Bossie Awards 2017: The best databases and analytics tools
InfoWorld picks the best open source software for large-scale search, SQL, NoSQL, and streaming analytics
















The best open source databases and data analytics tools
We’ve watched a parade of NoSQL databases march through the Bossies the last few years. Well, SQL has had enough! Our 2017 winners include two examples of scale-out SQL databases, along with the usual gang of analytics-oriented projects from the Apache Software Foundation, a name that has become synonymous with big data.
[ InfoWorld presents the Best of Open Source Software Awards 2017: The best open source software development tools. | The best open source machine learning tools. | The best open source cloud computing software. | The best open source networking and security software. ]

CockroachDB
CockroachDB is a cloud-native SQL database for building global, scalable cloud services that survive disasters. Built on a transactional and strongly consistent key-value store, CockroachDB scales horizontally, survives disk, machine, rack, and even datacenter failures with minimal latency disruption and no manual intervention, supports strongly consistent ACID transactions, and provides a familiar SQL API for structuring, manipulating, and querying data. CockroachDB was inspired by Google’s Spanner and F1 technologies.
— Martin Heller

MapD
MapD is a GPU-powered in-memory database and visualization platform designed for lightning-fast, immersive data exploration that eliminates the disconnect between analyst and data. By bringing the power of GPU supercomputing to data analytics, MapD can query and visualize billions of records in milliseconds. The MapD Core database takes advantage of the parallelism of GPUs with a state-of-the-art query compilation engine to achieve orders-of-magnitude speedups for analytic SQL queries, powering exploration of big datasets with near zero latency.
— Martin Heller

CrateDB
CrateDB is a distributed SQL database built on top of a NoSQL foundation. It combines the familiarity of SQL with the scalability and data flexibility of NoSQL. CrateDB provides packages and executables that will work on any operating systems capable of running Java including Linux, MacOS, and Windows. Typical use cases for CrateDB are IoT and sensor data, log and event analytics, time series, geospatial search, and machine learning.
— Martin Heller

Greenplum
Greenplum is a MPP (massively parallel processing) SQL database with 100-percent ANSI SQL compliance. Greenplum offers machine learning, an advanced parallel query engine, and a highly scalable distributed architecture. Previously a proprietary solution, Greenplum became an Apache project in 2015. The first open source release arrived in September 2017.
— Steven Nunez

Apache Spark
Apache Spark is still on fire. Version 2.2, released in July, brought a large number of new features to Core (which now includes the SQL query engine), improvements to the Kafka streaming interface, and additional algorithms in MLlib and GraphX. The SparkR library supporting distributed machine learning on R also sees enhancements, especially in the area of SQL integration. And the list of bug fixes and general improvements is long, making this release one of the best yet.
— Steven Nunez

Apache Solr
Built on the Lucene index technology, Apache Solr is the distributed index/document database that could, would, and does. Whether you need a simple index or to handle complex embedded documents, Solr is there for you. Finding things in a mountain of text is obviously Solr’s strength but modern Solr lets you do much more including the ability to execute SQL in a distributed fashion or even execute graph queries. The engine has continued to develop with new ”point” types, which execute numeric queries with better performance and smaller indexes.
— Andrew C. Oliver
Apache Arrow
Apache Arrow is a high-speed, columnar, cross-system data layer that speeds up big data. By storing data in memory using Arrow, applications can skip the costly serialization/deserialization steps that create bottlenecks in today’s data processing pipelines. Involving developers from many Apache Big Data projects—Cassandra, Parquet, Kudu, Spark, and Storm among others—the Apache Arrow project will be processing large chunks of the world’s data in the coming months and years.
— Ian Pointer

Apache Kudu
Apache Kudu is poised to become a major component of big data infrastructure. Kudu is optimized for situations where large amounts of data see frequent updates and where analytics are needed on a timely basis. This has been been a challenge with traditional Apache Hadoop architectures, normally resulting in a complex HDFS and HBase solution that can lead to code and data synchronization issues. Kudu promises better and simpler architectures for IoT, time series, and streaming machine learning processing.
— Ian Pointer

