agnostic explanations
Local interpretable model-agnostic explanations (LIME) is a post-hoc technique to explain the predictions of any machine learning classifier by perturbing the features of an input and examining the predictions. The key intuition behind LIME is that it is much easier to approximate a black-box model by a simple model locally (in the neighborhood of the prediction we want to explain), as opposed to trying to approximate a model globally. It applies both to the text and image domains. The LIME Python package is on PyPI with source on GitHub. It’s also included in InterpretML.
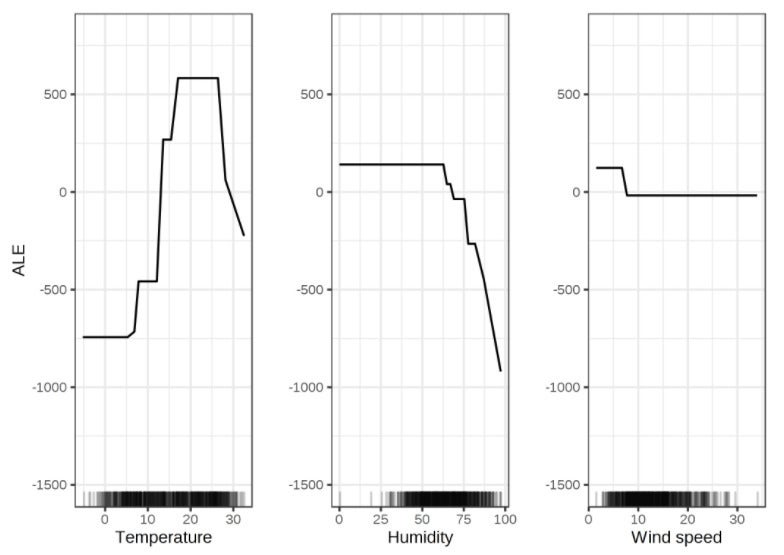{kind=link}
ALE plots for bicycle rentals. From Interpretable Machine Learning by Christoph Molnar.
Accumulated local effects
Accumulated local effects (ALE) describe how features influence the prediction of a machine learning model on average, using the differences caused by local perturbations within intervals. ALE plots are a faster and unbiased alternative to partial dependence plots (PDPs). PDPs have a serious problem when the features are correlated. ALE plots are available in R and in Python.
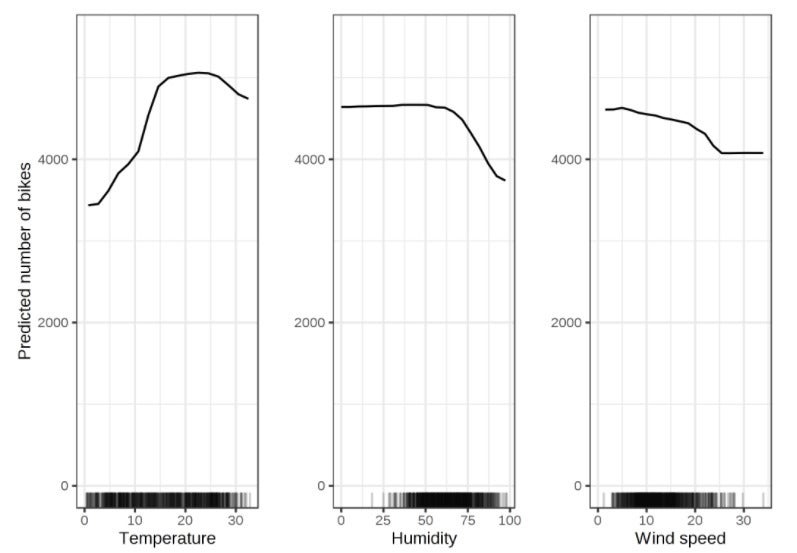{kind=link}
PDP plots for bicycle rentals. From Interpretable Machine Learning by Christoph Molnar.
Partial dependence plots
A partial dependence plot (PDP or PD plot) shows the marginal effect one or two features have on the predicted outcome of a machine learning model, using an average over the dataset. It’s easier to understand PDPs than ALEs, although ALEs are often preferable in practice. The PDP and ALE for a given feature often look similar. PDP plots in R are available in the iml, pdp, and DALEX packages; in Python, they are included in Scikit-learn and PDPbox.
{kind=link}
ICE plots for bicycle rentals. From Interpretable Machine Learning by Christoph Molnar. CC
Individual conditional expectation plots
Individual conditional expectation (ICE) plots display one line per instance that shows how the instance’s prediction changes when a feature changes. Essentially, a PDP is the average of the lines of an ICE plot. Individual conditional expectation curves are even more intuitive to understand than partial dependence plots. ICE plots in R are available in the iml, ICEbox, and pdp packages; in Python, they are available in Scikit-learn.
Surrogate models
A global surrogate model is an interpretable model that is trained to approximate the predictions of a black box model. Linear models and decision tree models are common choices for global surrogates.
To create a surrogate model, you basically train it against dataset features and the black box model predictions. You can evaluate the surrogate against the black box model by looking at the R-squared between them. If the surrogate is acceptable, then you can use it for interpretation.
Explainable AI at DARPA
DARPA, the Defense Advanced Research Projects Agency, has an active program on explainable artificial intelligence managed by Dr. Matt Turek. From the program’s website (emphasis mine):
The Explainable AI (XAI) program aims to create a suite of machine learning techniques that:
- Produce more explainable models, while maintaining a high level of learning performance (prediction accuracy); and
- Enable human users to understand, appropriately trust, and effectively manage the emerging generation of artificially intelligent partners.
New machine-learning systems will have the ability to explain their rationale, characterize their strengths and weaknesses, and convey an understanding of how they will behave in the future. The strategy for achieving that goal is to develop new or modified machine-learning techniques that will produce more explainable models. These models will be combined with state-of-the-art human-computer interface techniques capable of translating models into understandable and useful explanation dialogues for the end user. Our strategy is to pursue a variety of techniques in order to generate a portfolio of methods that will provide future developers with a range of design options covering the performance-versus-explainability trade space.
Google Cloud’s Explainable AI
The Google Cloud Platform offers Explainable AI tools and frameworks that work with its AutoML Tables and AI Platform services. These tools help you to understand feature attributions and visually investigate model behavior using the What-If Tool.
{kind=link}
Feature attribution overlays from a Google image classification model.
AI Explanations give you a score that explains how each factor contributed to the final result of the model predictions. The What-If Tool lets you investigate model performances for a range of features in your dataset, optimization strategies, and even manipulations to individual datapoint values.
Continuous evaluation lets you sample the prediction from trained machine learning models deployed to AI Platform and provide ground truth labels for prediction inputs using the continuous evaluation capability. The Data Labeling Service compares model predictions with ground truth labels to help you improve model performance.
Whenever you request a prediction on AI Platform, AI Explanations tells you how much each feature in the data contributed to the predicted result.
H2O.ai’s machine learning interpretability
H2O Driverless AI does explainable AI with its machine learning interpretability (MLI) module. This capability in H2O Driverless AI employs a combination of techniques and methodologies such as LIME, Shapley, surrogate decision trees, and partial dependence in an interactive dashboard to explain the results of both Driverless AI models and external models.
In addition, the auto documentation (AutoDoc) capability of Driverless AI provides transparency and an audit trail for Driverless AI models by generating a single document with all relevant data analysis, modeling, and explanatory results. This document helps data scientists save time in documenting the model, and it can be given to a business person or even model validators to increase understanding and trust in Driverless AI models.
DataRobot’s human-interpretable models
DataRobot, which I reviewed in December 2020, includes several components that result in highly human-interpretable models:
- Model Blueprint gives insight into the preprocessing steps that each model uses to arrive at its outcomes, helping you justify the models you build with DataRobot and explain those models to regulatory agencies if needed.
- Prediction Explanations show the top variables that impact the model’s outcome for each record, allowing you to explain exactly why your model came to its conclusions.
- The Feature Fit chart compares predicted and actual values and orders them based on importance, allowing you to evaluate the fit of a model for each individual feature.
- The Feature Effects chart exposes which features are most impactful to the model and how changes in the values of each feature affect the model’s outcomes.
DataRobot works to ensure that models are highly interpretable, minimizing model risk and making it easy for any enterprise to comply with regulations and best practices.
Dataiku’s interpretability techniques
Dataiku provides a collection of various interpretability techniques to better understand and explain machine learning model behavior, including:
- Global feature importance: Which features are most important and what are their contributions to the model?
- Partial dependence plots: Across a single feature’s values, what is the model’s dependence on that feature?
- Subpopulation analysis: Do model interactions or biases exist?
- Individual prediction explanations (SHAP, ICE): What is each feature’s contribution to a prediction for an individual observation?
- Interactive decision trees for tree-based models: What are the splits and probabilities leading to a prediction?
- Model assertions: Do the model’s predictions meet subject matter expert intuitions on known and edge cases?
- Machine learning diagnostics: Is my methodology sound, or are there underlying problems like data leakage, overfitting, or target imbalance?
- What-if analysis: Given a set of inputs, what will the model predict, why, and how sensitive is the model to changing input values?
- Model fairness analysis: Is the model biased for or against sensitive groups or attributes?
Explainable AI is finally starting to receive the attention it deserves. We aren’t quite at the point where “glassbox” models are always preferred over black box models, but we’re getting close. To fill the gap, we have a variety of post-hoc techniques for explaining black box models.