Apache Zeppelin
Apache Zeppelin is a sort of Rosetta Stone for developers, analysts, and data scientists alike. A slew of interpreters allow you to pull from different data stores and analyze in multiple languages. This means you can pull data from your Apache Solr index, cross-reference with your Oracle database, and analyze the results in Spark with code you wrote in Scala. Then your statistician can analyze your DataFrame in R and visualize the results before your data scientist uses a favorite Python library to do some deep learning—all from the same workbook!
— Andrew C. Oliver

R Project
The R programming language should need little introduction. In 2017 we find adoption continuing to grow, with support from Microsoft, Oracle, and IBM as well as several smaller players. CRAN, the Comprehensive R Archive Network, contains nearly every statistical computing algorithm of significance, ready to run, along with sophisticated graphics and a scripting language that makes it easy to save and rerun analyses on updated data sets.
— Steven Nunez
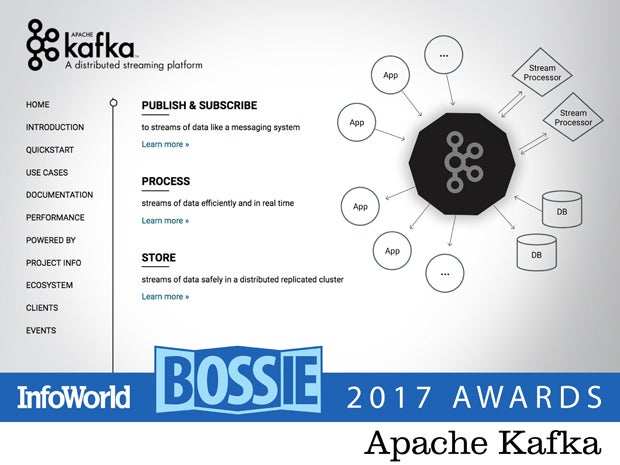
Apache Kafka
Apache Kafka is a distributed streaming platform that is used for building real-time data pipelines and streaming apps. It is horizontally scalable, fault-tolerant, fast, and runs in production in thousands of companies. Kafka lets you publish and subscribe to streams of records, much like a message queue or enterprise messaging system. It lets you store streams of records in a fault-tolerant way, and it lets you process streams of records as they occur.
— Martin Heller

Cruise Control
Apache Kafka is a powerful and stable distributed streaming platform, but it can be a pain to manage. It handles failures in an automated fashion but often leads to unbalanced loads across the system. LinkedIn noticed that its SRE’s spent a ton of time on Kafka resource monitoring and rebalancing, so developed Cruise Control to lighten their burden. It was just open sourced in late August, but is a promising timesaver for anyone running Kafka in production.
— Jonathan Freeman

JanusGraph
JanusGraph is a distributed graph database built on a column family database. Unlike other popular open source graph databases, it supports large graphs and distributed processing natively. JanusGraph has a ton of features, integrates with the likes of Apache Spark and Apache Solr, and supports Apache TinkerPop’s implementation of the Gremlin graph query language. If you have a graph-shaped problem and data that lends itself to a graph structure, JanusGraph has answers.
— Andrew C. Oliver
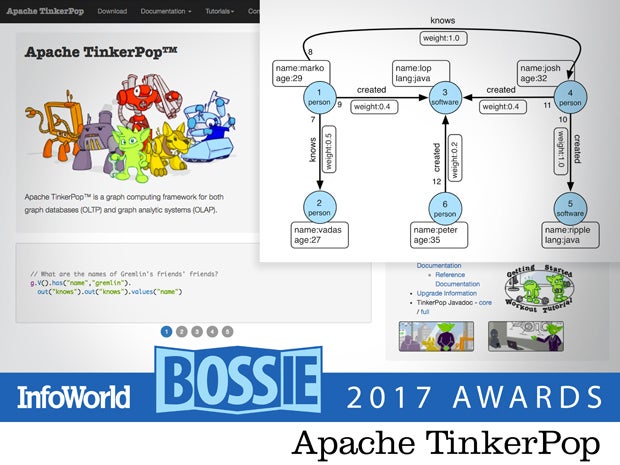
Apache TinkerPop
Powering nearly all of the popular graph processing frameworks including Spark, Neo4j, and Titan, TinkerPop allows users to model their problem domain as a graph and analyze it using a graph traversal language. For some domains, especially those that involve relationships, this technique is very effective. Graph computing is rapidly coming of age, and TinkerPop is leading the way in open source implementations.
— Steven Nunez
Copyright © 2017 IDG Communications, Inc.
